用Python实现的数据结构与算法:基本搜索
一、顺序搜索
顺序搜索 是最简单直观的搜索方法:从列表开头到末尾,逐个比较待搜索项与列表中的项,直到找到目标项(搜索成功)或者 超出搜索范围 (搜索失败)。
根据列表中的项是否按顺序排列,可以将列表分为 无序列表 和 有序列表。对于 无序列表,超出搜索范围 是指越过列表的末尾;对于 有序列表,超过搜索范围 是指进入列表中大于目标项的区域(发生在目标项小于列表末尾项时)或者指越过列表的末尾(发生在目标项大于列表末尾项时)。
1、无序列表
在无序列表中进行顺序搜索的情况如图所示:
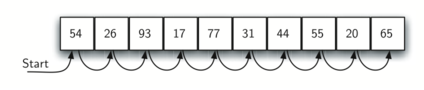
def sequentialSearch(items, target):
for item in items:
if item == target:
return True
return False
2、有序列表
在有序列表中进行顺序搜索的情况如图所示:

def orderedSequentialSearch(items, target):
for item in items:
if item == target:
return True
elif item > target:
break
return False
二、二分搜索
实际上,上述orderedSequentialSearch算法并没有很好地利用有序列表的特点。
二分搜索 充分利用了有序列表的优势,该算法的思路非常巧妙:在原列表中,将目标项(target)与列表中间项(middle)进行对比,如果target等于middle,则搜索成功;如果target小于middle,则在middle的左半列表中继续搜索;如果target大于middle,则在middle的右半列表中继续搜索。
在有序列表中进行二分搜索的情况如图所示:
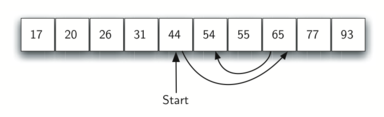
根据实现方式的不同,二分搜索算法可以分为迭代版本和递归版本两种:
1、迭代版本
def iterativeBinarySearch(items, target):
first = 0
last = len(items) - 1
while first <= last:
middle = (first + last) // 2
if target == items[middle]:
return True
elif target < items[middle]:
last = middle - 1
else:
first = middle + 1
return False
2、递归版本
def recursiveBinarySearch(items, target):
if len(items) == 0:
return False
else:
middle = len(items) // 2
if target == items[middle]:
return True
elif target < items[middle]:
return recursiveBinarySearch(items[:middle], target)
else:
return recursiveBinarySearch(items[middle+1:], target)
三、性能比较
上述搜索算法的时间复杂度如下所示:
搜索算法 时间复杂度
-----------------------------------
sequentialSearch O(n)
-----------------------------------
orderedSequentialSearch O(n)
-----------------------------------
iterativeBinarySearch O(log n)
-----------------------------------
recursiveBinarySearch O(log n)
-----------------------------------
in O(n)
可以看出,二分搜索 的性能要优于 顺序搜索。
值得注意的是,Python的成员操作符 in 的时间复杂度是O(n),不难猜出,操作符 in 实际采用的是 顺序搜索 算法。
四、算法测试
#!/usr/bin/env python
# -*- coding: utf-8 -*-
def test_print(algorithm, listname, target):
print(' %d is%s in %s' % (target, '' if algorithm(eval(listname), target) else ' not', listname))
if __name__ == '__main__':
testlist = [1, 2, 32, 8, 17, 19, 42, 13, 0]
orderedlist = sorted(testlist)
print('sequentialSearch:')
test_print(sequentialSearch, 'testlist', 3)
test_print(sequentialSearch, 'testlist', 13)
print('orderedSequentialSearch:')
test_print(orderedSequentialSearch, 'orderedlist', 3)
test_print(orderedSequentialSearch, 'orderedlist', 13)
print('iterativeBinarySearch:')
test_print(iterativeBinarySearch, 'orderedlist', 3)
test_print(iterativeBinarySearch, 'orderedlist', 13)
print('recursiveBinarySearch:')
test_print(recursiveBinarySearch, 'orderedlist', 3)
test_print(recursiveBinarySearch, 'orderedlist', 13)
运行结果:
$ python testbasicsearch.py
sequentialSearch:
3 is not in testlist
13 is in testlist
orderedSequentialSearch:
3 is not in orderedlist
13 is in orderedlist
iterativeBinarySearch:
3 is not in orderedlist
13 is in orderedlist
recursiveBinarySearch:
3 is not in orderedlist
13 is in orderedlist
用Python实现的数据结构与算法:基本搜索的更多相关文章
- 用Python实现的数据结构与算法:开篇
一.概述 用Python实现的数据结构与算法 涵盖了常用的数据结构与算法(全部由Python语言实现),是 Problem Solving with Algorithms and Data Struc ...
- Python实现的数据结构与算法之队列详解
本文实例讲述了Python实现的数据结构与算法之队列.分享给大家供大家参考.具体分析如下: 一.概述 队列(Queue)是一种先进先出(FIFO)的线性数据结构,插入操作在队尾(rear)进行,删除操 ...
- 用python语言讲解数据结构与算法
写在前面的话:关于数据结构与算法讲解的书籍很多,但是用python语言去实现的不是很多,最近有幸看到一本这样的书籍,由Brad Miller and David Ranum编写的<Problem ...
- python 下的数据结构与算法---8:哈希一下【dict与set的实现】
少年,不知道你好记不记得第三篇文章讲python内建数据结构的方法及其时间复杂度时里面关于dict与set的时间复杂度[为何访问元素为O(1)]原理我说后面讲吗?其实就是这篇文章讲啦. 目录: 一:H ...
- python 下的数据结构与算法---1:让一切从无关开始
这段时间把<Data Structure and Algorithms with python>以及<Problem Solving with Algorithms and Dat ...
- 用Python实现的数据结构与算法:堆栈
一.概述 堆栈(Stack)是一种后进先出(LIFO)的线性数据结构,对堆栈的插入和删除操作都只能在栈顶(top)进行. 二.ADT 堆栈ADT(抽象数据类型)一般提供以下接口: Stack() 创建 ...
- Python中的数据结构和算法
一.算法 1.算法的时间复杂度 大 O 记法,是描述算法复杂度的符号O(1) 常数复杂度,最快速的算法. 取数组第 1000000 个元素 字典和集合的存取都是 O(1) 数组的存取是 O(1) O( ...
- python 下的数据结构与算法---4:线形数据结构,栈,队列,双端队列,列表
目录: 前言 1:栈 1.1:栈的实现 1.2:栈的应用: 1.2.1:检验数学表达式的括号匹配 1.2.2:将十进制数转化为任意进制 1.2.3:后置表达式的生成及其计算 2:队列 2.1:队列的实 ...
- python 下的数据结构与算法---3:python内建数据结构的方法及其时间复杂度
目录 一:python内部数据类型分类 二:各数据结构 一:python内部数据类型分类 这里有个很重要的东西要先提醒注意一下:原子性数据类型和非原子性数据类型的区别 Python内部数据从某种形式上 ...
- python 下的数据结构与算法---2:大O符号与常用算法和数据结构的复杂度速查表
目录: 一:大O记法 二:各函数高阶比较 三:常用算法和数据结构的复杂度速查表 四:常见的logn是怎么来的 一:大O记法 算法复杂度记法有很多种,其中最常用的就是Big O notation(大O记 ...
随机推荐
- Gaussian Models
Warming Up Before we talk about multivariate Gaussian, let's first review univariate Gaussian, which ...
- git查看添加删除远程仓库
查看远程仓库 git remote -v 删除远程仓库 git remote remove origin 添加远程仓库 git remote add origin 仓库地址 关联远程分支 重新关联远程 ...
- 02-matplotlib-散点图
import numpy as np import matplotlib.pyplot as plt ''' 散点图显示两组数据的值,每个点的坐标位置的值决定 用户观察两种变量的相关性: 正相关 负相 ...
- Python数据分析工具库-Numpy 数组支持库(一)
1 Numpy数组 在Python中有类似数组功能的数据结构,比如list,但在数据量大时,list的运行速度便不尽如意,Numpy(Numerical Python)提供了真正的数组功能,以及对数据 ...
- LeetCode 566. Reshape the Matrix (C++)
题目: In MATLAB, there is a very useful function called 'reshape', which can reshape a matrix into a n ...
- Notes of Daily Scrum Meeting(11.17)
Notes of Daily Scrum Meeting(11.17) 今天是第四周的周一,也就是说距离最后发布也只剩下一周的时间,但我们的工程里面还有很多的问题没有解决,我关注过 其他一两个小组,他 ...
- 5233杨光--Linux第二次实验
实验说明 1. 环境登录 无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 若不小心登出后,直接刷新页面即可 2. 环境使用 完成实验后可以点击桌面上方的“实验截图”保存并分享实 ...
- 安装AndroidJDK的坑
最近公司要用weex了,先开始搭一下环境,真的都是坑,写下来大家引以为鉴,我踩坑三天的后果. 首先要安装JavaJDK这个过程就不写了都是程序员网上搜索一下很多,注意找论坛上最新的帖子来看,这里有一个 ...
- 1001.A+B Format (20) 解题
代码入口(https://github.com/NSDie/object-oriented) 这题的解题思路我有两个: 第一个是两个数字相加然后判断位数,因为题目限制了范围1000000的绝对值以内嘛 ...
- KEIL C51程序中如何嵌入汇编
模块内接口:使用如下标志符:#pragma asm汇编语句#pragma endasm注意:如果在c51程序中使用了汇编语言,注意在Keil编译器中需要激活Properties中的“Generate ...