Logistic回归计算过程的推导
https://blog.csdn.net/ligang_csdn/article/details/53838743
https://blog.csdn.net/weixin_30014549/article/details/52850870
https://www.cnblogs.com/HolyShine/p/6403116.html
2. 基本原理
Logistic Regression和Linear Regression的原理是相似的,按照我自己的理解,可以简单的描述为这样的过程:
(1)找一个合适的预测函数(Andrew Ng的公开课中称为hypothesis),一般表示为h函数,该函数就是我们需要找的分类函数,它用来预测输入数据的判断结果。这个过程时非常关键的,需要对数据有一定的了解或分析,知道或者猜测预测函数的“大概”形式,比如是线性函数还是非线性函数。
(2)构造一个Cost函数(损失函数),该函数表示预测的输出(h)与训练数据类别(y)之间的偏差,可以是二者之间的差(h-y)或者是其他的形式。综合考虑所有训练数据的“损失”,将Cost求和或者求平均,记为J(θ)函数,表示所有训练数据预测值与实际类别的偏差。
(3)显然,J(θ)函数的值越小表示预测函数越准确(即h函数越准确),所以这一步需要做的是找到J(θ)函数的最小值。找函数的最小值有不同的方法,Logistic Regression实现时有的是梯度下降法(Gradient Descent)。
3. 具体过程
3.1 构造预测函数
Logistic Regression虽然名字里带“回归”,但是它实际上是一种分类方法,用于两分类问题(即输出只有两种)。根据第二章中的步骤,需要先找到一个预测函数(h),显然,该函数的输出必须是两个值(分别代表两个类别),所以利用了Logistic函数(或称为Sigmoid函数),函数形式为:
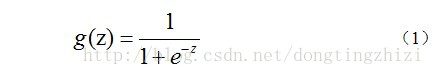
对应的函数图像是一个取值在0和1之间的S型曲线(图1)。
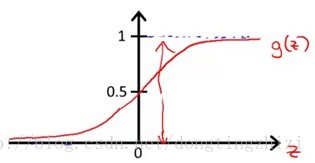
图1
接下来需要确定数据划分的边界类型,对于图2和图3中的两种数据分布,显然图2需要一个线性的边界,而图3需要一个非线性的边界。接下来我们只讨论线性边界的情况。
图2

图3
对于线性边界的情况,边界形式如下:
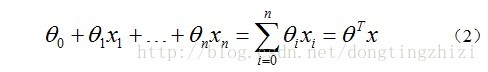
构造预测函数为:
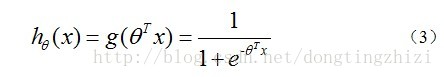
hθ(x)函数的值有特殊的含义,它表示结果取1的概率,因此对于输入x分类结果为类别1和类别0的概率分别为:
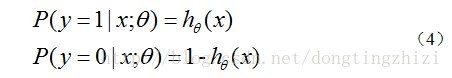
3.2 构造Cost函数
Andrew Ng在课程中直接给出了Cost函数及J(θ)函数如式(5)和(6),但是并没有给出具体的解释,只是说明了这个函数来衡量h函数预测的好坏是合理的。
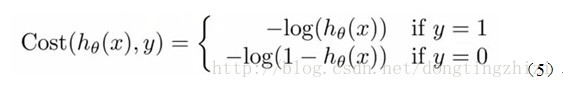
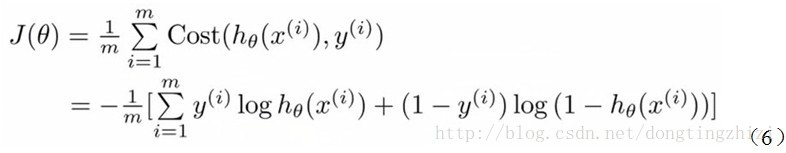
实际上这里的Cost函数和J(θ)函数是基于最大似然估计推导得到的。下面详细说明推导的过程。(4)式综合起来可以写成:
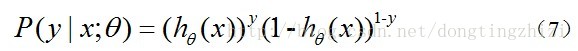
取似然函数为:
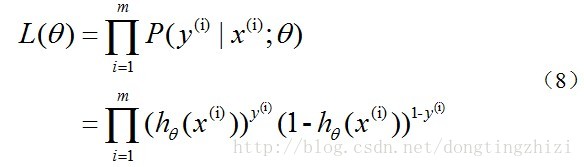
对数似然函数为:
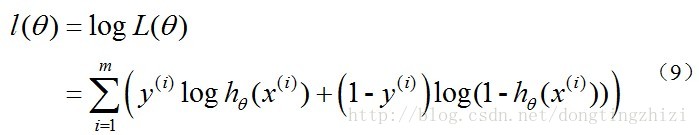
最大似然估计就是要求得使l(θ)取最大值时的θ,其实这里可以使用梯度上升法求解,求得的θ就是要求的最佳参数。但是,在Andrew Ng的课程中将J(θ)取为(6)式,即:

因为乘了一个负的系数-1/m,所以J(θ)取最小值时的θ为要求的最佳参数。
3.3 梯度下降法求J(θ)的最小值
求J(θ)的最小值可以使用梯度下降法,根据梯度下降法可得θ的更新过程:
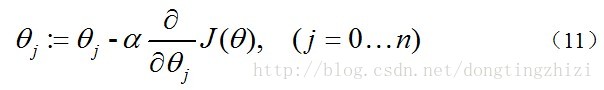
式中为α学习步长,下面来求偏导:
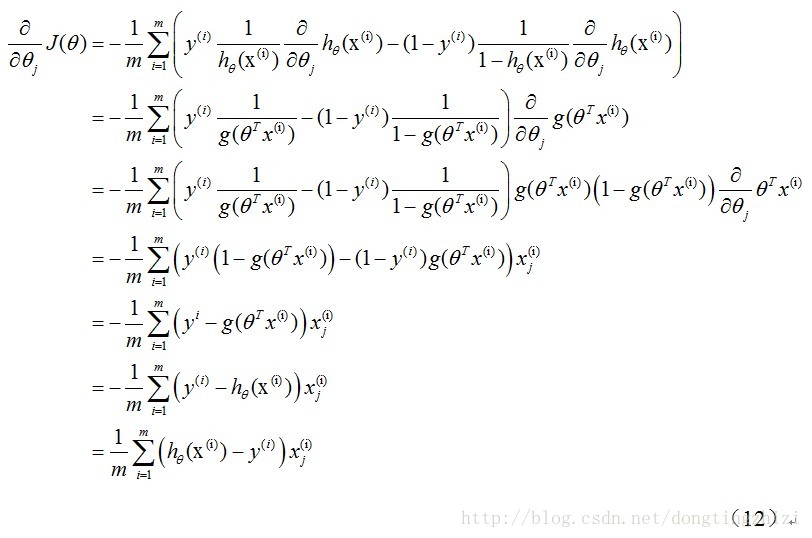
上式求解过程中用到如下的公式:
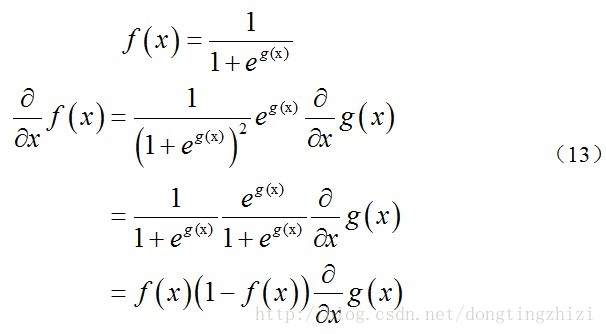
因此,(11)式的更新过程可以写成:
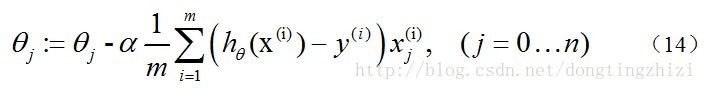
因为式中α本来为一常量,所以1/m一般将省略,所以最终的θ更新过程为:
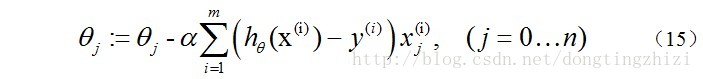
另外,补充一下,3.2节中提到求得l(θ)取最大值时的θ也是一样的,用梯度上升法求(9)式的最大值,可得:
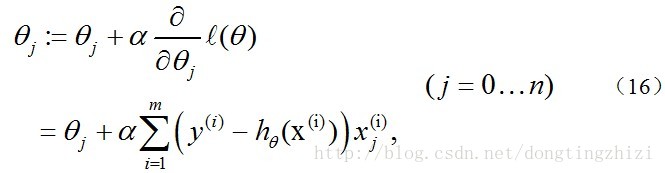
观察上式发现跟(14)是一样的,所以,采用梯度上升发和梯度下降法是完全一样的,这也是《机器学习实战》中采用梯度上升法的原因。
3.4 梯度下降过程向量化
关于θ更新过程的vectorization,Andrew Ng的课程中只是一带而过,没有具体的讲解。
《机器学习实战》连Cost函数及求梯度等都没有说明,所以更不可能说明vectorization了。但是,其中给出的实现代码确是实现了vectorization的,图4所示代码的32行中weights(也就是θ)的更新只用了一行代码,直接通过矩阵或者向量计算更新,没有用for循环,说明确实实现了vectorization,具体代码下一章分析。
文献[3]中也提到了vectorization,但是也是比较粗略,很简单的给出vectorization的结果为:
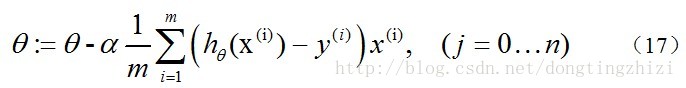
且不论该更新公式正确与否,这里的Σ(...)是一个求和的过程,显然需要一个for语句循环m次,所以根本没有完全的实现vectorization,不像《机器学习实战》的代码中一条语句就可以完成θ的更新。
下面说明一下我理解《机器学习实战》中代码实现的vectorization过程。
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:
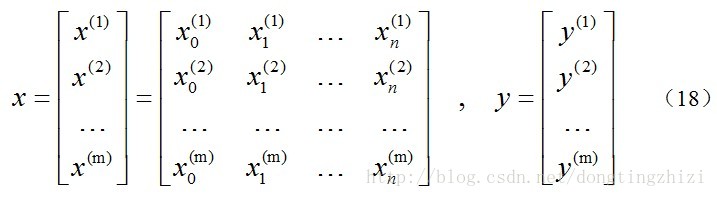
约定待求的参数θ的矩阵形式为:
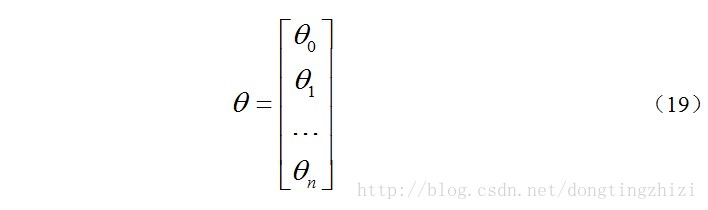
先求x.θ并记为A:

求hθ(x)-y并记为E:
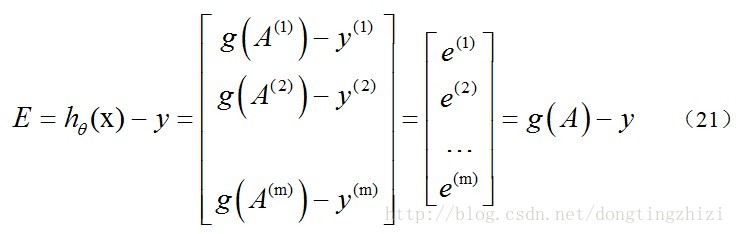
g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。由上式可知hθ(x)-y可以由g(A)-y一次计算求得。
再来看一下(15)式的θ更新过程,当j=0时:
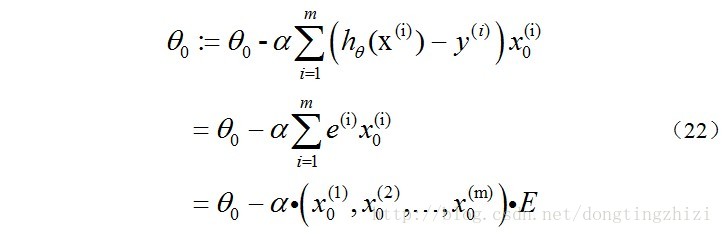
同样的可以写出θj,
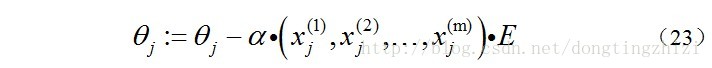
综合起来就是:
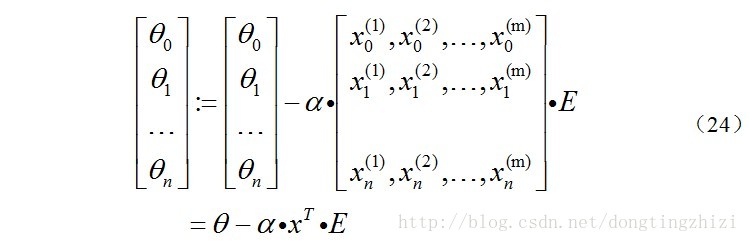
综上所述,vectorization后θ更新的步骤如下:
(1)求A=x.θ;
(2)求E=g(A)-y;
(3)求θ:=θ-α.x'.E,x'表示矩阵x的转置。
也可以综合起来写成:
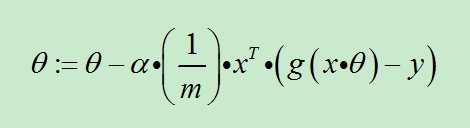
前面已经提到过:1/m是可以省略的。
4. 代码分析
图4中是《机器学习实战》中给出的部分实现代码。
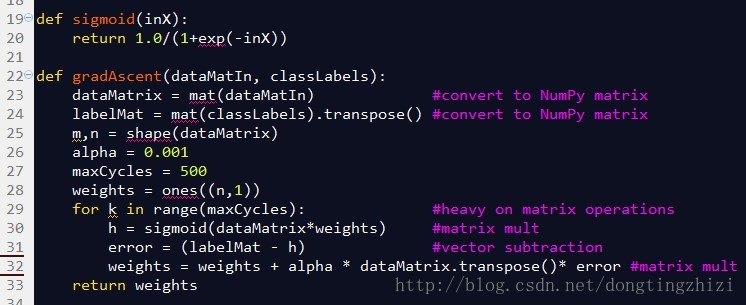
图4
sigmoid函数就是前文中的g(z)函数,参数inX可以是向量,因为程序中使用了Python的numpy。
gradAscent函数是梯度上升的实现函数,参数dataMatin和classLabels为训练数据,23和24行对训练数据做了处理,转换成numpy的矩阵类型,同时将横向量的classlabels转换成列向量labelMat,此时的dataMatrix和labelMat就是(18)式中的x和y。alpha为学习步长,maxCycles为迭代次数。weights为n维(等于x的列数)列向量,就是(19)式中的θ。
29行的for循环将更新θ的过程迭代maxCycles次,每循环一次更新一次。对比3.4节最后总结的向量化的θ更新步骤,30行相当于求了A=x.θ和g(A),31行相当于求了E=g(A)-y,32行相当于求θ:=θ-α.x'.E。所以这三行代码实际上与向量化的θ更新步骤是完全一致的。
总结一下,从上面代码分析可以看出,虽然只有十多行的代码,但是里面却隐含了太多的细节,如果没有相关基础确实是非常难以理解的。相信完整的阅读了本文,就应该没有问题了!^_^。
【参考文献】
[1]《机器学习实战》——【美】Peter Harington
[2] Stanford机器学习公开课(https://www.coursera.org/course/ml)
[3] http://blog.csdn.net/abcjennifer/article/details/7716281
[4] http://www.cnblogs.com/tornadomeet/p/3395593.html
[5] http://blog.csdn.net/moodytong/article/details/9731283
[6] http://blog.csdn.net/jackie_zhu/article/details/8895270
Logistic回归计算过程的推导的更多相关文章
- Logistic回归Cost函数和J(θ)的推导(二)----梯度下降算法求解最小值
前言 在上一篇随笔里,我们讲了Logistic回归cost函数的推导过程.接下来的算法求解使用如下的cost函数形式: 简单回顾一下几个变量的含义: 表1 cost函数解释 x(i) 每个样本数据点在 ...
- 统计学习方法6—logistic回归和最大熵模型
目录 logistic回归和最大熵模型 1. logistic回归模型 1.1 logistic分布 1.2 二项logistic回归模型 1.3 模型参数估计 2. 最大熵模型 2.1 最大熵原理 ...
- matlib实现logistic回归算法(序一)
数据下载:http://archive.ics.uci.edu/ml/datasets/Adult 数据描述:http://archive.ics.uci.edu/ml/machine-learnin ...
- 机器学习 —— 基础整理(五)线性回归;二项Logistic回归;Softmax回归及其梯度推导;广义线性模型
本文简单整理了以下内容: (一)线性回归 (二)二分类:二项Logistic回归 (三)多分类:Softmax回归 (四)广义线性模型 闲话:二项Logistic回归是我去年入门机器学习时学的第一个模 ...
- Logistic回归Cost函数和J(θ)的推导----Andrew Ng【machine learning】公开课
最近翻Peter Harrington的<机器学习实战>,看到Logistic回归那一章有点小的疑问. 作者在简单介绍Logistic回归的原理后,立即给出了梯度上升算法的code:从算法 ...
- Logistic回归算法梯度公式的推导
最近学习Logistic回归算法,在网上看了许多博文,笔者觉得这篇文章http://blog.kamidox.com/logistic-regression.html写得最好.但其中有个关键问题没有讲 ...
- 『科学计算』通过代码理解线性回归&Logistic回归模型
sklearn线性回归模型 import numpy as np import matplotlib.pyplot as plt from sklearn import linear_model de ...
- Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
- 浅谈Logistic回归及过拟合
判断学习速率是否合适?每步都下降即可.这篇先不整理吧... 这节学习的是逻辑回归(Logistic Regression),也算进入了比较正统的机器学习算法.啥叫正统呢?我概念里面机器学习算法一般是这 ...
随机推荐
- TCP/IP协议、HTTP协议、SOCKET通讯详解
1.TCP连接TCP(Transmission Control Protocol) 传输控制协议.TCP是主机对主机层的传输控制协议,提供可靠的连接服务,采用三次握确认建立一个连接.位码即tcp标志位 ...
- Docker操作笔记(二)容器
容器 一.启动容器 启动一个容器有两种方式: 1.基于镜像新键并启动一个容器: 所需要的主要命令为docker run docker run ubuntu:18.04 /bin/echo " ...
- 项目部署到tomcat
准备工作 第一步 准备项目部署文件 准备项目中使用的数据库.sql文件. 准备项目程序(整个项目的war包文件) 第二步 安装运行环境 依次安装JDK.TOMCAT.MYSQL NAVICAT需要注意 ...
- collections标准库
collections标准库 之前Python的第三方库用的一直很舒服,现在突然发现标准库也有collections这样的神器,可以补充list.set.dict以外的应用 1. namedtuple ...
- React(五)State属性
React 里,只需更新组件的 state,然后根据新的 state 重新渲染用户界面(不要操作 DOM). 以下实例创建一个名称扩展为 React.Component 的 ES6 类,在 rende ...
- [LeetCode] Robot Room Cleaner 扫地机器人
Given a robot cleaner in a room modeled as a grid. Each cell in the grid can be empty or blocked. Th ...
- Java 基础:认识&理解关键字 native 实战篇
Writer:BYSocket(泥沙砖瓦浆木匠) 微博:BYSocket 豆瓣:BYSocket 泥瓦匠初次遇见 navicat 是在 java.lang.Object 源码中的一个hashCode方 ...
- 表单/iframe与video标签
<form action="所有表单值提交的地址" method="传值的方式默认是GET方式,还有另一种POST方式"> 表单元素</for ...
- IntelliJ IDEA 2017.2.6 x64 配置 tomcat 启动 maven 项目
IntelliJ IDEA 2017.2.6 x64 配置 tomcat 启动 maven 项目 1.确认 IDEA 是否启用了 tomcat 插件 2.添加 tomcat 选择 tomcat 存放路 ...
- 泡泡一分钟:Cooperative Object Transportation by Multiple Ground and Aerial Vehicles: Modeling and Planning
张宁 Cooperative Object Transportation by Multiple Ground and Aerial Vehicles: Modeling and Planning 多 ...