机器学习:SVM(基础理解)
一、基础理解
1)简介
- SVM(Support Vector Machine):支撑向量机,既可以解决分类问题,又可以解决回归问题;
- SVM 算法可分为:Hard Margin SVM、Soft Margin SVM,其中 Soft Margin SVM 算法是由 Hard Margin SVM 改进而来;
2)不适定问题
- 不适定问题:决策边界不唯一,可能会偏向某一样本类型,模型泛化能力较差;
- 具有不适定问题的模型的特点:决策边界不准确,泛化能力较差;
- 原因:模型由训练数据集训练所得,训练数据集并没有包含所有类型的所有样本,训练数据集的样本的分布,可能不能准确的反应不同类型的样本分布的真正规律,由训练数据集得到模型,该模型的决策边界也很可能不是真正的分类边界;这样的话,该模型的决策边界会偏向某一样本类型,使模型泛化能力较差。
3)逻辑回归中的 不适定问题
- 逻辑回归思想:定义一个概率函数,根据概率函数进行建模,形成损失函数,最小化损失函数得到决策边界;
- 决策边界可能是多种情况:
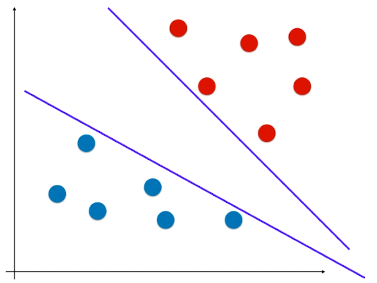
- 如图:如果有一个样本,离红色类型较近,离蓝色类型较远,但由于决策边界偏向红色类型,模型会判断该样本为蓝色类型:
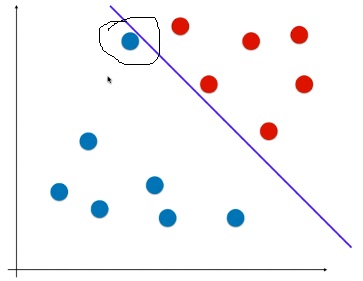
4)SVM 算法的思想
- 解决“不适定问题”;
- 目的:找到一个最优决策边界,不仅很好的划分训练数据集,又有很好的泛化能力;
- 方法:让该决策边界离两种类别的样本都尽可能的远;
- 或者说,在逻辑回归的决策边界的基础上,让离直线最近的点尽可能的远(如图离直线较近的 3 个点)
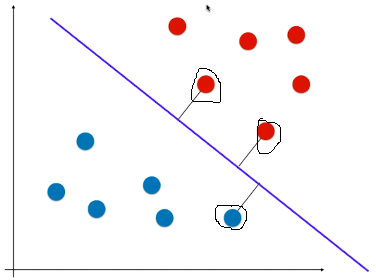
- 思想:SVM 在考虑未来模型的泛化能力时,没有寄望在数据的预处理阶段,或者模型的正则化手段上;而是将泛化能力的考量直接放在了算法的内部,找到一条决策边界,决策边界离不同类型的样本都尽可能的远;
- 疑问:为什么离两种类别的样本都尽可能的远的直线,能对该两类样本更好的划分?
- 原因:直观来看,这种决策边界的泛化能力较好,但这种假设不仅仅根据直观的现象,其背后也有数学理论;(数学中可以证明,面对“不适定问题”,这种方法找到的决策边界,对应的模型的泛化能力较好)正是由于这种原因,SVM 也是统计学中重要的方法,其背后有极强的统计理论知识的支撑;
5)SVM 实现的具体方法
- 决策边界就是根据支撑向量和 margin 所得;
- 支撑向量:特征空间中,距离决策边界最近的不同类型的样本点;(如图所示)
- margin:如图所示,特征空间中,由两类支撑向量决定的两条线的距离;
- 如图:决策边界为中间的那天线;
- margin = 2d
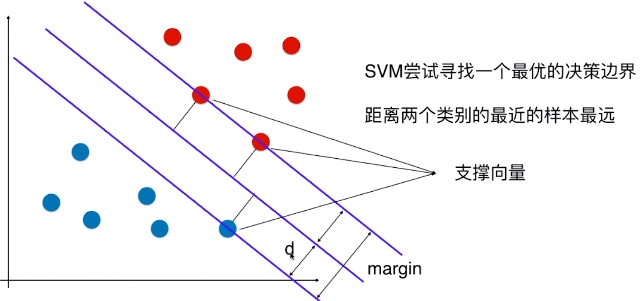
- SVM 算法本质就是要最大化 margin;
6)线性可分、Hard Margin SVM、Soft Margin SVM
- 不管是讨论逻辑回归算法还是 SVM 算法,前提是:样本分布线性可分;
- 线性可分:对于特征空间,存在一条直线或一个平面将样本完全分开
- Hard Margin SVM:
- 解决线性可分问题的 SVM 算法;
- 非常严格的,确实找到了一个决策边界,没有错误的将样本点进行了划分,同时最大化了 margin 的值;
- Soft Margin SVM:
- 解决线性不可分的问题;
- 实践中,大多真实的样本数据是线性不可分的;
- Soft Margin SVM 算法是从 Hard Margin SVM 的基础上改进的;
机器学习:SVM(基础理解)的更多相关文章
- SVM(支持向量机)简介与基础理解
SVM(支持向量机)主要用于分类问题,主要的应用场景有字符识别.面部识别.行人检测.文本分类等领域.原文地址:https://zhuanlan.zhihu.com/p/21932911?refer=b ...
- 转:机器学习中的算法(2)-支持向量机(SVM)基础
机器学习中的算法(2)-支持向量机(SVM)基础 转:http://www.cnblogs.com/LeftNotEasy/archive/2011/05/02/basic-of-svm.html 版 ...
- 文本分类学习 (五) 机器学习SVM的前奏-特征提取(卡方检验续集)
前言: 上一篇比较详细的介绍了卡方检验和卡方分布.这篇我们就实际操刀,找到一些训练集,正所谓纸上得来终觉浅,绝知此事要躬行.然而我在躬行的时候,发现了卡方检验对于文本分类来说应该把公式再变形一般,那样 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- C#委托零基础理解
C#委托零基础理解(转) 1, 为什么使用委托 2.什么是委托 3.委托如何使用 为什么使用委托? 委托是c#中非常重要的一个概念,使用委托使程序员可以将方法引用封装在委托对象内.然后可以将该委 ...
- Spark机器学习 Day2 快速理解机器学习
Spark机器学习 Day2 快速理解机器学习 有两个问题: 机器学习到底是什么. 大数据机器学习到底是什么. 机器学习到底是什么 人正常思维的过程是根据历史经验得出一定的规律,然后在当前情况下根据这 ...
- pyhton机器学习入门基础(机器学习与决策树)
//2019.07.26#scikit-learn数据挖掘工具包1.Scikit learn是基于python的数据挖掘和机器学习的工具包,方便实现数据的数据分析与高级操作,是数据分析里面非常重要的工 ...
- 机器学习中的算法(2)-支持向量机(SVM)基础
版权声明:本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gma ...
- 机器学习之深入理解SVM
在浏览本篇博客之前,最好先查看一下我写的还有一篇文章机器学习之初识SVM(点击可查阅哦).这样能够更好地为了结以下内容做铺垫! 支持向量机学习方法包括构建由简至繁的模型:线性可分支持向量机.线性支持向 ...
随机推荐
- Druid数据库连接池的一般使用
据说:阿里的Druid这款产品,是目前最好用的数据库池产品,下面就来看下怎么在我们项目中去使用它吧. 项目背景:使用的是SpringMvc+Spring+mybatis 在ssm框架里面使用数据连接池 ...
- 【codevs2333】&【BZOJ2002】弹飞绵羊[HNOI2010](分块)
我其实是在codevs上看到它的题号后才去做这道题的...2333... 题目传送门:codevs:http://codevs.cn/problem/2333/ bzoj:http://www.lyd ...
- volatile的特性
volatile的特性 当我们声明共享变量为volatile后,对这个变量的读/写将会很特别.理解volatile特性的一个好方法是:把对volatile变量的单个读/写,看成是使用同一个监视器锁对这 ...
- HDU 3966 & POJ 3237 & HYSBZ 2243 & HRBUST 2064 树链剖分
树链剖分是一个很固定的套路 一般用来解决树上两点之间的路径更改与查询 思想是将一棵树分成不想交的几条链 并且由于dfs的顺序性 给每条链上的点或边标的号必定是连着的 那么每两个点之间的路径都可以拆成几 ...
- Spring初学之spring的事务管理注解
spring的事务管理,本文的例子是:比如你需要网购一本书,卖书的那一方有库存量以及书的价格,你有账户余额.回想我们在编程中要实现买书这样的功能,由于你的账户表和书的库存量表肯定不是同一张数据库表,所 ...
- jquery下json数组的操作用法实例
jquery下json数组的操作用法实例: jquery中操作JSON数组的情况中遍历方法用的比较多,但用添加移除这些好像就不是太多了. 试过json[i].remove(),json.remove( ...
- 最实用的 Linux 命令行使用技巧
我们可能每天都会要使用到很多的 Linux 命令行. 我们也会网络上知晓一些使用它们的小技巧,但是如果我们没有时常来进行练习,就有可能会忘掉怎么去使用它们. 所以我就决定把那些你可能会忘记的小提示和小 ...
- hdu 2509 Be the Winner(anti nim)
Be the Winner Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tot ...
- uva12563 Jin Ge Jin Qu hao(01背包)
这是一道不错的题.首先通过分析,贪心法不可取,可以转化为01背包问题.但是这过程中还要注意,本题中的01背包问题要求背包必须装满!这就需要在普通的01背包问题上改动两处,一个是初始化的问题:把dp[0 ...
- vs2012 sln和.vcxproj有什么区别
sln是解决方案的配置,主要是管理这个方案里的多个vcxprojvcxproj是工程的配置文件,管理工程中细节比如包含的文件,引用库等一般没有sln,也可以直接打开vcxproj,也可以重新生成sln ...