[Reinforcement Learning] Value Function Approximation
为什么需要值函数近似?
之前我们提到过各种计算值函数的方法,比如对于 MDP 已知的问题可以使用 Bellman 期望方程求得值函数;对于 MDP 未知的情况,可以通过 MC 以及 TD 方法来获得值函数,为什么需要再进行值函数近似呢?
其实到目前为止,我们介绍的值函数计算方法都是通过查表的方式获取的:
- 表中每一个状态 \(s\) 均对应一个 \(V(s)\)
- 或者每一个状态-动作 <\(s, a\)>
但是对于大型 MDP 问题,上述方法会遇到瓶颈:
- 太多的 MDP 状态、动作需要存储
- 单独计算每一个状态的价值都非常的耗时
因此我们需要有一种能够适用于解决大型 MDP 问题的通用方法,这就是本文介绍的值函数近似方法。即:
\[
\hat{v}(s, \mathbf{w}) \approx v_{\pi}(s) \\
\text{or } \hat{q}(s, a, \mathbf{w}) \approx q_{\pi}(s, a)
\]
那么为什么值函数近似的方法可以求解大型 MDP 问题?
对于大型 MDP 问题而言,我们可以近似认为其所有的状态和动作都被采样和计算是不现实的,那么我们一旦获取了近似的值函数,我们就可以对于那些在历史经验或者采样中没有出现过的状态和动作进行泛化(generalize)。
进行值函数近似的训练方法有很多,比如:
- 线性回归
- 神经网络
- 决策树
- ...
此外,针对 MDP 问题的特点,训练函数必须可以适用于非静态、非独立同分布(non-i.i.d)的数据。
增量方法
梯度下降
梯度下降不再赘述,感兴趣的可以参考之前的博文《梯度下降法的三种形式BGD、SGD以及MBGD》
通过随机梯度下降进行值函数近似
我们优化的目标函数是找到一组参数 \(\mathbf{w}\) 来最小化最小平方误差(MSE),即:
\[J(\mathbf{w}) = E_{\pi}[(v_{\pi}(S) - \hat{v}(S, \mathbf{w}))^2]\]
通过梯度下降方法来寻优:
\[
\begin{align}
\Delta\mathbf{w}
&=-\frac{1}{2}\alpha\triangledown_{\mathbf{w}}J(\mathbf{w})\\
&=\alpha E_{\pi}\Bigl[\Bigl(v_{\pi}(S) - \hat{v}(S, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}J(\mathbf{w})\Bigr]
\end{align}
\]
对于随机梯度下降(Stochastic Gradient Descent,SGD),对应的梯度:
\[\Delta\mathbf{w} = \alpha\underbrace{\Bigl(v_{\pi}(S) - \hat{v}(S, \mathbf{w})\Bigr)}_{\text{error}}\underbrace{\triangledown_{\mathbf{w}}\hat{v}(S, \mathbf{w})}_{\text{gradient}}\]
值函数近似
上述公式中需要真实的策略价值函数 \(v_{\pi}(S)\) 作为学习的目标(supervisor),但是在RL中没有真实的策略价值函数,只有rewards。在实际应用中,我们用target来代替 \(v_{\pi}(S)\):
- 对于MC,target 为 return \(G_t\):
\[\Delta\mathbf{w}=\alpha\Bigl(G_t - \hat{v}(S_t, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}\hat{v}(S_t, \mathbf{w})\] - 对于TD(0),target 为TD target \(R_{t+1}+\gamma\hat{v}(S_{t+1}, \mathbf{w})\):
\[\Delta\mathbf{w}=\alpha\Bigl(R_{t+1} + \gamma\hat{v}(S_{t+1}, \mathbf{w})- \hat{v}(S_t, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}\hat{v}(S_t, \mathbf{w})\] - 对于TD(λ),target 为 TD λ-return \(G_t^{\lambda}\):
\[\Delta\mathbf{w}=\alpha\Bigl(G_t^{\lambda}- \hat{v}(S_t, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}\hat{v}(S_t, \mathbf{w})\]
在获取了值函数近似后就可以进行控制了,具体示意图如下:
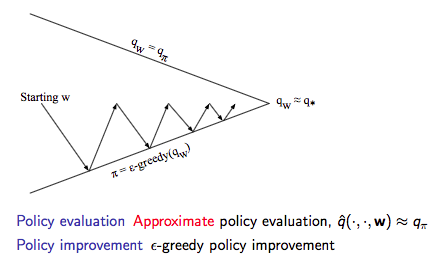
动作价值函数近似
动作价值函数近似:
\[\hat{q}(S, A, \mathbf{w})\approx q_{\pi}(S, A)\]
优化目标:最小化MSE
\[J(\mathbf{w}) = E_{\pi}[(q_{\pi}(S, A) - \hat{q}(S, A, \mathbf{w}))^2]\]
使用SGD寻优:
\[\begin{align}
\Delta\mathbf{w}
&=-\frac{1}{2}\alpha\triangledown_{\mathbf{w}}J(\mathbf{w})\\
&=\alpha\Bigl(q_{\pi}(S, A)-\hat{q}_{\pi}(S, A, \mathbf{w})\Bigr) \triangledown_{\mathbf{w}}\hat{q}_{\pi}(S, A, \mathbf{w})
\end{align}\]
收敛性分析
略,感兴趣的可以参考David的课件。
批量方法
随机梯度下降SGD简单,但是批量的方法可以根据agent的经验来更好的拟合价值函数。
值函数近似
优化目标:批量方法解决的问题同样是 \(\hat{v}(s, \mathbf{w})\approx v_{\pi}(s)\)
经验集合 \(D\) 包含了一系列的 <state, value> pair:
\[D=\{<s_1, v_1^{\pi}>, <s_2, v_2^{\pi}>, ..., <s_T, v_T^{\pi}>\}\]
根据最小化平方误差之和来拟合 \(\hat{v}(s, \mathbf{w})\) 和 \(v_{\pi}(s)\),即:
\[
\begin{align}
LS(w)
&= \sum_{t=1}^{T}(v_{t}^{\pi}-\hat{v}(s_t, \mathbf{w}))^2\\
&= E_{D}[(v^{\pi}-\hat{v}(s, \mathbf{w}))^2]
\end{align}
\]
经验回放(Experience Replay):
给定经验集合:
\[D=\{<s_1, v_1^{\pi}>, <s_2, v_2^{\pi}>, ..., <s_T, v_T^{\pi}>\}\]
Repeat:
- 从经验集合中采样状态和价值:\(<s, v^{\pi}>\sim D\)
- 使用SGD进行更新:\(\Delta\mathbf{w}=\alpha\Bigl(v^{\pi}-\hat{v}(s, \mathbf{w})\Bigr)\triangledown_{\mathbf{w}}\hat{v}(s, \mathbf{w})\)
通过上述经验回放,获得最小化平方误差的参数值:
\[\mathbf{w}^{\pi}=\arg\min_{\mathbf{w}}LS(\mathbf{w})\]
我们经常听到的 DQN 算法就使用了经验回放的手段,这个后续会在《深度强化学习》中整理。
通过上述经验回放和不断的迭代可以获取最小平方误差的参数值,然后就可以通过 greedy 的策略进行策略提升,具体如下图所示:
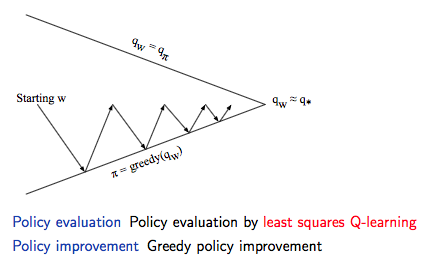
动作价值函数近似
同样的套路:
- 优化目标:\(\hat{q}(s, a, \mathbf{w})\approx q_{\pi}(s, a)\)
- 采取包含 <state, action, value> 的经验集合 \(D\)
- 通过最小化平方误差来拟合
对于控制环节,我们采取与Q-Learning一样的思路:
- 利用之前策略的经验
- 但是考虑另一个后继动作 \(A'=\pi_{\text{new}}(S_{t+1})\)
- 朝着另一个后继动作的方向去更新 \(\hat{q}(S_t, A_t, \mathbf{w})\),即
\[\delta = R_{t+1} + \gamma\hat{q}(S_{t+1}, \pi{S_{t+1}, \mathbf{\pi}}) - \hat{q}(S_t, A_t, \mathbf{w})\] - 梯度:线性拟合情况,\(\Delta\mathbf{w}=\alpha\delta\mathbf{x}(S_t, A_t)\)
收敛性分析
略,感兴趣的可以参考David的课件。
Reference
[1] Reinforcement Learning: An Introduction, Richard S. Sutton and Andrew G. Barto, 2018
[2] David Silver's Homepage
[Reinforcement Learning] Value Function Approximation的更多相关文章
- 2.6. Statistical Models, Supervised Learning and Function Approximation
Statical model regression $y_i=f_{\theta}(x_i)+\epsilon_i,E(\epsilon)=0$ 1.$\epsilon\sim N(0,\sigma^ ...
- Awesome Reinforcement Learning
Awesome Reinforcement Learning A curated list of resources dedicated to reinforcement learning. We h ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- [转]Deep Reinforcement Learning Based Trading Application at JP Morgan Chase
Deep Reinforcement Learning Based Trading Application at JP Morgan Chase https://medium.com/@ranko.m ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
随机推荐
- redis -list
列表的元素类型为string 按照插入顺序排序 增加: 例如: 从列表的 左侧 加入数据 a b c lpush 键 a b c 显示:1“c"2"b"3"c& ...
- HashMap源码分析(二)
前言:上篇文章,笔者分析了jdk1.7中HashMap的源码,这里将对jdk1.8的HashMap的源码进行分析. 注:jdk版本:jdk1.8.0_172 1.再看put操作 public V pu ...
- python 中 try catch finally语句中含有return语句的执行情况
无论是在try还是在except中,遇到return时,只要设定了finally语句,就会中断当前的return语句,跳转到finally中执行,如果finally中遇到return语句,就直接返回, ...
- JAVA 调用exe程序执行对应的文件 (个人用于编译Java文件)
需求: 需要利用Java程序,来调用计算机本身的黑窗口,来将特定的Java文件编译成对应的字节码文件. 实现思路: 通过调用Java的Runtime类,每个 Java 应用程序都有一个 Runtime ...
- 周末学习笔记——day02(带参装饰器,wraps修改文档注释,三元表达式,列表字典推导式,迭代器,生成器,枚举对象,递归)
一,复习 ''' 1.函数的参数:实参与形参 形参:定义函数()中出现的参数 实参:调用函数()中出现的参数 形参拿到实参的值,如果整体赋值(自己改变存放值的地址),实参不会改变,(可变类型)如果修改 ...
- scala的多种集合的使用(4)之列表List(ListBuffer)的操作
1.List列表的创建和添加元素 1)最常见的创建list的方式之一. scala> val list = 1 :: 2 :: 3 :: Nil list: List[Int] = List(1 ...
- eplan图框制作
1. 首先,新建一个原理图项目 2. 新建图框.选择“工具”→“主数据”→“图框”→“新建” 在“文件名”中输入文件名,保存. 3.添加新建图框属性选项.选中“新建符号*”,添加选项 4. 设置图框的 ...
- OSI七层模型的每一层都有哪些协议
TCP/IP: 数据链路层:ARP,RARP 网络层: IP,ICMP,IGMP 传输层:TCP ,UDP,UGP 应用层:Telnet,FTP,SMTP,SNMP. OSI: 物理层:EIA/TIA ...
- linux ps aux 各列内容说明
[root@zabbix3 ~]# ps auxUSER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMANDroot ...
- Linux centos nginx下载安装初步
下载源码包解压编译 1.下载 # wget http://nginx.org/download/nginx-1.9.9.tar.gz 2.解压 # tar xvf nginx-1.9.9.tar.gz ...