Hadoop源生实用工具之distcp
1 概览
DistCp(Distributed Copy)是用于大规模集群内部或者集群之间的高性能拷贝工具。 它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成。 它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝
备注:在工作中遇到部门间数据合作,夸不同集群版本或者同版本不同集群的数据copy是不同的。
2 实用
总体来说分两类:
1) 同版本集群间数据copy ;
2) 夸集群版本数据copy;
同版本集群间数据copy
比如:拷贝A集群(nn1的IP192.168.7.120)的A目录到B集群(nn2的IP192.168.8.120)的B1目录
hadoop distcp hdfs://192.168.7.120:8020/cluster/A/ hdfs://192.168.8.120:8020/cluster/B1/
小结:
a) 使用hdfs协议,其中192.168.7.120是A集群的namenode地址, 8020是A集群的rpc端口(hdfs-site.xml中可查看)。192.168.8.120是B集群的namenode IP地址
b) 这条命令会将A集群中的/A文件夹以及文件夹下的文件复制到B集群中的/B1目录下,即在B集群中会以/B1/A的目录结构出现。如果/B1目录不存在,则系统会新建一个。需要注意的是,源路径必须是绝对路径。包含前面的hdfs://ip:port
添加多个数据源,指定多个源目录 如:
hadoop distcp hdfs: //192.168.7.120:8020/cluster/A/a1 hdfs://192.168.7.120:8020/A/a2 hdfs://192.168.8.120:8020/cluster/B1/
或者使用-f选项,从文件里获得多个源:
hadoop distcp -f hdfs://192.168.7.120:8020/src_A_list hdfs://192.168.8.120:8020/cluster/B1/
其中src_A_list 的内容是
hdfs://192.168.7.120:8020/cluster/A/a1
hdfs://192.168.7.120:8020/cluster/A/a2
当从多个源拷贝时,如果两个源冲突,distcp会停止拷贝并提示出错信息, 如果在目的位置发生冲突,会根据选项设置解决。 默认情况会跳过已经存在的目标文件(c处说明;比如不用源文件做替换操作)。每次操作结束时 都会报告跳过的文件数目,但是如果某些拷贝操作失败了,但在之后的尝试成功了, 那么报告的信息可能不够精确。
每个JobTracker必须都能够与源端和目的端文件系统进行访问和交互。
拷贝完成后,建议生成源端和目的端文件的列表,并交叉检查,来确认拷贝真正成功。 因为distcp使用Map/Reduce和文件系统API进行操作,所以这三者或它们之间有任何问题 可能影响拷贝。
值得注意的是,当另一个客户端同时在向源文件写入时,拷贝很有可能会失败。 尝试覆盖HDFS上正在被写入的文件的操作也会失败。 如果一个源文件在拷贝之前被移动或删除了,拷贝失败同时输出异常 FileNotFoundException。
c) 默认情况下,虽然distcp会跳过在目标路径上已经存在的文件,但是通过-overwirte选项可以选择对这些文件进行覆盖重写,也可以使用,-update选项仅对更新过的文件进行重写。
实战案例:
案例要求 从/cluster/A1/ 和 /cluster/A2/ 到 /cluster/B1的拷贝,源路径包括:
hdfs://192.168.7.120:8020/cluster/A1
hdfs://192.168.7.120:8020/cluster/A1/a1
hdfs://192.168.7.120:8020/cluster/A1/a2
hdfs://192.168.7.120:8020/cluster/A2
hdfs://192.168.7.120:8020/cluster/A2/a3
hdfs://192.168.7.120:8020/cluster/A2/a1
如果没设置-update或 -overwrite选项, 那么两个源都会映射到目标端的 /cluster/B1/A1A2。 如果设置了这两个选项,每个源目录的内容都会和目标目录的 内容 做比较。distcp碰到这类冲突的情况会终止操作并退出。 默认情况下,/cluster/B1/A1 和 /cluster/B1/A2 目录都会被创建,所以并不会有冲突。 现在讲-update用法:
distcp -update hdfs://192.168.7.120:8020/cluster/A1 \
hdfs://192.168.7.120:8020/cluster/A2 \
hdfs://192.168.8.120:8020/cluster/B1 其中源路径/大小: hdfs://192.168.7.120:8020/cluster/A1
hdfs://192.168.7.120:8020/cluster/A1/a1 32
hdfs://192.168.7.120:8020/cluster/A1/a2 64
hdfs://192.168.7.120:8020/cluster/A2
hdfs://192.168.7.120:8020/cluster/A2/a3 64
hdfs://192.168.7.120:8020/cluster/A2/a4 32 和目的路径/大小: hdfs://192.168.8.120:8020/cluster/B1
hdfs://192.168.8.120:8020/cluster/B1/a1 32
hdfs://192.168.8.120:8020/cluster/B1/a2 32
hdfs://192.168.8.120:8020/cluster/B1/a3 128 会产生: hdfs://192.168.8.120:8020/cluster/B1
hdfs://192.168.8.120:8020/cluster/B1/a1 32
hdfs://192.168.8.120:8020/cluster/B1/a2 32
hdfs://192.168.8.120:8020/cluster/B1/a3 64
hdfs://192.168.8.120:8020/cluster/A2/a4 32
发现部分192.168.8.120的a2文件没有被覆盖(a3却覆盖)。如果指定了 -overwrite选项,所有文件都会被覆盖。
d) distcp操作有很多选项可以设置,比如忽略失败、限制文件或者复制的数据量等。直接输入指令或者不附加选项则可以查看此操作的使用说明。
附件distcp可以选配的参数:

夸集群版本数据copy
hadoop distcp hftp://192.168.7.120:50070/cluster/A/ hdfs://192.168.8.120:8020/cluster/B1
需要注意的是,要定义访问源的URI中NameNode的网络接口,这个接口会通过dfs.namenode.http-address的属性值设定,默认值为50070 ,参考hdfs-site.xml:

3 实战出现的问题总结
a)ipc.StandbyException : //s.apache.org/sbnn-error
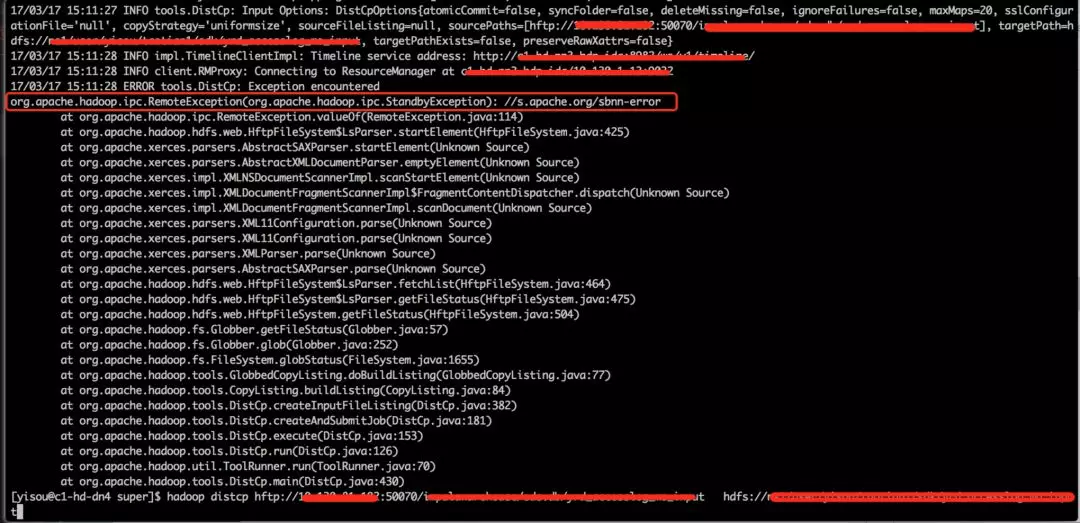
解决:

Dfs所链接的namenode的状态不是active的 处于standby状态不予链接,所以方法:换一个namenode, 保证新的namenode是active
b) java.io.IOException:Check-sum mismatch
分析:该问题很常见,能在网上查到,是因为不同版本hadoop 的checksum版本不同,老版本用crc32,新版本用crc32c;
解决:只要在distcp时增加两个参数(-skipcrccheck -update),忽略crc检查即可。注意-skipcrccheck参数要与-update同时使用才生效。
c) java.net.UnknowHostException
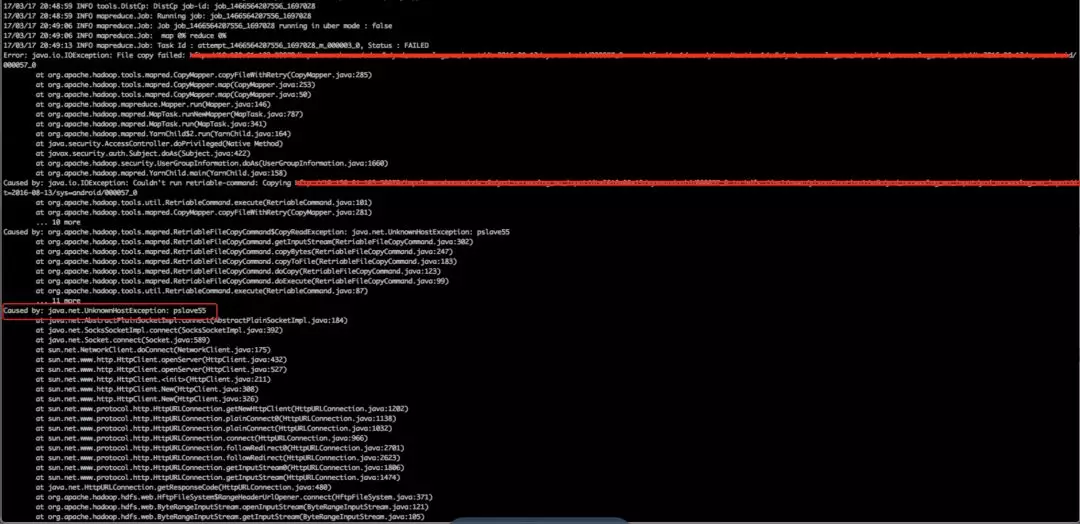
原因分析:图中可以看到,distcp job已经启动了,map 0%, 但是报了UnknowHostException:pslaves55,可能的原因是在从datanode取数据时,用的是host pslave55, 而这个host是数据源集群特有的,目标集群不识别,所以报UnknowHostException.
解决办法:在目标集群中配置hosts文件,将数据源集群中所有的host和ip的对应关系追加到目标集群中的hosts文件中,使得目标集群在访问host名时(如pslave55)能成功映射到ip
4 总结
要实现跨集群拷贝,如拷贝A集群的数据到B集群,需要确认以下事情:
(1)确认B集群机器都能ping通A集群所有ip。
(2) 用的port 响应在各自节点上放开 iptables 不要“拦住”
(3)如果部门间的端口防火墙已经开通,但还是telnet不同,请确认A集群的iptables已经加入了B集群ip。
(4)如果在B集群有UnknowHostException,则需要将A集群的host与ip映射关系追加到B集群的hosts文件中。
附上常用端口port 对照:


其他配置参考官方:
http://hadoop.apache.org/docs/r2.7.6/hadoop-distcp/DistCp.html
Hadoop源生实用工具之distcp的更多相关文章
- .Net 高效开发之不可错过的实用工具(转)
.Net 高效开发之不可错过的实用工具(转) 本文摘自: http://www.cnblogs.com/powertoolsteam/p/5240908.html#3372237 Visual Stu ...
- .NET 高效开发之不可错过的实用工具(第一的当然是ReSharper插件)
工欲善其事,必先利其器,没有好的工具,怎么能高效的开发出高质量的代码呢?本文为 ASP.NET 开发者介绍一些高效实用的工具,包括 SQL 管理,VS插件,内存管理,诊断工具等,涉及开发过程的各个环节 ...
- NET 高效开发之不可错过的实用工具(第一的当然是ReSharper插件)
工欲善其事,必先利其器,没有好的工具,怎么能高效的开发出高质量的代码呢?本文为 ASP.NET 开发者介绍一些高效实用的工具,包括 SQL 管理,VS插件,内存管理,诊断工具等,涉及开发过程的各个环节 ...
- Bootstrap<基础十> 响应式实用工具
Bootstrap 提供了一些辅助类,以便更快地实现对移动设备友好的开发.这些可以通过媒体查询结合大型.小型和中型设备,实现内容对设备的显示和隐藏. 需要谨慎使用这些工具,避免在同一个站点创建完全不同 ...
- 10款让WEB前端开发人员更轻松的实用工具
这篇文章介绍10款让Web前端开发人员生活更轻松的实用工具.每个Web开发人员都有自己的工具箱,这样工作中碰到的每个问题都有一个好的解决方案供选择. 对于每一项工作,开发人员需要特定的辅助工具,所以如 ...
- 十款让 Web 前端开发人员更轻松的实用工具
这篇文章介绍十款让 Web 前端开发人员生活更轻松的实用工具.每个 Web 开发人员都有自己的工具箱,这样工作中碰到的每个问题都有一个好的解决方案供选择. 对于每一项工作,开发人员需要特定的辅助工具, ...
- 实用工具推荐(Live Writer)(2015年05月26日)
1.写博客的实用工具 推荐软件:Live Writer 使用步骤: 1.安装 Live Essential 2011,下载地址:http://explore.live.com/windows-live ...
- 快速访问WCF服务--ServiceModel 元数据实用工具 (Svcutil.exe)
基本定义 ServiceModel 元数据实用工具用于依据元数据文档生成服务模型代码,以及依据服务模型代码生成元数据文档. SvcUtil.exe ServiceModel 元数据实用工具可在 Win ...
- Mac开发者必备实用工具推荐
最近一个师兄给我推荐了一些Mac上的实用工具,用起来非常顺手,能提高不少开发效率.于是就想着把自己之前用过的其他工具也整理一下,一块推荐给大家,希望能对大家有帮助. Alfred 目前Mac下最好用的 ...
随机推荐
- 杂项-Log:NLog
ylbtech-杂项-Log:NLog NLog是一个基于.NET平台编写的类库,我们可以使用NLog在应用程序中添加极为完善的跟踪调试代码. NLog是一个简单灵活的.NET日志记录类库.通过使用N ...
- Python错误处理和调试
错误处理(try...except...finally...) try: print('try...') r = 10 / 0 print('result:', r) except ZeroDivis ...
- TS学习之接口
TypeScript的核心原则之一是对值所具有的结构进行类型检查.接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约. interface testType { name: string; ...
- html锚链接
锚点(anchor):其实就是超链接的一种,一种特殊的超链接 普通的超链接,<a href="路径"></a> 是跳转到不同的页面 而锚点,<a hr ...
- linux命令-zip压缩unzip解压缩
和windows的zip的压缩文件是通用的 可以解压缩 压缩文件 /////////////////////////////////////////////////////////// [root@ ...
- JAVAWeb SSH框架 利用POI 导出EXCEL,弹出保存框
导入包这一些不多说,直接贴出关键代码,JSP只要点一个Action链接就行. poi包我是用:poi-3.11-20141221.jar 亲测有效: 效果: Action 类代码: private I ...
- 【总结整理】JQuery基础学习---DOM篇
前言: 先介绍下需要用到的浏览器提供的一些原生的方法(这里不处理低版本的IE兼容问题) 创建流程比较简单,大体如下: 创建节点(常见的:元素.属性和文本) 添加节点的一些属性 加入到文档中 流程中涉及 ...
- docker里安装ubuntu
使用 Ubuntu 官方镜像 Ubuntu 相关的镜像有很多,这里使用 -s 10 参数,只搜索那些被收藏 10 次以上的镜像 $ docker search -s 10 ubuntu NAME DE ...
- 具体问题:3、hibernate跟Mybatis/ ibatis 的区别,为什么选择?
第一章 Hibernate与MyBatis Hibernate 是当前最流行的O/R mapping框架,它出身于sf.net,现在已经成为Jboss的一部分. Mybatis 是另外一种优秀 ...
- ARC097C K-th Substring
传送门 题目 You are given a string s. Among the different substrings of s, print the K-th lexicographical ...