吴恩达机器学习笔记(三) —— Regularization正则化
主要内容:
一.欠拟合和过拟合(over-fitting)
二.解决过拟合的两种方法
三.正则化线性回归
四.正则化logistic回归
五.正则化的原理
一.欠拟合和过拟合(over-fitting)
1.所谓欠拟合,就是曲线没能很好地拟合数据集,一般是由于所选的模型不适合或者说特征不够多所引起的。
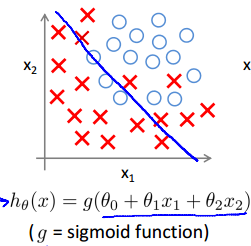
2.所谓过拟合,就是曲线非常好地拟合了数据集(甚至达到完全拟合地态度),这貌似是一件很好的事情,但是,曲线千方百计地去“迎合”数据集,就导致了其对其他数据的预测性或者说通用性不高。这就好像,期末考试前,老师指明了考试内容,同学千方百计地去复习这些内容,于是就就很容易拿到高分,这就可以理解为过拟合,但当以后要用到这一门科目的其他知识的时候,之前的复习的用处就大打折扣了,因为基本没有触及到其他知识,即期末考试前的“复习”只迎合了期末考试,但对以后的帮助不大,通用性不高。
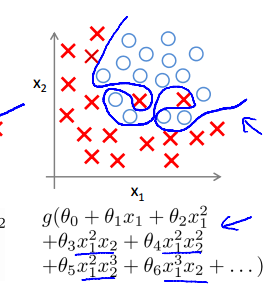
二.解决过拟合的两种方法
1.减少特征数(feature):可知,当特征x1、x2……xn的数量n越多时,就越容易拟合数据集(特征越多,曲线越弯曲,伸缩性越大)。所以为了防止过拟合,可以手工地去掉一些特征或者利用一些算法自动筛选出特征。比如,预测房子价格时,有大小和房间数两个特征,这时可以去掉房间数这个特征以避免过拟合。
2.正则化:正则化可以保留下所有的特征,但是需要对参数做一些“惩罚”,这个“惩罚”就是降低参数的数量级,事实证明(别人说的,人云亦云的我):当参数的值处以一个较小的范围内时,曲线相对平滑,也就可以避免过拟合了。至于如何“惩罚”,请看下文。
三.正则化线性回归
我们在损失函数的后面加多一项:
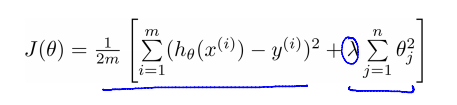
向量化后: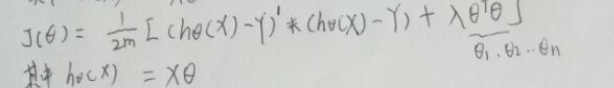
这一项就叫做“正则项”,起到了惩罚参数的作用。注意j是1开始到n,即不惩罚θ0,具体原因现在还不清楚。
其中λ调节着正常项与正则项在损失函数中所占的比重,当λ过大时,正则项所占的比重就会很大,导致参数的数量级很小,甚至接近于0,出现欠拟合的现象。
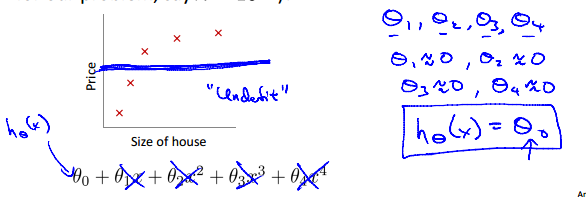
正则化后的梯度下降为:
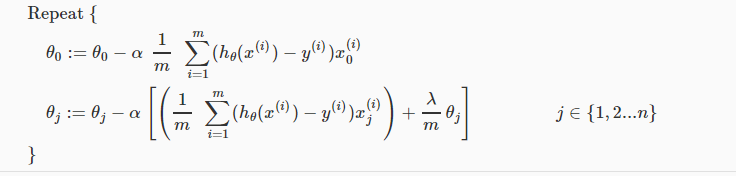
对于上式θj(1<=j<=n),将其进一步化简,得:
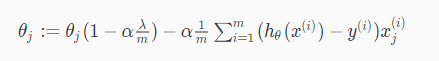
其中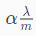 是一个小于1的正数(具体原因现在还不清楚)。在每次迭代的时候,θj都是先乘以一个小于1的倍数再去减那一堆东西,所以相比没有正则化,正则化后的就更容易变小了(模模糊糊的)。
是一个小于1的正数(具体原因现在还不清楚)。在每次迭代的时候,θj都是先乘以一个小于1的倍数再去减那一堆东西,所以相比没有正则化,正则化后的就更容易变小了(模模糊糊的)。
向量化后: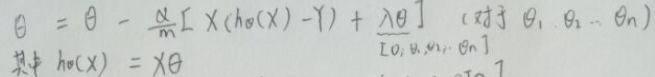
(注意:正则项的Θ0应该改为0,表明不惩罚Θ0)
而对于最小二乘法,就变为了:
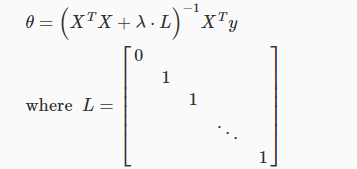
四.正则化logistic回归
加入正则项后:
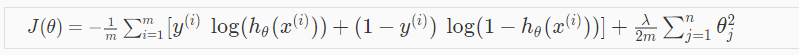
向量化后: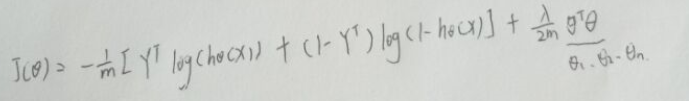
梯度下降就变为:

向量化后: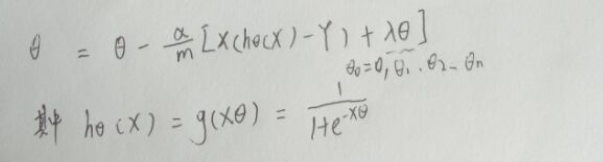
五.正则化的原理
在损失函数里加多一个λθ^2,就可以对参数θ进行惩罚,降低θ的数量级,这是为什么呢?有什么数学的解释?
答:自己想到一个。当θ越靠近0时,θ^2越小;当θ越远离0时,θ^2越大。所以在最小化损失函数的过程中,λθ^2这一项有拉低θ的数量级的作用(使得θ往0的方向靠近),从而对参数θ进行惩罚。
吴恩达机器学习笔记(三) —— Regularization正则化的更多相关文章
- 吴恩达机器学习笔记(六) —— 支持向量机SVM
主要内容: 一.损失函数 二.决策边界 三.Kernel 四.使用SVM (有关SVM数学解释:机器学习笔记(八)震惊!支持向量机(SVM)居然是这种机) 一.损失函数 二.决策边界 对于: 当C非常 ...
- Coursera-AndrewNg(吴恩达)机器学习笔记——第三周
一.逻辑回归问题(分类问题) 生活中存在着许多分类问题,如判断邮件是否为垃圾邮件:判断肿瘤是恶性还是良性等.机器学习中逻辑回归便是解决分类问题的一种方法.二分类:通常表示为yϵ{0,1},0:&quo ...
- [吴恩达机器学习笔记]12支持向量机2 SVM的正则化参数和决策间距
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.2 大间距的直观理解- Large Margin I ...
- 吴恩达机器学习笔记36-正则化和偏差/方差(Regularization and Bias_Variance)
在我们在训练模型的过程中,一般会使用一些正则化方法来防止过拟合.但是我们可能会正则化的程度太高或太小了,即我们在选择λ 的值时也需要思考与刚才选择多项式模型次数类似的问题. 我们选择一系列的想要测试的
- Coursera-AndrewNg(吴恩达)机器学习笔记——第三周编程作业
一. 逻辑回归 1.背景:使用逻辑回归预测学生是否会被大学录取. 2.首先对数据进行可视化,代码如下: pos = find(y==); %找到通过学生的序号向量 neg = find(y==); % ...
- Coursera-AndrewNg(吴恩达)机器学习笔记——第三周编程作业(逻辑回归)
一. 逻辑回归 1.背景:使用逻辑回归预测学生是否会被大学录取. 2.首先对数据进行可视化,代码如下: pos = find(y==); %找到通过学生的序号向量 neg = find(y==); % ...
- 吴恩达机器学习笔记19-过拟合的问题(The Problem of Overfitting)
到现在为止,我们已经学习了几种不同的学习算法,包括线性回归和逻辑回归,它们能够有效地解决许多问题,但是当将它们应用到某些特定的机器学习应用时,会遇到过拟合(over-fitting)的问题,可能会导致 ...
- [吴恩达机器学习笔记]14降维5-7重建压缩表示/主成分数量选取/PCA应用误区
14.降维 觉得有用的话,欢迎一起讨论相互学习~Follow Me 14.5重建压缩表示 Reconstruction from Compressed Representation 使用PCA,可以把 ...
- [吴恩达机器学习笔记]12支持向量机5SVM参数细节
12.支持向量机 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考资料 斯坦福大学 2014 机器学习教程中文笔记 by 黄海广 12.5 SVM参数细节 标记点选取 标记点(landma ...
随机推荐
- shell去掉后缀方法
#!/bin/bash olddir=/home/img/luimg newdir=/home/img/luimg/thumb while read line do if [ -f $olddir${ ...
- IntelliJ IDEA 、genymotion模拟器、Android开发环境搭建
首先打开IDEA,看到该界面,如果没有该界面,请在User/用户名/IntelliJIDEAProjects/下删除所有项目文件夹.然后重启IDEA即可看到 接着开始配置jdk和sdk 然后在Proj ...
- CoreAnimation的使用小结
參考:http://www.cnblogs.com/wendingding/p/3801157.htmlhttp://www.cnblogs.com/wendingding/p/3802830.htm ...
- PHP中常见的几种运行代码的方式
常见的运行程序的方法有 shell_exec ``(反引号) eval system exec passthru 下面分别介绍他们的用法: 名称 解释 返回值 注意 shell_exec 通过 she ...
- Pycharm context menu disable RUN option
这个问题很坑.正常来说一个文件右键出来的是 Run 选项, 可是近期几个文件都是 Unititest 的測试选项,每次要执行的时候都要手工去配置Run Option,在尝试了: 0. 重置IDE配置 ...
- MySQL 下 ROW_NUMBER / DENSE_RANK / RANK 的实现
原文链接:http://hi.baidu.com/wangzhiqing999/item/7ca215d8ec9823ee785daa2b MySQL 下 ROW_NUMBER / DENSE_RAN ...
- Netty实现java多线程Post请求解析(Map参数类型)—SKY
netty解析Post的键值对 解析时必须加上一个方法,ch.pipeline().addLast(new HttpObjectAggregator(2048)); 放在自己的Handel前面. ht ...
- 洛谷 P3216 [HNOI2011]数学作业
最近学了矩阵,kzj大佬推荐了我这一道题目. 乍一眼看上去,没看出是矩阵,就随便打了一个暴力,30分. 然后仔细分析了一波,发现蛮简单的. 结果全wa了,先看看下面的错误分析吧! 首先,设f[n]为最 ...
- CXF生成client注意事项
1. 在使用wsdl2java命令生成client文件时在Service的Java文件中面出现super构造错误,这是因为jax-ws2.2规约与java6冲突 故须要减少jax-ws规约版本号. ...
- 存储过程 & 触发器
触发器主要是通过事件进行触发而被执行的,而存储过程可以通过存储过程名字而被直接调用.当对某一表进行诸如UPDATE. INSERT. DELETE 这些操作时, 就会自动执行触发器所定义的SQL 语句 ...