window配置mongodb集群(副本集)
参数解释:
dbpath:数据存放目录
logpath:日志存放路径
pidfilepath:进程文件,有利于关闭服务
logappend:以追加的方式记录日志(boolean值)
replSet:副本集的名字,每一个副本集名字相同
port:mongodb的端口号
oplogSize:mongodb操作日志文件的最大大小,单位为Mb,默认为硬盘剩余空间的5%
noprealloc:不预先分配存储
fork:以后台方式运行进程(linux使用)
directoryperdb:为每一个数据库按照数据库名建立文件夹存放
health表示副本集中该节点是否正常,0表示不正常,1表示正常
state表示节点的身份,0表示非主节点,1表示主节点
stateStr用于对节点身份进行字符描述,PRIMARY表示主节点,SECONDARY表示副节点
name是副本集节点的ip和端口信息
priority:副本集节点优先权,这个值的范围是0--100,值越大,优先权越高,默认的值是1,假设值是0,那么不能成为primay
arbiterOnly:设置仲裁节点
首先我们先来搭建一个副本集(副本集结构为1个主节点,一个从节点一个仲裁节点)
第一步:我们在本机的1001、1002和1003三个端口上启动三个不同的Mongodb实例;
mongod --port 1001 --dbpath F:/mongos/mongodb1/data --logpath F:/mongos/mongodb1/log/mongodb.log --pidfilepath F:/mongos/mongodb1/mongodb1.pid --replSet test --logappend --directoryperdb
mongod --port 1002 --dbpath F:/mongos/mongodb2/data --logpath F:/mongos/mongodb2/log/mongodb.log --pidfilepath F:/mongos/mongodb2/mongodb2.pid --replSet test --logappend --directoryperdb
mongod --port 1003 --dbpath F:/mongos/mongodb3/data --logpath F:/mongos/mongodb3/log/mongodb.log --pidfilepath F:/mongos/mongodb3/mongodb3.pid --replSet test --logappend --directoryperdb
第二步:登录到1001实例上编写指令,将三个不同的Mongodb实例结合在一起形成一个完整的副本集;
cd F:\mongos\mongodb1\bin
mongo 127.0.0.1:1001
use admin
config_test={_id:"test",members:[
{_id:0,host:"127.0.0.1:1001",priority:1},
{_id:1,host:"127.0.0.1:1002",priority:1},
{_id:2,host:"127.0.0.1:1003",arbiterOnly:true},
]};
这里,members中可以包含多个值,这里列举的就是刚才启动的三个Mongodb实例,并且通过_id字段给副本集起了名字test。
第三步:通过执行下面的命令初始化副本集。
rs.initiate(config_test);
这里使用上面的配置初始化Mongodb副本集。
rs.status()
想查看副本集的状态
到这里搭建起一个由三个Mongodb实例构成的名称为test的副本集了。
副本集现在搭建起来了,那么这个副本集能不能解决我们上面主从模式的两个问题呢?
我们首先从第一个问题开始看,我们将1001端口的Mongodb服务器给关闭,然后我们使用rs.status()命令来查看下,如下所示:
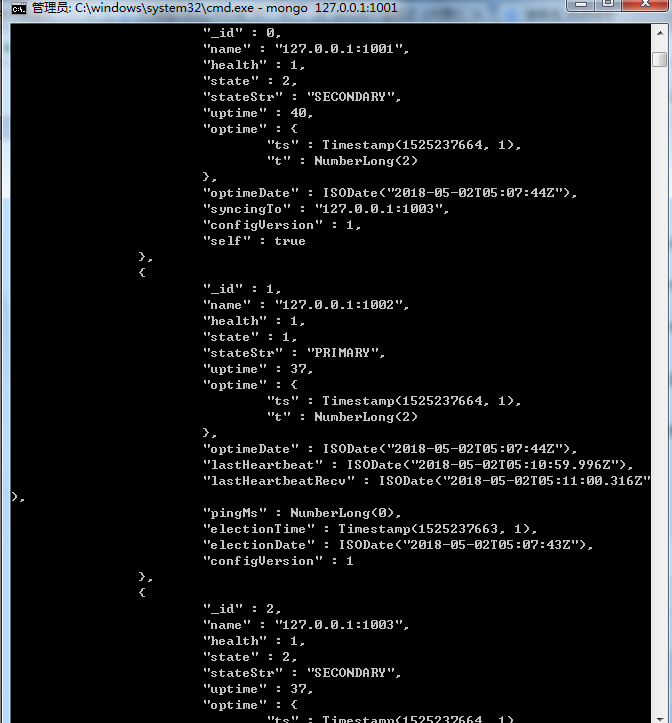
从返回包信息中,可以看到关闭1001端口后,在副本集节点的状态中该节点是不可达的,重新选取产生的主节点是1002端口上启动的Mongodb实例,选举过程是这样的,当主节点挂掉之后,其他节点可以发起选举行为,只要在选举过程中某个节点得到副本集节点数一半以上的选票并且没有节点投反对票,那么该节点就可以成为主节点。(参数注释请看开始位置)在1001端口上的Mongodb实例挂掉之后,1002成为了新的主节点,可以实现故障自动切换。
至于第二个问题,那就是主节点负责所有的读写操作造成主节点压力较大,那么在副本集中如何解决这个问题了呢?正常情况下,我们在Java中访问副本集是这样的,如下所示:
public class TestMongoDBReplSet {
public static void main(String[] args) {
try {
List<ServerAddress> addresses = new ArrayList<ServerAddress>();
ServerAddress address1 = new ServerAddress("127.0.0.1",1001);
ServerAddress address2 = new ServerAddress("127.0.0.1",1002);
ServerAddress address3 = new ServerAddress("127.0.0.1",1003);
addresses.add(address1);
addresses.add(address2);
addresses.add(address3);
MongoClient client = new MongoClient(addresses);
DB db = client.getDB( "testdb");
DBCollection coll = db.getCollection( "testdb");
// 插入
BasicDBObject object = new BasicDBObject();
object.append("userid","001");
coll.insert(object);
DBCursor dbCursor = coll.find();
while (dbCursor.hasNext()) {
DBObject dbObject = dbCursor.next();
System. out.println(dbObject.toString());
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
但是,上面不能做到在副本集中读写压力分散,其实在代码层面,我们可以设置再访问副本集的时候只从副节点上读取数据。副本集读写分离结构如下图所示:
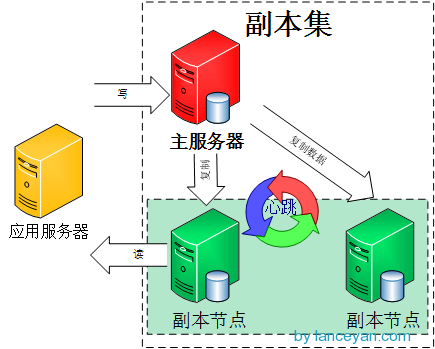
为了在副本集上实现读写分离,我们需要实现以下两步:
(1)在副本节点上设置setSlaveOk;
(2)代码层面,在读操作过程中设置从副本节点读取数据,如下所示:
public class TestMongoDBReplSet {
public static void main(String[] args) {
try {
List<ServerAddress> addresses = new ArrayList<ServerAddress>();
ServerAddress address1 = new ServerAddress("127.0.0.1",1001);
ServerAddress address2 = new ServerAddress("127.0.0.1",1002);
ServerAddress address3 = new ServerAddress("127.0.0.1",1003);
addresses.add(address1);
addresses.add(address2);
addresses.add(address3);
MongoClient client = new MongoClient(addresses);
DB db = client.getDB( "test");
DBCollection coll = db.getCollection( "test");
BasicDBObject object = new BasicDBObject();
object.append("userid","001");
ReadPreference preference = ReadPreference.secondary();
DBObject dbObject = coll.findOne(object, null , preference);
System. out .println(dbObject);
} catch (Exception e) {
e.printStackTrace();
}
}
}
读参数除了secondary以外,还有其他几个参数可以使用,他们的含义分别如下所示:
primary:默认参数,只从主节点上进行读取操作;
primaryPreferred:大部分从主节点上读取数据,只有主节点不可用时从secondary节点读取数据。
secondary:只从secondary节点上进行读取操作,存在的问题是secondary节点的数据会比primary节点数据“旧”。
secondaryPreferred:优先从secondary节点进行读取操作,secondary节点不可用时从主节点读取数据;
nearest:不管是主节点、secondary节点,从网络延迟最低的节点上读取数据。
window配置mongodb集群(副本集)的更多相关文章
- Mongodb分布式集群副本集+分片
目录 简介 1. 副本集 1.1 MongoDB选举的原理 1.2 复制过程 2. 分片技术 2.1 角色 2.2 分片的片键 2.3 片键分类 环境介绍 1.获取软件包 2.创建路由.配置.分片等的 ...
- MongoDB 高可用集群副本集+分片搭建
MongoDB 高可用集群搭建 一.架构概况 192.168.150.129192.168.150.130192.168.150.131 参考文档:https://www.cnblogs.com/va ...
- 搭建高可用mongodb集群—— 副本集
转自:http://www.lanceyan.com/tech/mongodb/mongodb_repset1.html 在上一篇文章<搭建高可用MongoDB集群(一)——配置MongoDB& ...
- MongoDB集群——副本集
1. 副本集的结构及原理 副本集包括三种节点:主节点.从节点.仲裁节点.主节点负责处理客户端请求,读.写数据, 记录在其上所有操作的oplog: 从节点定期轮询主节点获取这些操作,然后对自己的数据副本 ...
- MongoDB 3.4 分片集群副本集 认证
连接到router所在的MongoDB Shell 我本机端口设置在50000上 mongo --port 接下来的流程和普通数据库添加用户权限一样 db.createUser({user:&quo ...
- kubernetes上安装MongoDB-3.6.5集群副本集方式
一.安装部署: 想直接一步创建集群的小伙伴直接按以下步骤安装(再往后是记录自己出过的错): 1.生成docker镜像: docker build -t 144.202.127.156/library/ ...
- mongodb系列之---副本集配置与说明
在配置副本集之前,我们先来了解一些关于副本集的知识. 1,副本集的原理 副本集的原理与主从很相似,唯一不同的是,在主节点出现故障的时候,主从配置的从服务器不会自动的变为主服务器,而是要通过手动修改配置 ...
- MongoDB副本集配置系列三:副本集的认证方式
1:副本集配置参考这篇博客: http://www.cnblogs.com/xiaoit/p/4478951.html 2:副本集的认证 假设有两台机器已经配置好了副本集(副本集罪一般最少3台机器,这 ...
- MongoDB高可用集群+MMS集群监控搭建
备注: mongodb学习资料 http://www.runoob.com/mongodb/mongodb-tutorial.html 一. 集群的三个组件: mongos(query routers ...
随机推荐
- Dynamics CRM 在Visual Studio中开启XML编辑的智能提示
对于.net开发人员来说Visual Studio这一开发工具自然是再熟悉不过,它强大的功能给我们的编程带来了极大的方便,代码智能提示就属其中一项. 在Dynamic CRM的开发中在各种工具出来之前 ...
- 从二进制数据流中构造GDAL可以读取的图像数据(C#)
在上一篇博客中,讲了一下使用GDAL从文件流中构造一个GDAL可以识别的数据来进行处理.原以为这个接口在C#中没有,仔细看了下GDAL库中源码,发现C#版本也有类似的函数,下面是GDAL库中的一个C# ...
- android开发之AlertDialog点击按钮之后不消失
最近有这样一个需求,我需要用户在一个弹出框里输入密码来验证,验证成功当然好说,但是如果验证失败则需要把alertdialog的标题改为"密码错误,请重新输入",并且这个alertd ...
- JDK8帮助文档生成-笔记
JDK8 出来了,以前习惯了使用.CHM文件来查看API,现在想也这样,这里自己制作了一下,记录一下. 1.需要的工具: ①JD2CHM;②API文档③HTMLlHelper 遇到的问题主要是不知道去 ...
- JAVA之旅(二十七)——字节流的缓冲区,拷贝mp3,自定义字节流缓冲区,读取键盘录入,转换流InputStreamReader,写入转换流,流操作的规律
JAVA之旅(二十七)--字节流的缓冲区,拷贝mp3,自定义字节流缓冲区,读取键盘录入,转换流InputStreamReader,写入转换流,流操作的规律 我们继续来聊聊I/O 一.字节流的缓冲区 这 ...
- (国内)完美下载Android源码Ubuntu版
今天写的文章莫名奇妙的没了,所以再重新写一篇. 首先,为了方便起见,我已经将系统更换成里Ubuntu,因为官方推荐使用这个Linux发行版.先来一张系统的截图: Ubuntu的版本是16.04(推荐用 ...
- (国内)完美下载android源代码(文章已经丢失)
刚刚文章莫名其妙的丢了,我重写了一篇,http://blog.csdn.net/song19891121/article/details/50099857 我们在很多时候需要下载android源代码进 ...
- catalina.sh设置JAVA_HOME后还无法解决更换JDK有关问题
catalina.sh设置JAVA_HOME后还无法解决更换JDK问题 表示linux已经安装默认的JDK,需要查找配置文件,更换JDK路径为指定的路径 在root用户下 使用echo $PATH 查 ...
- ROS(indigo)机器人操作系统学习有趣丰富的Gazebo仿真示例evarobot
一直在寻找一个示例可以将ROS学习中常用的基础内容大部分都包含进去,最好还包括Gazebo仿真, 这样即使没有硬件设备,也可以很好的学习ROS相关内容,但又必须有对应的硬件,便于后续研究. 这里,介绍 ...
- android TabLayout实现京东详情效果
Google在2015的IO大会上,给我们带来了更加详细的Material Design设计规范,同时,也给我们带来了全新的Android Design Support Library,在这个supp ...