kylin 连接 hortonworks 中的 hive 遇到的问题
用 hortonworks(V3.1.0.0) 部署了 ambari (V2.7.3),用 ambari 部署了 hadoop 及 hive。
1. 启动 kylin(V2.6)时,遇到如下问题:
Retrieving hadoop conf dir...
KYLIN_HOME is set to /opt/programs/kylin
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Retrieving hive dependency...
Something wrong with Hive CLI or Beeline, please execute Hive CLI or Beeline CLI in terminal to find the root cause.
经过查找,最后一行的错误信息是在 find-hive-dependency.sh 这个脚本中的,查看此脚本,是由于 hive_env 没有值引起的,
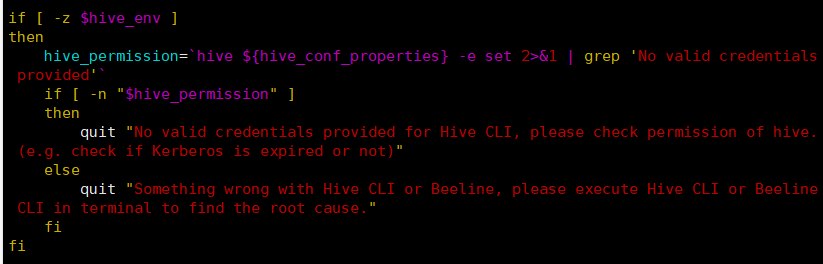
进一步分析脚本,发现是因为脚本中的下面这段脚本没有得到值
hive_env=`hive ${hive_conf_properties} -e set >& | grep 'env:CLASSPATH'`
直接在 shell 中运行上面的命令,确实没有输出。想了半天,把管道命令符前面的命令的输出,输出到一个文件。然后查找文件,发现是有 env:CLASSPATH 这一内容的。 但是为

唯一能想到的原因是:管道符命令,前面命令的输出是有大小限制的,超过多少字符后,只能把最后多少个字符传给后面的命令。
修改 find-hive-dependency.sh,把 hive_env=`hive ${hive_conf_properties} -e set 2>&1 | grep 'env:CLASSPATH'` 这一行删掉,加入下面几行后,kylin 能成功启动了。
hive -e set >/tmp/hive_env.txt >&
hive_env=`grep 'env:CLASSPATH' /tmp/hive_env.txt`
hive_env=`echo ${hive_env#*env:CLASSPATH}`
hive_env="env:CLASSPATH"${hive_env}
2. kylin 创建 module 和 cube,可是在 build cube 时发生问题。在 stackoverflow 上提了此问题,也没有正确答案。后来还是偶然间,解决了问题。具体描述见
kylin 连接 hortonworks 中的 hive 遇到的问题的更多相关文章
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
- 在hue中使用hive
一.创建新表 建表语句如下: CREATE TABLE IF NOT EXISTS user_collection_9( user_id string , seller_id string , pro ...
- 怎样在Java中运行Hive命令或HiveQL
这里所说的在Java中运行Hive命令或HiveQL并非指Hive Client通过JDBC的方式连接HiveServer(or HiveServer2)运行查询,而是简单的在部署了HiveServe ...
- Apache Kylin高级部分之使用Hive视图
本章节我们将介绍为什么须要在Kylin创建Cube过程中使用Hive视图.而假设使用Hive视图.能够带来什么优点.解决什么样的问题.以及须要学会怎样使用视图.使用视图有什么限制等等. 1. ...
- 将CDH中的hive和hbase相互整合使用
一..hbase与hive的兼容版本: hive0.90与hbase0.92是兼容的,早期的hive版本与hbase0.89/0.90兼容,不需要自己编译. hive1.x与hbase0.98.x或则 ...
- 【大数据】SparkSql 连接查询中的谓词下推处理 (一)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/YPN85WBNcnhk8xKjTPTa2g 作者:李勇 目录: 1.SparkSql 2.连接查询和 ...
- 如何在 Flink 1.9 中使用 Hive?
Apache Flink 从 1.9.0 版本开始增加了与 Hive 集成的功能,用户可以通过 Flink 来访问 Hive 的元数据,以及读写 Hive 中的表.本文将主要从项目的设计架构.最新进展 ...
- TCP连接探测中的Keepalive和心跳包
TCP连接探测中的Keepalive和心跳包 tcp keepalive 心跳 保活 Linuxtcp心跳keepalive保活1. TCP保活的必要性 1) 很多防火墙等对于空闲socket自动关闭 ...
- ora-01445:无法从不带保留关键字的表的连接视图中选择ROWID或采样
系统要创建一个物化试图,用到很多张表,执行的时候报错: ora-01445:无法从不带保留关键字的表的连接视图中选择ROWID或采样 网上搜了下,有多种原因和解决方法,最终我选择先尝试一下修改 ...
随机推荐
- 第二届PHP全球开发者大会(含大会的PPT)
PHP全球开发者大会于2016年5月14日至15日在北京召开 更多现场图片请猛击: http://t.cn/RqeP7y9 , http://t.cn/RqD8Typ 最后,这次大会的PPT可以在这 ...
- java--构造器与static
原本无显示编码构造器,则有一个默认的隐式(隐藏的无参构造器),但是,当显示指定了构造器,则这个默认隐式的构造器将不存在,比如此时无法new无参的构造器(除非显示地编写声明无参的构造函数). 如果子类构 ...
- linux命令-mount挂载umount卸载
格式化完成之后想写数据 要先挂载 //////////////////////////////////////////////////////////////////// [root@wangshao ...
- mysql show status 参数解析
状态名 作用域 详细解释 Aborted_clients Global 由于客户端没有正确关闭连接导致客户端终止而中断的连接数 Aborted_connects Global 试图连接到MySQL服务 ...
- solr :term 查询, phrase查询, boolean 查询
搜索总体有:term 查询, phrase查询, boolean 查询 1. SOLR搜索覆盖度和准确度保证的三个搜索方式: 保证准确率: AND: Search for two different ...
- php返回文件路径
1 basename — 返回路径中的文件名部分 如果文件名为test.php,路径为www/hj/test.php echo basename($_SERVER['PHP_SELF']); 输出为: ...
- 71-n皇后
N皇后问题 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submi ...
- Mind Map-在线软件(转)
From http://blog.sina.com.cn/s/blog_74b687ac0102dtp1.html 第一款:http://tu.mindpin.com/ 用非常简单, 先用Email ...
- php学习笔记-continue和break
这两个关键字经常被用在循环中,但作用是完全不同的. 在循环中遇到continue这个单词的时候一定要理解为skip,跳过或者略过,啥意思?就是跳过本次循环,后面的循环继续走起来,老铁. break是说 ...
- Django框架 之 ORM 常用字段和参数
Django框架 之 ORM 常用字段和参数 浏览目录 常用字段 字段合集 自定义字段 字段参数 DateField和DateTimeField 关系字段 ForeignKey OneToOneFie ...