我眼里K-Means算法
在我眼里一切都是那么简单,复杂的我也看不懂,最讨厌那些复杂的人际关系,唉,像孩子一样交流不好吗。
学习K-Means算法时,会让我想起三国志这个游戏,界面是一张中国地图,诸侯分立,各自为据。但是游戏开始,玩家会是一个人一座城池(我比较喜欢这样,就有挑战性),然后不断的征战各方,占领城池
不断的扩大地盘,正常来说,征战的城池是距离自己较为近的,然后选择这些城池的中心位置作为主城。所以过来一段时间后,地图上就会出现几个主要的势力范围,三足鼎立正是如此。这个过程和K-Means算法十分相似。
接下来我们以下图为游戏地图为例来讲解K-Means算法,地图中的每一个城池为一个数据样例(包含城池的坐标),假如游戏开始设定三个游戏玩家(三个聚类中心K),游戏目的希望最后三个玩家各自为据形成右图的格局。开始游戏!
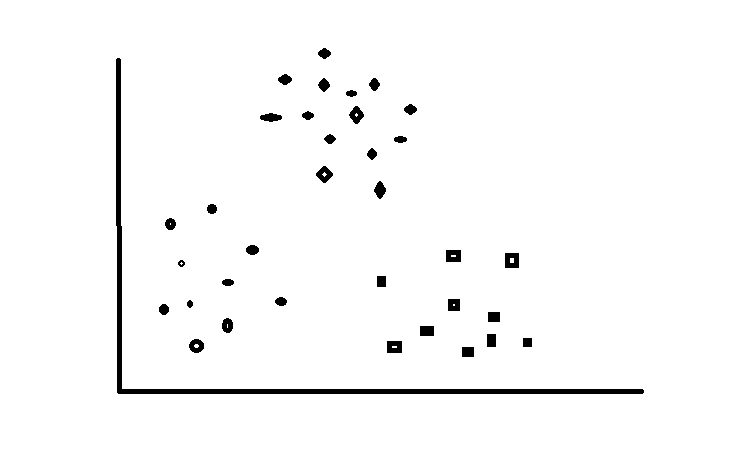
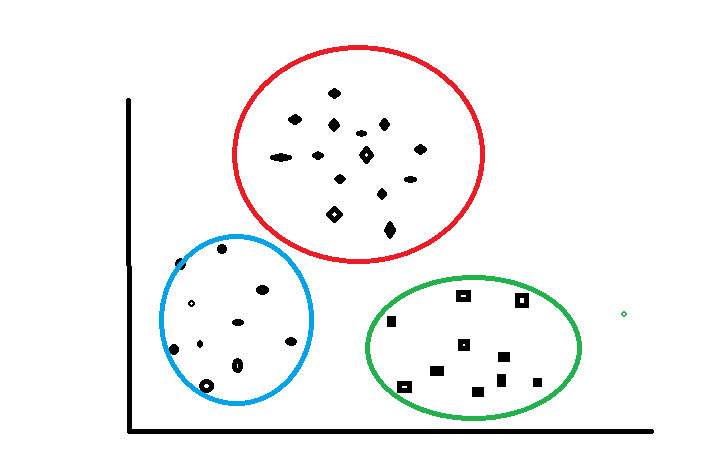
K-Means(k均值算法):
一开始先要介绍算法的整体流程
(1)随机初始化聚类中心的位置
(2)计算每一个点到聚类中心的距离,选取最小值分配给k(i)
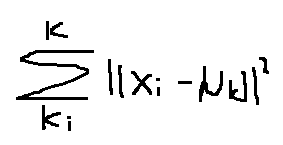
(3)移动聚类中心(其实就是对所属它的样本点求平均值,就是它移动是位置)

(4)重复(2),(3)直到损失函数(也就是所有样本点到其所归属的样本中心的距离的和最小)
最后整体分类格局会变得稳定。
优化目标,也就是之前我们经常提到的损失函数
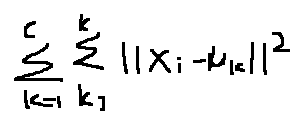
在不断的循环过程中,聚类中心也在不断地更新,直到上式距离总和收敛精确值的时候,获得最优解。
(1) 随机初始化
为了游戏的公平性,使用随机的方式把三个游戏玩家分配到地图上三个城池中(这里需要注意聚类中心的个数一定要小于数据样本的个数)。随机初始化会遇见下面几种情况
1 好的情况

这种情况最为好,因为三个聚类中心已经很好的散布在三个主要的样本类上,再执行下面的算法就可以形成我们想要的分类。
2

这种情况就不太好,红点和绿点一开始就分配在以起,所以一开就会产生对立,对于不好的初始化可能会产生以下聚类结果

这种情况就是就很糟糕了,不符合要求。
对于这种情况我们没有很好的解决办法,可以尝试多次初始化,获取最好的结果,例如设置1000次随机初始化,选取损失函数值最小的一个。
还有一种情况,对于有些数据集天生分布不明显的数据集,怎么才能正确的选择聚类中心的个数,例如:

使用(elbow method)“胳膊肘算法”:
获取损失函数和聚类中心K的函数图像,大致有两种图像类型
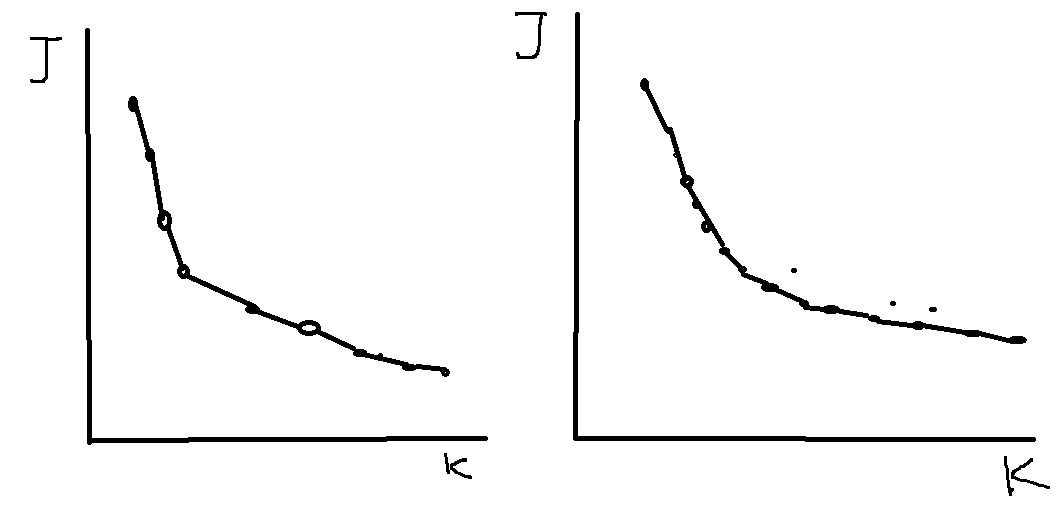
左图的拐点明显,而右图的拐点不是很明显,对于左图我们可以选取拐点处的k作为聚类中心的个数,而如果是右图,那么就需要根据情况选取,比如说,如果数据集是衣服的尺码的数据,如果你想确定这些衣服的尺码类型,那么根据你想要分成几种尺码类型决定(例如:L,M,S)(还有,M,L,XL,XXL,S)
我眼里K-Means算法的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 《机器学习实战》学习笔记一K邻近算法
一. K邻近算法思想:存在一个样本数据集合,称为训练样本集,并且每个数据都存在标签,即我们知道样本集中每一数据(这里的数据是一组数据,可以是n维向量)与所属分类的对应关系.输入没有标签的新数据后,将 ...
- [Machine-Learning] K临近算法-简单例子
k-临近算法 算法步骤 k 临近算法的伪代码,对位置类别属性的数据集中的每个点依次执行以下操作: 计算已知类别数据集中的每个点与当前点之间的距离: 按照距离递增次序排序: 选取与当前点距离最小的k个点 ...
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 聚类算法:K-means 算法(k均值算法)
k-means算法: 第一步:选$K$个初始聚类中心,$z_1(1),z_2(1),\cdots,z_k(1)$,其中括号内的序号为寻找聚类中心的迭代运算的次序号. 聚类中心的向量值可任意设 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- Python实现kNN(k邻近算法)
Python实现kNN(k邻近算法) 运行环境 Pyhton3 numpy科学计算模块 计算过程 st=>start: 开始 op1=>operation: 读入数据 op2=>op ...
随机推荐
- Linux系统下virtuoso数据库安装与使用
最近在调研关联数据的一些东西,需要用到rdf数据库,所以接触了virtuoso数据库.安装的坑其实并不多,之前在windows 10上安过一次.这次在ubuntu 18.04上安装一下,其他的linu ...
- SQL Server 索引碎片产生原理重建索引和重新组织索引
数据库存储本身是无序的,建立了聚集索引,会按照聚集索引物理顺序存入硬盘.既键值的逻辑顺序决定了表中相应行的物理顺序 多数情况下,数据库读取频率远高于写入频率,索引的存在 为了读取速度牺牲写入速度 页 ...
- Windows10系统无法更新
方法一: 1.先检查一下windows update服务是否开启,并禁用杀毒软件: 2.如果此服务已经启动,先尝试更换一下网络环境重新更新: 3.如果更换网络环境后依然无法更新,就删除windows ...
- 谈谈当代大学生学习IT技术的必要性。
21世纪,人类社会已经从工业时代全面进入信息化时代,IT技术的发展正在影响人类的日常生活.比如,外卖平台给人们的用餐提供了更多的选择,移动支付颠覆了传统的支付方式.网购使得人们的购物更加方便,真正做到 ...
- Cocos2d-x游戏开发之lua编辑器 Sublime 搭建,集成cocos2dLuaApi和自有类
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/wisdom605768292/article/details/34085969 Sublime Te ...
- 理论篇-Java中一些零碎的知识点
1. Java中length,length方法,size方法区别 length属性:用于获取数组长度. length方法:用于获取字符串长度. size方法:用于获取泛型集合有多少个元素. 2. is ...
- React-代码规范
1.方法绑定this,统一写在consrtructor()里. constructor(props){ ... this.handleInputChange=this.handleInputChang ...
- 基于C#的钉钉SDK开发(1)--对官方SDK的重构优化
在前段时间,接触一个很喜欢钉钉并且已在内部场景广泛使用钉钉进行工厂内部管理的客户,如钉钉考勤.日常审批.钉钉投影.钉钉门禁等等方面,才体会到原来钉钉已经已经在企业上可以用的很广泛的,因此回过头来学习研 ...
- css3学习系列之移动
transform功能 放缩 使用sacle方法实现文字或图像的放缩处理,在参数中指定缩放倍率,比如sacle(0.5)表示缩小50%,例子如下: <!DOCTYPE html> < ...
- Linux 修改本地时间 (centos为例)
1. tzselect [root@xxxx etc]# tzselect --- 选择时区命令 Please identify a location so that time zone rules ...