MapReduce实战:邮箱统计及多输出格式实现
紧接着上一篇博文我们学习了MapReduce得到输出格式之后,在这篇博文里,我们将通过一个实战小项目来熟悉一下MultipleOutputs(多输出)格式的用法。
项目需求:
假如这里有一份邮箱数据文件,我们期望统计邮箱出现次数并按照邮箱的类别,将这些邮箱分别输出到不同文件路径下(MultipleOutputs)。数据集示例如下所示。
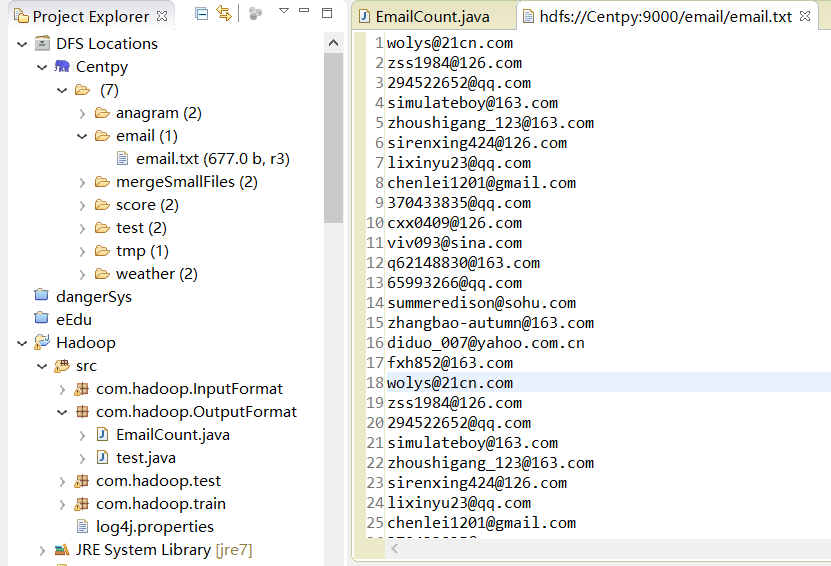
wolys@21cn.com zss1984@126.com 294522652@qq.com simulateboy@163.com zhoushigang_123@163.com sirenxing424@126.com lixinyu23@qq.com chenlei1201@gmail.com 370433835@qq.com cxx0409@126.com viv093@sina.com q62148830@163.com 65993266@qq.com summeredison@sohu.com zhangbao-autumn@163.com diduo_007@yahoo.com.cn fxh852@163.com
下面我们编写 MapReduce 程序,实现上述业务需求。
项目实现:
新建一个EmailCount.java类,在其中编写一下程序
package com.hadoop.OutputFormat; import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner; public class EmailCount extends Configured implements Tool{ public static class MailMapper extends Mapper< LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1); @Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, one);
}
} public static class MailReducer extends Reducer< Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
private MultipleOutputs< Text, IntWritable> multipleOutputs; @Override
protected void setup(Context context) throws IOException ,InterruptedException{
multipleOutputs = new MultipleOutputs< Text, IntWritable>(context);
}
protected void reduce(Text Key, Iterable< IntWritable> Values,Context context) throws IOException, InterruptedException {
//294522652@qq.com
int begin = Key.toString().indexOf("@");
int end = Key.toString().indexOf(".");
if(begin>=end){
return;
}
//获取邮箱类别,比如 qq
String name = Key.toString().substring(begin+1, end);
int sum = 0;
for (IntWritable value : Values) {
sum += value.get();
}
result.set(sum);
multipleOutputs.write(Key, result, name);
}
@Override
protected void cleanup(Context context) throws IOException ,InterruptedException
{
multipleOutputs.close();
}
} @Override
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();// 读取配置文件 Path mypath = new Path(args[1]);
FileSystem hdfs = mypath.getFileSystem(conf);//创建输出路径
if (hdfs.isDirectory(mypath)) {
hdfs.delete(mypath, true);
}
Job job = Job.getInstance();// 新建一个任务
job.setJarByClass(EmailCount.class);// 主类 FileInputFormat.addInputPath(job, new Path(args[0]));// 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));// 输出路径 job.setMapperClass(MailMapper.class);// 设置Mapper类
job.setReducerClass(MailReducer.class);// 设置Reducer类 job.setOutputKeyClass(Text.class);// key输出类型
job.setOutputValueClass(IntWritable.class);// value输出类型 job.waitForCompletion(true);
return 0;
} public static void main(String[] args) throws Exception {
String[] args0 = {
"hdfs://Centpy:9000/email/email.txt",
"hdfs://Centpy:9000/email/outputs/"
};
int ec = ToolRunner.run(new Configuration(), new EmailCount(), args0);
System.exit(ec);
}
}
项目测试:
首先,我们的输入文件如下所示。
将项目文件导出为JAR文件,然后上传到Hadoop集群上。
运行以下指令
hadoop jar EmailCount.jar com.hadoop.OutputFormat.EmailCount /email /email/outputs
项目结果:
项目测试结果如下所示
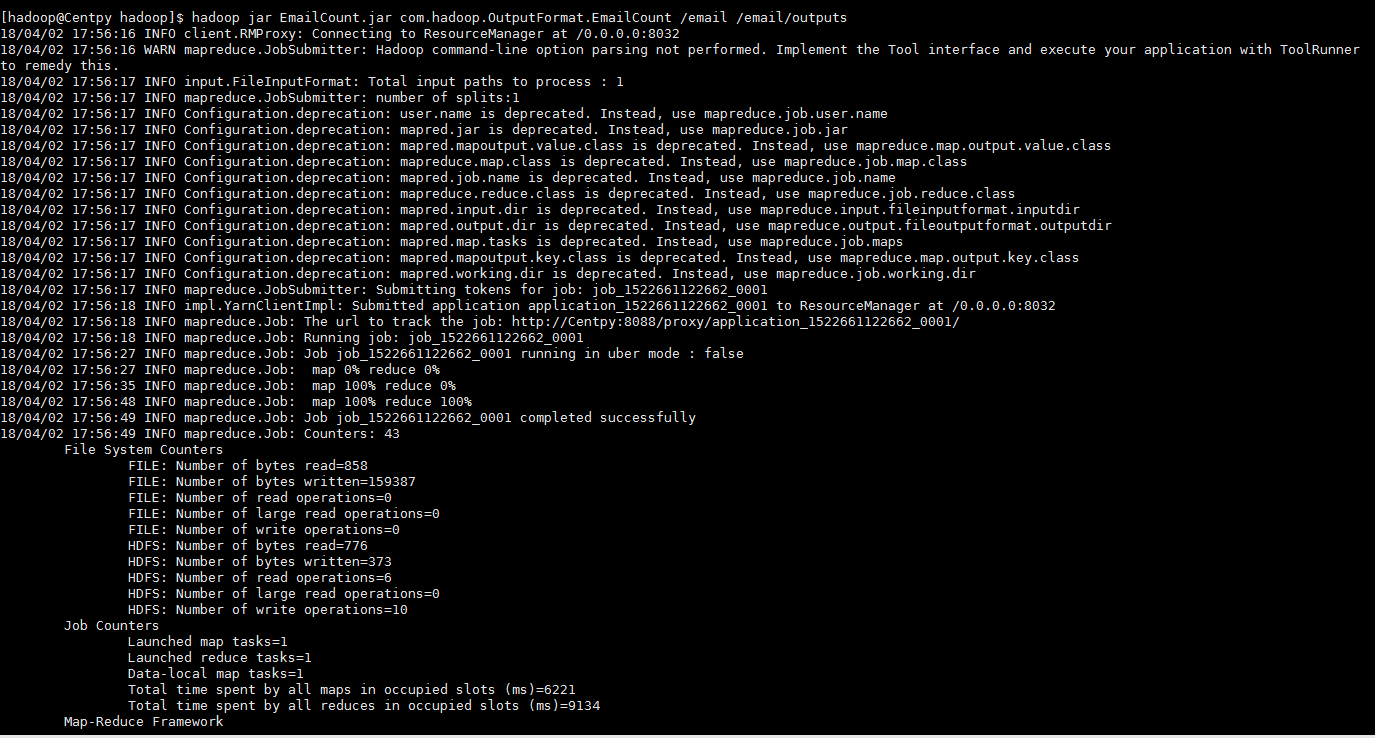
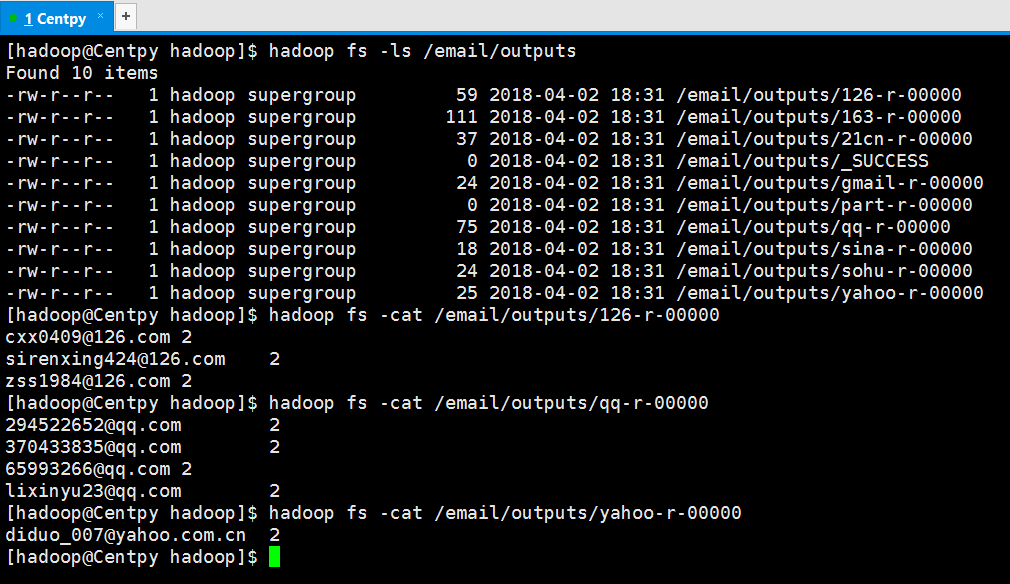
从结果可以看出,我们通过MapReduce成功实现了邮箱统计的MultipleOutputs格式,即将邮箱进行分类,然后每一个类型的邮箱单独存储到一个输出文件中,并在其中显示邮箱的统计次数。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
MapReduce实战:邮箱统计及多输出格式实现的更多相关文章
- MapReduce实战:统计不同工作年限的薪资水平
1.薪资数据集 我们要写一个薪资统计程序,统计数据来自于互联网招聘hadoop岗位的招聘网站,这些数据是按照记录方式存储的,因此非常适合使用 MapReduce 程序来统计. 2.数据格式 我们使用的 ...
- mapreduce实战:统计美国各个气象站30年来的平均气温项目分析
气象数据集 我们要写一个气象数据挖掘的程序.气象数据是通过分布在美国各地区的很多气象传感器每隔一小时进行收集,这些数据是半结构化数据且是按照记录方式存储的,因此非常适合使用 MapReduce 程序来 ...
- MapReduce实战:自定义输入格式实现成绩管理
1. 项目需求 我们取有一份学生五门课程的期末考试成绩数据,现在我们希望统计每个学生的总成绩和平均成绩. 样本数据如下所示,每行数据的数据格式为:学号.姓名.语文成绩.数学成绩.英语成绩.物理成绩.化 ...
- Hadoop实战5:MapReduce编程-WordCount统计单词个数-eclipse-java-windows环境
Hadoop研发在java环境的拓展 一 背景 由于一直使用hadoop streaming形式编写mapreduce程序,所以目前的hadoop程序局限于python语言.下面为了拓展java语言研 ...
- Hadoop实战3:MapReduce编程-WordCount统计单词个数-eclipse-java-ubuntu环境
之前习惯用hadoop streaming环境编写python程序,下面总结编辑java的eclipse环境配置总结,及一个WordCount例子运行. 一 下载eclipse安装包及hadoop插件 ...
- 《OD大数据实战》MapReduce实战
一.github使用手册 1. 我也用github(2)——关联本地工程到github 2. Git错误non-fast-forward后的冲突解决 3. Git中从远程的分支获取最新的版本到本地 4 ...
- MapReduce实战--倒排索引
本文地址:http://www.cnblogs.com/archimedes/p/mapreduce-inverted-index.html,转载请注明源地址. 1.倒排索引简介 倒排索引(Inver ...
- MapReduce实战(三)分区的实现
需求: 在实战(一)的基础 上,实现自定义分组机制.例如根据手机号的不同,分成不同的省份,然后在不同的reduce上面跑,最后生成的结果分别存在不同的文件中. 对流量原始日志进行流量统计,将不同省份的 ...
- MapReduce实战项目:查找相同字母组成的字谜
实战项目:查找相同字母组成的字谜 项目需求:一本英文书籍中包含有成千上万个单词或者短语,现在我们要从中找出相同字母组成的所有单词. 数据集和期望结果举例: 思路分析: 1)在Map阶段,对每个word ...
随机推荐
- Python:正则表达式(三)*、+、?的用法
一.功能*——表示匹配前面的字符0个或多个:+——表示前面的字符1个或多个:?——(1)放在其他字符后面:表示匹配0次或1次: (2)放在*.+后面:表示匹配尽可能少的字符 二.例 字符串fooooo ...
- Python:正则表达式(二)
则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语 ...
- 杂项:Webpack
ylbtech-杂项:Webpack 本质上,webpack 是一个现代 JavaScript 应用程序的静态模块打包器(module bundler).当 webpack 处理应用程序时,它会递归地 ...
- Project Server2016升级安装问题项目中心无法显示
sharepoint 2016升级后,project server 相关中心页面出现空白页面,这是是sharepoint2016一个bug,解决方案用PWA.resx内容替换PWA.en-us.res ...
- HTML input 标签不可编辑的 readonly 属性
1 <form action="form_action.asp" method="get"> Name:<input type="t ...
- ABCD四个人说真话的概率都是1/3。假如A声称B否认C说D是说谎了,那么D说过的那句话真话的概率是多少
ABCD四个人说真话的概率都是1/3.假如A声称B否认C说D是说谎了,那么D说过的那句话 真话的概率是多少 记"A声称B否认C说D说谎"为X,那么由贝叶斯公式,所求的 P(D真)P ...
- [poj3281]Dining(最大流+拆点)
题目大意:有$n$头牛,$f$种食物和$d$种饮料,每种食物或饮料只能供一头牛享用,且每头牛只享用一种食物和一种饮料.每头牛都有自己喜欢的食物种类列表和饮料种类列表,问最多能使几头牛同时享用到自己喜欢 ...
- Angular14 Visual Studio Code作为Angular开发工具常用插件安装、json-server安装与使用、angular/cli安装失败问题、emmet安装
前提准备: 搭建好Angular开发环境 1 安装Visual Studio Code 教程简单,不会的去问度娘 2 安装Chrome浏览器 教程简单,不会的趣闻度娘 3 Visual Studio ...
- 【转】如何在eclipse下配置Heritrix
如何配置在eclipse下配置Heritrix 在其他帖子上看到有Eclipse 配置 Heritrix 1.14.4的文章,这里有很多内容是引用自那里.如http://extjs2.javaeye. ...
- 工作随记——弹出QQ联系方式
<a target="_blank" href="http://wpa.qq.com/msgrd?v=1&uin=QQ号码&site=qq& ...