MySQL主从配置实战笔记
其实网上已经有关于MySQL主从复制的很丰富全面的资料了,这里写点东西主要是为了给自己加深印象。
复制原理###
MySQL主从复制是内建的非常强大的功能,主要应用于数据备份,负载均衡等方面。因为配置相对比较简单,因此基本上稍微成型的线上MySQL业务都会使用到主从复制。
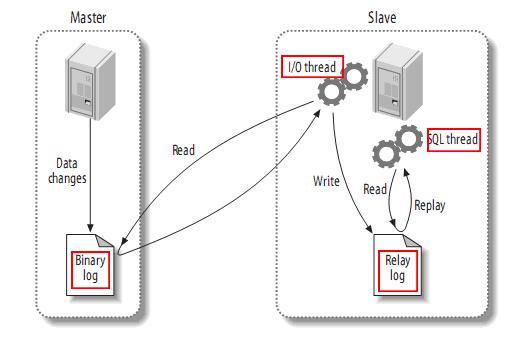
master主机将数据变更记录写入二进制日志binary-log,slave从机通过网络I/O读取后写入中继日志reply-log,然后SQL进程读取中继日志进行数据复制。这里面有几个关键点:
- master主机的binary-log
master 主机的 binary-log 决定了你从什么位置开始复制 - slave从机读取master主机的binary-log,写入reply-log
slave的I/O进程需要能正确读取master的binary-log(账号权限,网络连通),状态参数Slave_IO_Running - slave读取reply-log,进行数据重刻
slave的SQL进程能否正确复刻数据,状态参数Slave_SQL_Running
了解了上述过程,那么对MySQL的主从配置也就手到擒来。
环境准备###
准备两台以上的机器分别安装MySQL。或者一台已经在使用的MySQL服务,另一台新装。
- 条件不够的同学可以在一台机器安装两个MySQL实例(一个3306端口,一个3307端口),或者装虚拟机。
- master 和 slave 的MySQL版本需要保持一致。(slave版本必须高于master,最好保持一致。)
之前有在线上业务环境配置slave版本高于master的经历,能正常运行,偶尔会有bug导致复制停止
master主机配置###
分配唯一的server-id.
开启binary-log
分配复制的账号和权限
前两步在my.cnf中[mysqld]下加入以下配置:# master
# 唯一server-id标识,本机局域网IP是10.10.10.5,这里取方便识别
server-id = 5
# 开启binary-log,请注意通常my.cnf已经默认配置为mysql-bin
log-bin = master-bin
log-bin-index = master-bin.index
分配一个用于主从复制的账号:
mysql > GRANT REPLICATION SLAVE,RELOAD,SUPER ON *.* TO my_replication@’10.10.10.6’ IDENTIFIED BY ‘my_replication’;
因为我salve的IP是10.10.10.6;
重启master的MySQL服务,然后查看主机状态:
mysql> show master status;
+------------------+-----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+-----------+--------------+------------------+-------------------+
| mysql-bin.000011 | 880922125 | | | |
+------------------+-----------+--------------+------------------+-------------------+
slave配置准备###
如果master是已经运行中的服务,需要保证数据完整性。这里有两个方法,
一,暂停master的MySQL服务,将数据拷贝至slave,相对较快。
二,若master在一开始就开启了binary-log,将slave的MASTER_LOG_FILE设置为初始值,让slave通过读日志的方式慢慢恢复数据。
然后配置slave的my.cnf:
# slave #
# slave的IP是10.10.10.6
server-id = 6
# 开启中继日志
relay-log-index = slave-relay-bin.index
relay-log = slave-relay-bin
# 可选配置,将slave的update操作也写入*slave*的binary-log中,这样一来slave也可以作为一个master角色
#log_slave_updates = 1
启动slave###
重启MySQL服务。
设置slave的master:
CHANGE MASTER TO
MASTER_HOST='10.10.10.5',
MASTER_USER='my_replication',
MASTER_PASSWORD='my_replication',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=0;
字段含义:
# MASTER_HOST -- master主机
# MASTER_USER,MASTER_PASSWORD -- 复制账号
# MASTER_LOG_FILE,MASTER_LOG_POS -- 复制开始的bin-log文件,bin-log文件会根据大小自动增加,如果是意外终止的复制,可以设置log-file来选择从某一个文件开始复制。
开启复制:
mysql> START SLAVE;查看slave状态:
MySQL> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.10.10.5
Master_User: carl_replication
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000011
Read_Master_Log_Pos: 880886701
Relay_Log_File: slave-relay-bin.000012
Relay_Log_Pos: 880886914
Relay_Master_Log_File: mysql-bin.000011
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
Seconds_Behind_Master: 0
...
1 row in set (0.00 sec)
主要查看slave的SQL和I/O进程状态是否都为Yes
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
另外需要关注Seconds_Behind_Master落后主机的时间延迟,单位是秒。
如果需要对slave状态进行监控,基本上就是SHOW SLAVE STATUS\G 然后筛选这3个字段信息进行告警判断。
以上参数正常说明主从配置已经成功,在master插入几条数据进行测试。
在master建立一个新表
CREATE TABLE `php_test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`adate` timestamp NULL DEFAULT CURRENT_TIMESTAMP,
`name` varchar(45) DEFAULT NULL,
`desc` varchar(255) DEFAULT '',
PRIMARY KEY (`id`),
UNIQUE KEY `name_UNIQUE` (`name`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8
注意这里的adate字段是默认使用当前时间戳。插入数据:
mysql> INSERT INTO `php_test` (`name`,`desc`) VALUES ('replication', 'It works!');
Query OK, 1 row affected (0.03 sec)
mysql> SELECT * FROM php_test;
+----+---------------------+-------------+-----------+
| id | adate | name | desc |
+----+---------------------+-------------+-----------+
| 1 | 2017-07-25 15:41:52 | replication | It works! |
+----+---------------------+-------------+-----------+
1 row in set (0.00 sec)
然后切换到slave:
MySQL [php_test]> SELECT * FROM php_test;
+----+---------------------+-------------+-----------+
| id | adate | name | desc |
+----+---------------------+-------------+-----------+
| 1 | 2017-07-25 15:41:52 | replication | It works! |
+----+---------------------+-------------+-----------+
1 row in set (0.00 sec)
需要注意的是这里adate字段会始终跟master中的数据保持一致,跟slave复制执行的时间无关。
貌似这里跟复制模式有关,如果是基于行的复制,那么adate会保持一致;如果是基于SQL语句的复制,那么adate是复制执行的时间?
故障分享:
- 大部分时候可以重启slave解决:
STOP SLAVE;START SLAVE; - 复制过程意外停止后重启slave的时候可以通过
CHANGE MASTER设置开始复制的log-file位置,保证数据完整统一 - 复制产生错误意外中止需要跳过错误,可以通过语句
SET GLOBAL SQL_SLAVE_SKIP_COUNTER = N(N表示跳过的行数),也可以通过设置MASTER_LOG_POS跳过。 - master的DDL语句(表结构变化)有时会先于
update到达(master上是先update再alter,到了slave上就变成先alter再update),然后旧的update语句由于表结构发生变化无法执行。这里有个办法就是手动将slave的表结构改回之前,然后再改回来。后来想想应该是操作失误反复设置MASTER_LOG_FILE的位置导致
好了,入门配置暂时就介绍到这里,更多关于MySQL主从的知识还要靠自己去多学习。
推荐文章:Mysql主从复制原理及配置:http://www.2cto.com/database/201502/374598.html
MySQL主从配置实战笔记的更多相关文章
- Mysql主从配置实战
实战mysql主从配置 准备两个docker容器,分别在3306和3307开启两个mysql为主从数据库 可执行以下命令 docker run -p 3306:3306 --name mysql330 ...
- MySQl 主从配置实战
目前后台数据库使用了一个实例做数据统计分析,随着数据井喷,单个实例无法做数据分析.故开始了读写分离. 1.主配置 [client] port = 3306 socket = /tmp/mysql-33 ...
- Mysql笔记之 -- 小试MYSQL主从配置
mysql主从配置: 硬件: 两台服务器 1.Ubuntu 12.04.4 LTS (GNU/Linux 3.2.0-60-generic-pae i686) 2.Ubuntu 12.04.4 LT ...
- mysql主从配置和galera集群
mariadb主从 主从多用于网站架构,因为主从的同步机制是异步的,数据的同步有一定延迟,也就是说有可能会造成数据的丢失,但是性能比较好,因此网站大多数用的是主从架构的数据库,读写分离必须基于主从架构 ...
- mysql主从配置
引言: 双11,阿里云服务器打折,于是我忍不住又买了一台服务器,于是咱也是有两台服务器的爷们了,既然有了两台服务器,那么肯定要好好利用一下吧,那么就来玩玩mysql的主从配置吧. 准备 两台数据库服务 ...
- Mysql主从配置,实现读写分离
大型网站为了软解大量的并发访问,除了在网站实现分布式负载均衡,远远不够.到了数据业务层.数据访问层,如果还是传统的数据结构,或者只是单单靠一台服务器扛,如此多的数据库连接操作,数据库必然会崩溃,数据丢 ...
- CentOS 7下的 Mysql 主从配置
最近在玩mysql主从配置,在此记录一下 一.前言 1.安装两个虚拟机(CentOS 7).iP分别是192.168.47.131 和192.168.47.133.其中192.168.47.133作为 ...
- Mysql主从配置+读写分离
Mysql主从配置+读写分离 MySQL从5.5版本开始,通过./configure进行编译配置方式已经被取消,取而代之的是cmake工具.因此,我们首先要在系统中源码编译安装cmake工具. ...
- mysql主从配置(清晰的思路)
mysql主从配置.鄙人是在如下环境测试的: 主数据库所在的操作系统:win7 主数据库的版本:5.0 主数据库的ip地址:192.168.1.111 从数据库所在的操作系统:linux 从数据的版本 ...
随机推荐
- orcal操作锦集
更新时间:update qs_settle_dt_cfg set end_date=to_date('9999-12-31','yyyy-MM-dd');查询时间:select to_char( e ...
- POJ 2253 Frogger(warshall算法)
题意:湖中有很多石头,两只青蛙分别位于两块石头上.其中一只青蛙要经过一系列的跳跃,先跳到其他石头上,最后跳到另一只青蛙那里.目的是求出所有路径中最大变长的最小值(就是在到达目的地的路径中,找出青蛙需要 ...
- Hibernate学习---第十三节:hibernate过滤器和拦截器的实现
一.hibernate 过滤器 1.在持久化映射文件中配置过滤器,代码如下: <?xml version="1.0"?> <!DOCTYPE hibernate- ...
- spring-springMVC-MyBatis整合配置文件
web.xml <?xml version="1.0" encoding="UTF-8"?> <web-app xmlns="htt ...
- 实现stack 加上·getMin功能 时间复杂度为O(n)
package com.hzins.suanfa; import java.util.Stack; /** * 实现stack 加上·getMin功能 时间复杂度为O(n) * @author Adm ...
- C++ STL, sort用法。
在algorithm头文件中的sort可以给任意对象排序,包括内置类型和自定义类型,前提是定义了“<“运算符. sort(begin,end),表示一个范围,例如: #include" ...
- fedora使用mac osx字体和渲染方式
fedora 19的倒退(中文显示有问题)让人感到很沮丧,不过,后来还是找到了一个很好的解决方案:使用max osx的字体和渲染方式 1. 安装infinality字体渲染软件: rpm -Uvh h ...
- MySQL的分页技术总结
利用子查询示例: SELECT * FROM your_table WHERE id <= (SELECT id FROM your_table ORDER BY id desc LIMIT ( ...
- 第二次C语言实验报告
#一.设计题目,设计思路,实现方法 ##设计题目 15-10 找最长的字符串,14-5 指定位置输出字符串,13-6 数组循环右移,12-5 查找指定字符,11-5 打印杨辉三角. ##设计思路 15 ...
- loadrunner手动生成脚本函数
1.点击insert