SQL 中的好习惯和坏习惯
在程序员日常的工作中,SQL可以说不可避免的,高效的SQL可以带来更加愉悦的体验。好的SQL书写习惯会给我们的工作带来极大的好处。简单总结下SQL的好习惯和坏习惯。
- IN和NOT IN 操作符
编码中有的人很喜欢用In,觉得这样很省事,开发快捷,殊不知这样会给自己埋下一个雷,一般不建议在程序中使用In或Not In,推荐使用EXISTS代替In,NOT EXISTS 代替来Not IN,这里并不是说谁的执行效率就一定高,我在我博客里面其他的文章也提过In 或Not In的替代方法。欢迎拍砖。顺便提一句。使用EXISTS比使用IN 或Not In IO方面开销要小一些的。大家可以通过SET STATISTICS IO ON来查看IO的相关信息.
- IS NULL 或IS NOT NULL操作
索引是不索引空值的,所以这样的操作不能使用索引,可以用其他的办法处理,例如:数字类型,判断大于0,字符串类型设置一个默认值,判断是否等于默认值即可
- <> 操作符(不等于)
在网上看到有的文章说【不等于】操作符是永远不会用到索引的,对它的处理只会产生全表扫描。其实这个是不一定的,要根据具体的情况来做分析。下面我们以实际的例子来看一下:
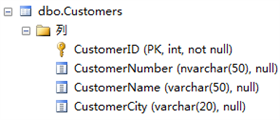
表结构如上图,索引情况:CustomerID是主键,有一个聚集索引,此外在CustomerName字段上建有非聚集索引,包含了[CustomerID],[CustomerCity]
我们来看下具体的查询语句:
SELECT TOP 10 CustomerID, CustomerName,CustomerCity FROM dbo.Customers WHERE CustomerName<>'1'
很普通的一个查询语句,照网上的说法,这个查询采用了<>操作符索引应当是用不上的,可是我们来看下该查询语句对应的查询计划:

【图-A】
在查询计划中我们可以很清楚的看到,该查询是用到了索引查找的,这是为什么呢?我想一方面是可能是新版本的SQL Server对<>做了优化,另一方面是建立了合适的索引。我们来验证一下,首先我们来干掉CustomerName上的覆盖索引,并重新建立索引:
DROP INDEX [INDEX_CustomerName] ON [dbo].[Customers]
CREATE INDEX [INDEX_CustomerName] ON [dbo].[Customers] (CustomerName ASC)
依旧是上面的查询我们再来看下这个时候的查询计划:

由索引的查找变成了聚焦索引的扫描(和表扫表差不多了),CustomerName上的索引失效了,用的是主键的索引。我们来改下上面的查询:
SELECT TOP 10 CustomerID, CustomerName FROM dbo.Customers WHERE CustomerName<>'1'
去掉一列CustomerCity这个时候的查询计划又回到了【图-A】中的状态,由此可见索引的覆盖是很重要的,能更合理的使用索引,而且可以降低IO的开销哦。接下来我给大家看一个有意思的事情:
场景如下:
【查询B】SELECT TOP 10 CustomerID FROM dbo.Customers WHERE CustomerID<>1
【查询C】SELECT TOP 10 CustomerName FROM dbo.Customers WHERE CustomerName<>'1'
两个查询,索引的情况也很简单,CustomerID,CustomerName分别建有聚集索引和非聚集索引,大家先猜下上面的两个查询,那一个可以用到索引的查找呢?

没错,你没有看错【查询B】没有使用到索引查找,而【查询C】使用的是索引的查找,也就是说聚焦索引在<>操作符下竟然失效了,而非聚焦索引竟然依然可以使用。这是为什么呢,欢迎大家给出自己的意见
- 用全文搜索搜索文本数据,取代like搜索
很遗憾全文索引我没有具体的使用过,这个仅摘录下网上大侠的语录,:)
全文搜索始终优于like搜索:
(1)全文搜索让你可以实现like不能完成的复杂搜索,如搜索一个单词或一个短语,搜索一个与另一个单词或短语相近的单词或短语,或者是搜索同义词;
(2)实现全文搜索比实现like搜索更容易(特别是复杂的搜索)
- 在查询中不要使用 select *
为什么不能使用,地球人都知道,但是很多人都习惯这样用,要明白能省就省,而且这样查询数据库不能利用“覆盖索引”了
- UPDATE操作不要拆成DELETE操作+INSERT操作的形式
这个真的不建议
- 尽量不要写没有意义的查询条件
在编码中我们有的时候为了省事,经常会写类似这样的条件1=1,这真的不是一个好习惯
- 避免使用临时表
推荐使用表变量,因为其驻扎在内存中,因此速度比临时表更快,临时表驻扎在TempDb数据库中,消耗IO,并且临时表上的操作需要跨数据库通信,效率会较低,同时应减少跨库的查询操作。
- WHERE使用原则
第一个原则:在where子句中应把最具限制性的条件放在最前面;
第二个原则:where子句中字段的顺序应和索引中字段顺序一致;
第三个原则:where子句中不建议使用函数;
上面的几条随着数据库版本的更新有的已经不在是问题,但是作为一个良好的书写习惯,还是比较推荐的。
- 使用明确的数据类型
我们知道数据类型的转换会对索引的使用造成影响,但是究竟有多大影响呢?可以说一个不恰当的类型转换会使索引完全失效。常有这种情况,我们在应用程序中使用简单的查询/表函数/存储过程访问一个体积很大的表,使用了索引,也没有多于的函数、计算,但还是执行了很长时间。这个时候可以考虑下是否查询字段的类型发生了变化。Fox,表字段的类型是varchar,但是传入的参数定义的类型是nvarchar,由于nvarchar的级别比varchar更高一些,在查询执行的时候需要进行一个转换,由低到高的转换,而这种转换会导致字段所在的索引失效,所以查询的效率也就得不到提升。有的童鞋会说了,我们经常有字段类型的转换啊,没觉的慢啊,fox,字段是datetime类型的,参数一直写成’2013-12-12 15:48’啊,忘记说了,当类型转换是由高到低转换时,字段所在的索引不受到影响。看一个实际的例子:还是以上面的表Customers为例,这次我们将Customers的记录增加到100W,为了配合这个实验,我们建立一个简单的存储过程
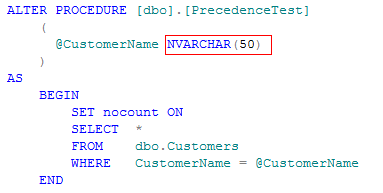
注意这是一个下不正确的使用,注意参数类型被定义为nvarchar,而字段类型是varchar。我们来看下这个时候的执行计划是怎么个样子的:

为了方便对比,我们将存储过程的参数改为varchar,也就是改成和表字段类型相匹配,我们再来看下执行计划:

发现什么了没有?比较2个图,我们可以看到上面的图中完全没有用到CustomerName 索引,进行了索引的扫描,一个字段类型的不匹配竟然导致了索引的失效,太划不来了。
按照一定的次序来访问你的表
SQL是基于事务的,就必然会存在资源的争夺,锁机制得到了很好的运用。在访问数据表时,最好所有的多表查询都是按照固定的顺序来进行的,假设你先锁住表A,再锁住表B,那么在所有的存储过程中都要按照这个顺序来锁定它们。如果你(不经意的)在某个存储过程中先锁定表B,再锁定表A,这可能就会导致一个死锁。如果锁定顺序没有被预先详细的设计好,死锁很难被发现,这会不会是你的一个灾难呢?
- 最大程度使用批处理
一次更新多条记录比分多次更新每次一条要快的多,很常见的一个场景就是Update From.
- OR的使用
用OR的字句可以分解成多个查询,并且通过UNION ALL 做表连接,这样才能在查询中更加充分的使用到索引。
- 二进制数据数据的存储
在特定的情况下,需要将二进制的数据插入数据库中,推荐使用存储过程,千万不要用内嵌INsert来插入。因为这样应用程序首先将二进制值转换成字符串(数据大小会变大约2倍),服务器接收到字符后又将它转换成二进制值.造成不必要的资源浪费。
后续补充~
SQL 中的好习惯和坏习惯的更多相关文章
- 使用Bugfree不应有的坏习惯
Bugfree是一款优秀的bug管理和追踪工具,因此受到不少公司的青睐.但实际的工作中,我发现不少开发或是测试的同事有一些不好的使用习惯,使得我们对Bugfree的利用不够高效.我下面列出使用Bugf ...
- 因为这几个TypeScript代码的坏习惯,同事被罚了500块
作者:Daniel Bartholomae 翻译:疯狂的技术宅 原文链接:https://startup-cto.net/10-bad-typescript-habits-to-break-this- ...
- SQL中減少日志文件大小
SQL中減少日志文件大小 编写人:CC阿爸 2014-6-14 在日常SQL数据库的操作中,常常会出现SQL日志文件超大,大小都超过正常MDF数据库文件,作为一般用户来讲,LDF太大,只会影响服务 ...
- SQL中Round(),Floor(),Ceiling()函数的浅析
项目中的一个功能模块上用到了标量值函数,函数中又有ceiling()函数的用法,自己找了一些资料,对SQL中这几个函数做一个简单的记录,方便自己学习.有不足之处欢迎拍砖补充 1.round()函数遵循 ...
- 关于sql中in 和 exists 的效率问题,in真的效率低吗
原文: http://www.cnblogs.com/AdamLee/p/5054674.html 在网上看到很多关于sql中使用in效率低的问题,于是自己做了测试来验证是否是众人说的那样. 群众: ...
- 学习sql中的排列组合,在园子里搜着看于是。。。
学习sql中的排列组合,在园子里搜着看,看到篇文章,于是自己(新手)用了最最原始的sql去写出来: --需求----B, C, F, M and S住在一座房子的不同楼层.--B 不住顶层.C 不住底 ...
- SQL中distinct的用法
SQL中distinct的用法 1.作用于单列 2.作用于多列 3.COUNT统计 4.distinct必须放在开头 5.其他 在表中,可能会包含重复值.这并不成问题,不过,有时您也许希望仅仅列出 ...
- hibernate中java类的成员变量类型如何映射到SQL中的数据类型变化
hibernate映射文件??.hbm.xml配置映射元素详解--Hibernate映射类型 在从Hibernate的java的成员类型映射到SQL中的数据类型,其内映射方式它满足,SQL可以自己调制 ...
- C#调用SQL中的存储过程中有output参数,存储过程执行过程中返回信息
C#调用SQL中的存储过程中有output参数,类型是字符型的时候一定要指定参数的长度.不然获取到的结果总是只有第一字符.本人就是由于这个原因,折腾了很久.在此记录一下,供大家以后参考! 例如: ...
随机推荐
- .c 文件取为.o文件
$(xxx:%.c=%.o) 即可 例子: $(ALLFILES:%.c=%.o)
- Node.js缓冲器
纯JavaScript是Unicode友好的,但对二进制数据不是很好.当与TCP流或文件系统打交道时,有必要处理字节流. Node提供缓冲器类,它提供实例来存储原始数据相似的一个整数数组,但对应于在V ...
- HDNOIP201206施工方案
HDNOIP201206施工方案 难度级别:A: 运行时间限制:1000ms: 运行空间限制:51200KB: 代码长度限制:2000000B 试题描述 c国边防军在边境某处的阵地是由n个地堡组成的. ...
- P1894セチの祈り
描述 在 Ninian 的花园里,有许多琼花,环绕着中间的凉亭.有 N 片琼花,组成一个环.Ninian 想在凉亭中发动 [セチの祈り] , 需要划分出三个区域的琼花,为了平均,要最大化面积最小的区域 ...
- 数据结构(二维线段树,差分): NOI2012 魔幻棋盘
貌似想复杂了…… #include <iostream> #include <cstring> #include <cstdio> #define mid ((l+ ...
- Python操作Excel_输出所有内容(包含中文)
python 2.7.5代码: # coding=utf-8 import sys import xlrd data=xlrd.open_workbook('D:\\menu.xls') table ...
- HDOJ 2802 F(N)
Problem Description Giving the N, can you tell me the answer of F(N)? Input Each test case contains ...
- Android Proguard
Android Proguard 14 May 2015 语法 -include {filename} 从给定的文件中读取配置参数 -basedirectory {directoryname} 指定基 ...
- 最小生成树——[HAOI2006]聪明的猴子
题目:[HAOI2006]聪明的猴子 描述: [题目描述] 在一个热带雨林中生存着一群猴子,它们以树上的果子为生.昨天下了一场大雨,现在雨过天晴,但整个雨林的地表还是被大水淹没着, 猴子不会游泳,但跳 ...
- N - Find a way
这个专题的最后一道题目了.... 应该说的是有两个人计划去KFC碰头,找出来一个最近的KFC让他们俩见面吧,应该是个比较容易的问题,不过需要注意在一个Bfs里面搜的话,别把两个人弄混乱了....... ...