kylin 连接 hortonworks 中的 hive 遇到的问题
用 hortonworks(V3.1.0.0) 部署了 ambari (V2.7.3),用 ambari 部署了 hadoop 及 hive。
1. 启动 kylin(V2.6)时,遇到如下问题:
Retrieving hadoop conf dir...
KYLIN_HOME is set to /opt/programs/kylin
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
Retrieving hive dependency...
Something wrong with Hive CLI or Beeline, please execute Hive CLI or Beeline CLI in terminal to find the root cause.
经过查找,最后一行的错误信息是在 find-hive-dependency.sh 这个脚本中的,查看此脚本,是由于 hive_env 没有值引起的,
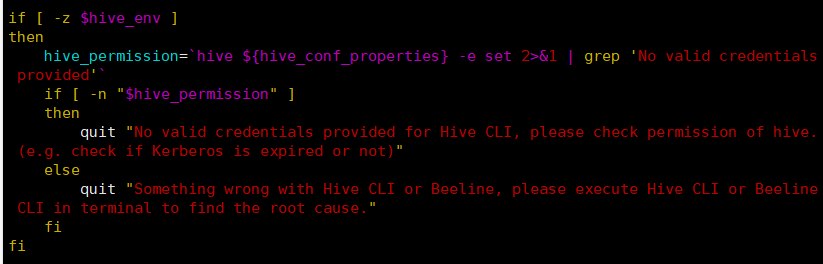
进一步分析脚本,发现是因为脚本中的下面这段脚本没有得到值
hive_env=`hive ${hive_conf_properties} -e set >& | grep 'env:CLASSPATH'`
直接在 shell 中运行上面的命令,确实没有输出。想了半天,把管道命令符前面的命令的输出,输出到一个文件。然后查找文件,发现是有 env:CLASSPATH 这一内容的。 但是为

唯一能想到的原因是:管道符命令,前面命令的输出是有大小限制的,超过多少字符后,只能把最后多少个字符传给后面的命令。
修改 find-hive-dependency.sh,把 hive_env=`hive ${hive_conf_properties} -e set 2>&1 | grep 'env:CLASSPATH'` 这一行删掉,加入下面几行后,kylin 能成功启动了。
hive -e set >/tmp/hive_env.txt >&
hive_env=`grep 'env:CLASSPATH' /tmp/hive_env.txt`
hive_env=`echo ${hive_env#*env:CLASSPATH}`
hive_env="env:CLASSPATH"${hive_env}
2. kylin 创建 module 和 cube,可是在 build cube 时发生问题。在 stackoverflow 上提了此问题,也没有正确答案。后来还是偶然间,解决了问题。具体描述见
kylin 连接 hortonworks 中的 hive 遇到的问题的更多相关文章
- Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录
Mac OSX系统中Hadoop / Hive 与 spark 的安装与配置 环境搭建 记录 Hadoop 2.6 的安装与配置(伪分布式) 下载并解压缩 配置 .bash_profile : ...
- 在hue中使用hive
一.创建新表 建表语句如下: CREATE TABLE IF NOT EXISTS user_collection_9( user_id string , seller_id string , pro ...
- 怎样在Java中运行Hive命令或HiveQL
这里所说的在Java中运行Hive命令或HiveQL并非指Hive Client通过JDBC的方式连接HiveServer(or HiveServer2)运行查询,而是简单的在部署了HiveServe ...
- Apache Kylin高级部分之使用Hive视图
本章节我们将介绍为什么须要在Kylin创建Cube过程中使用Hive视图.而假设使用Hive视图.能够带来什么优点.解决什么样的问题.以及须要学会怎样使用视图.使用视图有什么限制等等. 1. ...
- 将CDH中的hive和hbase相互整合使用
一..hbase与hive的兼容版本: hive0.90与hbase0.92是兼容的,早期的hive版本与hbase0.89/0.90兼容,不需要自己编译. hive1.x与hbase0.98.x或则 ...
- 【大数据】SparkSql 连接查询中的谓词下推处理 (一)
本文首发于 vivo互联网技术 微信公众号 https://mp.weixin.qq.com/s/YPN85WBNcnhk8xKjTPTa2g 作者:李勇 目录: 1.SparkSql 2.连接查询和 ...
- 如何在 Flink 1.9 中使用 Hive?
Apache Flink 从 1.9.0 版本开始增加了与 Hive 集成的功能,用户可以通过 Flink 来访问 Hive 的元数据,以及读写 Hive 中的表.本文将主要从项目的设计架构.最新进展 ...
- TCP连接探测中的Keepalive和心跳包
TCP连接探测中的Keepalive和心跳包 tcp keepalive 心跳 保活 Linuxtcp心跳keepalive保活1. TCP保活的必要性 1) 很多防火墙等对于空闲socket自动关闭 ...
- ora-01445:无法从不带保留关键字的表的连接视图中选择ROWID或采样
系统要创建一个物化试图,用到很多张表,执行的时候报错: ora-01445:无法从不带保留关键字的表的连接视图中选择ROWID或采样 网上搜了下,有多种原因和解决方法,最终我选择先尝试一下修改 ...
随机推荐
- 蓝桥杯 算法训练 ALGO-125 王、后传说
算法训练 王.后传说 时间限制:1.0s 内存限制:256.0MB 问题描述 地球人都知道,在国际象棋中,后如同太阳,光芒四射,威风八面,它能控制横.坚.斜线位置. 看过清宫戏的中国人都知道, ...
- java代码输入流篇2
总结: 方法.和之前的有不同,但是名字太长了+++++ package com.aini; import java.io.*; public class ghd { public static voi ...
- “百度杯”CTF比赛 九月场
Test: 题目提示查资料 打开地址,是一个海洋cms 海洋cms有个前台getshell的漏洞 在地址后加上/search.php?searchtype=5&tid=&area=ev ...
- CS231n 2016 通关 第三章-SVM与Softmax
1===本节课对应视频内容的第三讲,对应PPT是Lecture3 2===本节课的收获 ===熟悉SVM及其多分类问题 ===熟悉softmax分类问题 ===了解优化思想 由上节课即KNN的分析步骤 ...
- 10-17C#第四部分--类型(1)
C#类型--String类 一.String类型 () 注:string与String的不同:string属于String的数据类型,小写string是大写String类型的实例化:string属于S ...
- 微信开发准备(一)--Maven仓库管理新建WEB项目
转自:http://www.cuiyongzhi.com/post/13.html 在我们的项目开发中经常会遇到项目周期很长,项目依赖jar包特别多的情况,所以我们经常会在项目中引入Maven插件,建 ...
- 部署和调优 1.6 vsftp部署和优化-2
映射个虚拟用户 创建个用户,不让他登录 useradd virftp -s /sbin/nologin 创建存放虚拟用户用户和密码的文件 vim /etc/vsftpd/vsftpd_login 写入 ...
- LookupError: unknown encoding: cp65001解决办法
一.之前手上做的一个web项目,漏洞频发,服务器用的是菜鸟云服务器,那个应急响应中心不错,想不到乌云倒了,白帽子竟然被阿里系养了,题外话了,首先感谢白帽子提的漏洞,同时也感慨自己安全知识,以及意识的薄 ...
- Linux 查看一个端口的连接数
netstat -antp|grep -i "80" |wc -l 譬如查看80端口的连接数
- python中not的用法
python中的not具体表示是什么: 在python中not是逻辑判断词,用于布尔型True和False,not True为False,not False为True,以下是几个常用的not的用法: ...