用Python实现的数据结构与算法:基本搜索
一、顺序搜索
顺序搜索 是最简单直观的搜索方法:从列表开头到末尾,逐个比较待搜索项与列表中的项,直到找到目标项(搜索成功)或者 超出搜索范围 (搜索失败)。
根据列表中的项是否按顺序排列,可以将列表分为 无序列表 和 有序列表。对于 无序列表,超出搜索范围 是指越过列表的末尾;对于 有序列表,超过搜索范围 是指进入列表中大于目标项的区域(发生在目标项小于列表末尾项时)或者指越过列表的末尾(发生在目标项大于列表末尾项时)。
1、无序列表
在无序列表中进行顺序搜索的情况如图所示:
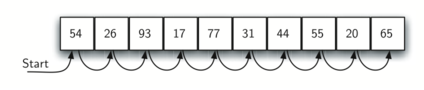
def sequentialSearch(items, target):
for item in items:
if item == target:
return True
return False
2、有序列表
在有序列表中进行顺序搜索的情况如图所示:

def orderedSequentialSearch(items, target):
for item in items:
if item == target:
return True
elif item > target:
break
return False
二、二分搜索
实际上,上述orderedSequentialSearch算法并没有很好地利用有序列表的特点。
二分搜索 充分利用了有序列表的优势,该算法的思路非常巧妙:在原列表中,将目标项(target)与列表中间项(middle)进行对比,如果target等于middle,则搜索成功;如果target小于middle,则在middle的左半列表中继续搜索;如果target大于middle,则在middle的右半列表中继续搜索。
在有序列表中进行二分搜索的情况如图所示:
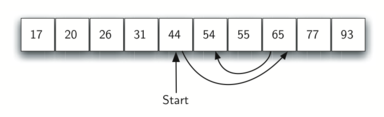
根据实现方式的不同,二分搜索算法可以分为迭代版本和递归版本两种:
1、迭代版本
def iterativeBinarySearch(items, target):
first = 0
last = len(items) - 1
while first <= last:
middle = (first + last) // 2
if target == items[middle]:
return True
elif target < items[middle]:
last = middle - 1
else:
first = middle + 1
return False
2、递归版本
def recursiveBinarySearch(items, target):
if len(items) == 0:
return False
else:
middle = len(items) // 2
if target == items[middle]:
return True
elif target < items[middle]:
return recursiveBinarySearch(items[:middle], target)
else:
return recursiveBinarySearch(items[middle+1:], target)
三、性能比较
上述搜索算法的时间复杂度如下所示:
搜索算法 时间复杂度
-----------------------------------
sequentialSearch O(n)
-----------------------------------
orderedSequentialSearch O(n)
-----------------------------------
iterativeBinarySearch O(log n)
-----------------------------------
recursiveBinarySearch O(log n)
-----------------------------------
in O(n)
可以看出,二分搜索 的性能要优于 顺序搜索。
值得注意的是,Python的成员操作符 in 的时间复杂度是O(n),不难猜出,操作符 in 实际采用的是 顺序搜索 算法。
四、算法测试
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def test_print(algorithm, listname, target):
print(' %d is%s in %s' % (target, '' if algorithm(eval(listname), target) else ' not', listname))
if __name__ == '__main__':
testlist = [1, 2, 32, 8, 17, 19, 42, 13, 0]
orderedlist = sorted(testlist)
print('sequentialSearch:')
test_print(sequentialSearch, 'testlist', 3)
test_print(sequentialSearch, 'testlist', 13)
print('orderedSequentialSearch:')
test_print(orderedSequentialSearch, 'orderedlist', 3)
test_print(orderedSequentialSearch, 'orderedlist', 13)
print('iterativeBinarySearch:')
test_print(iterativeBinarySearch, 'orderedlist', 3)
test_print(iterativeBinarySearch, 'orderedlist', 13)
print('recursiveBinarySearch:')
test_print(recursiveBinarySearch, 'orderedlist', 3)
test_print(recursiveBinarySearch, 'orderedlist', 13)
运行结果:
$ python testbasicsearch.py
sequentialSearch:
3 is not in testlist
13 is in testlist
orderedSequentialSearch:
3 is not in orderedlist
13 is in orderedlist
iterativeBinarySearch:
3 is not in orderedlist
13 is in orderedlist
recursiveBinarySearch:
3 is not in orderedlist
13 is in orderedlist
用Python实现的数据结构与算法:基本搜索的更多相关文章
- 用Python实现的数据结构与算法:开篇
一.概述 用Python实现的数据结构与算法 涵盖了常用的数据结构与算法(全部由Python语言实现),是 Problem Solving with Algorithms and Data Struc ...
- Python实现的数据结构与算法之队列详解
本文实例讲述了Python实现的数据结构与算法之队列.分享给大家供大家参考.具体分析如下: 一.概述 队列(Queue)是一种先进先出(FIFO)的线性数据结构,插入操作在队尾(rear)进行,删除操 ...
- 用python语言讲解数据结构与算法
写在前面的话:关于数据结构与算法讲解的书籍很多,但是用python语言去实现的不是很多,最近有幸看到一本这样的书籍,由Brad Miller and David Ranum编写的<Problem ...
- python 下的数据结构与算法---8:哈希一下【dict与set的实现】
少年,不知道你好记不记得第三篇文章讲python内建数据结构的方法及其时间复杂度时里面关于dict与set的时间复杂度[为何访问元素为O(1)]原理我说后面讲吗?其实就是这篇文章讲啦. 目录: 一:H ...
- python 下的数据结构与算法---1:让一切从无关开始
这段时间把<Data Structure and Algorithms with python>以及<Problem Solving with Algorithms and Dat ...
- 用Python实现的数据结构与算法:堆栈
一.概述 堆栈(Stack)是一种后进先出(LIFO)的线性数据结构,对堆栈的插入和删除操作都只能在栈顶(top)进行. 二.ADT 堆栈ADT(抽象数据类型)一般提供以下接口: Stack() 创建 ...
- Python中的数据结构和算法
一.算法 1.算法的时间复杂度 大 O 记法,是描述算法复杂度的符号O(1) 常数复杂度,最快速的算法. 取数组第 1000000 个元素 字典和集合的存取都是 O(1) 数组的存取是 O(1) O( ...
- python 下的数据结构与算法---4:线形数据结构,栈,队列,双端队列,列表
目录: 前言 1:栈 1.1:栈的实现 1.2:栈的应用: 1.2.1:检验数学表达式的括号匹配 1.2.2:将十进制数转化为任意进制 1.2.3:后置表达式的生成及其计算 2:队列 2.1:队列的实 ...
- python 下的数据结构与算法---3:python内建数据结构的方法及其时间复杂度
目录 一:python内部数据类型分类 二:各数据结构 一:python内部数据类型分类 这里有个很重要的东西要先提醒注意一下:原子性数据类型和非原子性数据类型的区别 Python内部数据从某种形式上 ...
- python 下的数据结构与算法---2:大O符号与常用算法和数据结构的复杂度速查表
目录: 一:大O记法 二:各函数高阶比较 三:常用算法和数据结构的复杂度速查表 四:常见的logn是怎么来的 一:大O记法 算法复杂度记法有很多种,其中最常用的就是Big O notation(大O记 ...
随机推荐
- [C++]值传递和引用传递
概念 在定义函数时函数括号中的变量名成为形式参数,简称形参或虚拟参数: 在主调函数中调用一个函数时,该函数括号中的参数名称为实际参数,简称实参,实参可以是常量.变量或表达式. 注意: C语言中实参和形 ...
- 木马分析出现python语言,360的安全人员不禁感叹还有这种操作?
几年前,敲诈者木马还是一个默默无闻的木马种类.然而,由于其极强的破坏力和直接且丰厚的财富回报,敲诈者木马这几年已经一跃成为曝光率最高的木马类型——甚至超越了盗号木马.远控木马.网购木马这传统三强.与此 ...
- Java创建对象的动作分析
一.Java创建对象时将对象存放到内存的堆中. 创建对象时先执行类成员的初始化,然后才会调用构造函数初始化对象, package com.test.createsort; public class C ...
- NO.7:自学python之路------类的方法、异常处理、socket网络编程
引言 我visual studio 2017就算体积巨大.启动巨慢.功能简陋也不会安装PyCharm的,嘿呀,真香.好吧,为了实现socket网络编程,更换了软件. 正文 静态方法 只是在名义上归类管 ...
- 备份win10的驱动程序
目录 折腾历程 怎么备份驱动 备份的驱动如何使用 关于驱动程序的OS兼容性 驱动程序的其他安装方式 1.折腾历程 从闲鱼上收了一个INSIGNIA的二合一笔记本,w7100,因原装win10性能不行自 ...
- flex布局时,内容区域自适应高度
页面元素高度固定,中间的元素需要撑满屏幕,或者内容多时显示滚动条时,我们要把父元素设置为height:100vh <div class="parent"> <di ...
- 150314 解决老师给二柱子出的问题 之 ver1.0
一个晚上的成果,效果捉鸡,代码很乱.暂定ver1.0 //Powered by LZR! 2015.3.14#include<iostream> #include<stdio.h&g ...
- sqlserver结束和监视耗时的sql
在对象资源管理器中右击服务器地址选择“活动和监视器”. 点击最近耗费大量资源的查询
- VMware上配置DPDK环境并运行实例程序
1. 在虚拟机VMware上配置环境 VMware安装:http://www.zdfans.com/html/5928.html Ubuntu:https://www.ubuntu.com/downl ...
- 《TCP/IP 详解 卷1:协议》第 11 章:名称解析和域名系统
引言 到目前为止,我们使用 IP 地址来研究参与网络的主机.对于大众来说,这些地址太繁琐且难以记忆.为了使用如 TCP 和 IP 等协议,主机名称通过名为名称解析(name resolution)的过 ...