MySQL_执行计划详细说明
1 简要说明

|
id
|
表格查询的顺序编号。
|
降序查看,id相同的从上到下查查看。
id可以为null ,当table为( union ,m,n )类型的时候,id为null,这个时候,id的顺序为 m跟n的后面。
|
|
select_type
|
查询的方式
|
下文详细说明。
|
|
table
|
表格名称
|
表名,别名,( union m,n )。
|
|
partitions
|
分区名称
|
查询使用到表分区的分区名。
|
|
type
|
表连接的类型
|
下文详细说明。
|
|
possible_keys
|
可能使用到的索引
|
这里的索引只是可能会有到,实际不一定会用到。
|
|
key
|
使用到的索引
|
实际使用的索引。
|
|
key_len
|
使用到索引的长度
|
比如多列索引,只用到最左的一列,那么使用到索引的长度则为该列的长度,故该值不一定等于 key 列索引的长度。
|
|
ref
|
谓词的关联信息
|
当 join type 为 const、eq_ref 或者 ref 时,谓词的关联信息。
可能为 :null(非 const \ eq_ref \ ref join type 时)、const(常量)、关联的谓词列名。
|
|
rows
|
扫描的行数
|
该表格扫描到的行数。这里注意在mysql里边是嵌套链接,所以,需要把所有rows相乘就会得到查询数据行关联的次数
|
|
filtered
|
实际显示行数占扫描rows的比例
|
实际显示的行数 = rows * filtered / 100
|
|
extra
|
特性使用
|
|
2 SELECT_TYPE
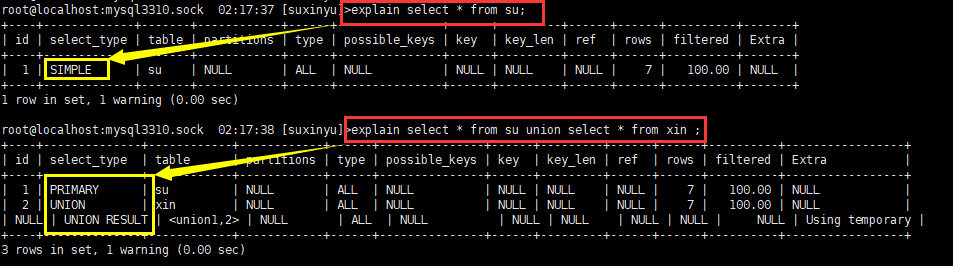
- SIMPLE,简单查询方式,不使用UNION跟子查询;
- PRIMARY,该表格位于最外层开始查询,通常会跟其他查询方式组合;
- UNION,UNION 第一个SELECT 为PRIMARY,第二个及之后的所有SELECT 为 UNION SELECT TYPE;
- UNION RESULT,每个结果集的取出来后,会做合并操作,这个操作就是 UNION RESULT;
- DEPENDENT UNION,子查询中的UNION操作,从UNION 第二个及之后的所有SELECT语句的SELECT TYPE为 DEPENDENT UNION,这个一般跟DEPENDENT SUBQUERY一起结合应用,子查询中UNION 的第一个为DEPENDENT SUBQUERY;
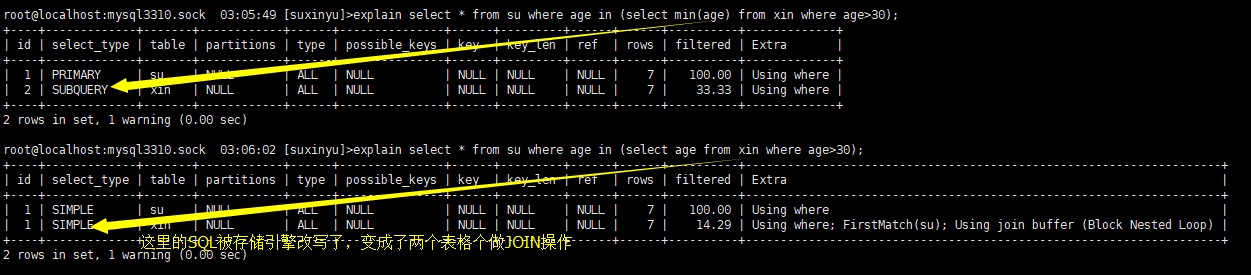
- DEPENDENT SUBQUERY,子查询中内层的第一个SELECT,依赖于外部查询的结果集;
- SUBQUERY,子查询内层查询的第一个SELECT,结果不依赖于外部查询结果集(不会被数据库引擎改写的情况);
- DERIVED,查询使用内联视图;
- MATERIALIZED,子查询物化,表出现在非相关子查询中 并且需要进行物化时会出现MATERIALIZED关键词;
- UNCACHEABLE SUBQUERY,结果集无法缓存的子查询,需要逐次查询;
- UNCACHEABLE UNION,表示子查询不可被物化 需要逐次运行。
.png)


.png)



.png)

2 TYPE
- null,不访问任何一个表格
- system
- 官网解释:The table has only one row (= system table). This is a special case of the const join type.
- join type 为const,并且表格仅含有1行记录。
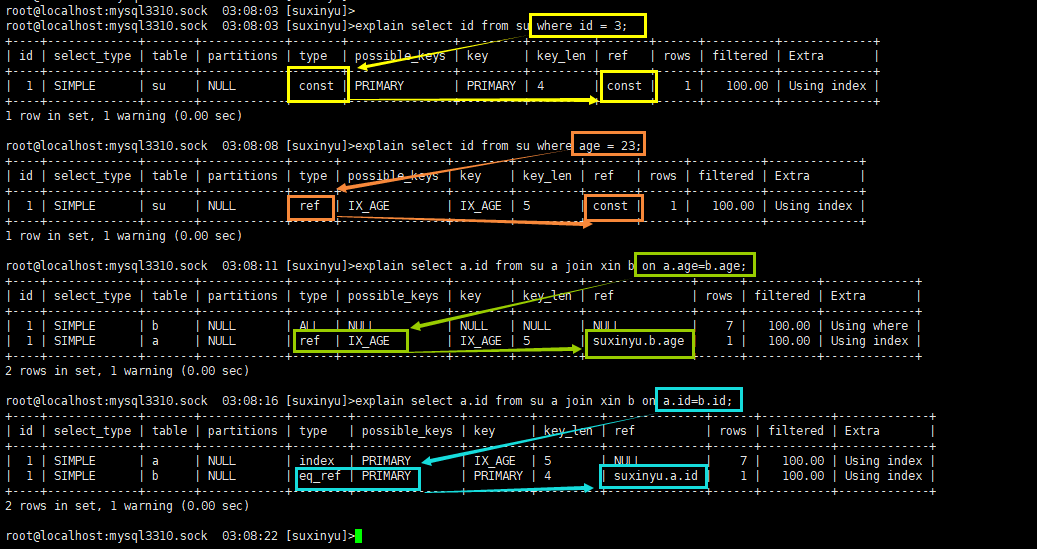
- const
- 主键或者唯一索引的常量查询,表格最多只有1行记录符合查询,通常const使用到主键或者唯一索引进行定值查询。
- 常量查询非常快。

.png)
- eq_ref
- join 查询过程中,关联条件为主键或者唯一索引,出来的行数不止一行
- eq_ref是一种性能非常好的 join 操作。
.png)
- 例子说明:首先从su表格查询所有数据共7行出来,然后每一行跟 xin 的主键id中的1行做匹配。

- ref
- 非聚集索引的常量查询
- 性能也是很不错的。

.png)
- fulltext
- 查询的过程中,使用到了 fulltext 索引(fulltext index在innodb引擎中,只有5.6版本之后的支持)
- 例子是innodb引擎下、带fulltext index的表格查询

.png)
- ref_or_null
- 跟ref查询类似,在ref的查询基础上,不过会加多一个null值的条件查询

.png)
- index merg
- 当条件谓词使用到多个索引的最左边列并且谓词之间的连接为or的情况下,会使用到 索引联合查询

- unique subquery
- eq_ref的一个分支,查询主键的子查询:
- value IN (SELECT primary_key FROM single_table WHERE some_expr)
- 暂时无法模拟出来,目前在5.7.17版本怎么测试,出来的type都是 eq_ref
- index subquery
- ref的一个分支,查询非聚集索引的子查询:
- value IN (SELECT key_column FROM single_table WHERE some_expr)
- 暂时无法模拟出来,目前在5.7.17版本怎么测试,出来的type都是 ref
- ranage
- 当谓词使用到索引范围查询的时候:=、<>、>、>=、<、<=、IS NULL、BETWEEN、IN、<=> (这是个表达式:左边可以推出右边,右边也可推出左边)

.png)
- index
- 使用到索引,但是不是索引查找,而是对索引树做一个扫描,即使是索引扫描,大多数情况下也是比全表扫描性能要好的,因为索引树上的键值只有索引列键值+主键,而全表扫描则是在 聚集索引树(主键+所有列)上进行扫描,索引树相比之下要廋得多跟小得多了。

.png)
- all
- 全表扫描,性能比较差。

.png)
- 关于 index跟all,这里再举一个例子说明下
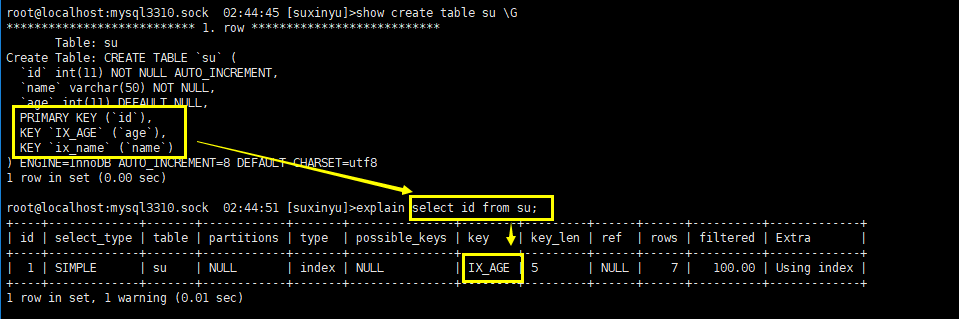
- 下图中,表格su有3个索引:主键、ix_age、ix_name,这三个索引树的内容分别为:主键id+所有列、age+主键id、name+主键id,依次,当扫描主键id查询的时候,这三个索引都能够提供 主键id列,那么哪个性能比较好呢?索引树最小的,扫描次数最少的则为最优,根据索引数内容可得大小:ix_age < ix_name < pk,故执行计划会选择 ix_age。
.png)

.png)
3 ref
.png)
4 extra
- 常用到
- Using index,使用到索引
- Using index conditio,使用到索引过滤
- Using MRR,使用到索引内部排序
- Using where,使用到where条件
- Using temporary,使用到临时表
- Using index
- 索引覆盖,也就是不止要使用到索引,而且没有回表查询
- 举个例子说明
.png)
- 这两个查询中,条件都是一样,但是第一个返回的是所有列,而索引 IX_age上仅包含主键列跟索引键值,故需要再根据主键的值去PK树上找到对应的列,这个操作称为回表,所以第一个查询中extra没有USING INDEX,而第二个查询有。
- Using index conditio,简称 ICP
- Using MRR,简称 MRR
- Using where
- 根据where条件,先取出数据,再跟其他表格关联查询
- Using filesort,无法利用索引来完成的排序
- Using temporary,使用到临时表
- 使用到临时表,表数量较少的情况下,临时表使用缓存,但是比较大的时候,则会磁盘存储,这种情况下,性能将会急剧下降
MySQL_执行计划详细说明的更多相关文章
- 15、简述MySQL的执行计划?
具体的Mysql的执行计划,请参考下面的链接: MySQL_执行计划详细说明
- db2执行计划介绍
在数据库调优过程中,SQL语句往往是导致性能问题的主要原因,而执行计划则是解释SQL语句执行过程的语言,只有充分读懂执行计划才能在数据库性能优化中做到游刃有余. 常见的关系型数据库中,虽然执行计划的表 ...
- (3.14) set statistics io/time/profile /SET SHOWPLAN_ALL ON详解统计信息与执行计划
SQL Server读懂语句运行的统计信息 SET STATISTICS TIME IO PROFILE ON 执行计划详细描述请参考(读懂执行计划) 对于语句的运行,除了执行计划本身,还有一些其他 ...
- 详细查看数据库SQL执行计划
DBCC DROPCLEANBUFFERS 清除数据缓存DBCC FREEPROCCACHE 清除执行计划缓存 SET SHOWPLAN_XML ON 此语句导致 SQL Server 不执行 Tr ...
- Mysql的执行计划各个参数详细说明
执行计划各个参数的说明 1.id 主要是用来标识sql的执行顺序,如果没有子查询,一般来说id只有一个,执行顺序也是从上到下 2.select_type 每个select子句的类型 a: simpl ...
- MySQL优化从执行计划开始(explain超详细)
前言 小伙伴一定遇到过这样反馈:这页面加载数据太慢啦,甚至有的超时了,用户体验极差,需要赶紧优化: 反馈等同于投诉啊,多有几次,估计领导要找你谈话啦. 于是不得不停下手里头的活,赶紧进行排查,最终可能 ...
- MSSQLSERVER执行计划详解
序言 本篇主要目的有二: 1.看懂t-sql的执行计划,明白执行计划中的一些常识. 2.能够分析执行计划,找到优化sql性能的思路或方案. 如果你对sql查询优化的理解或常识不是很深入,那么推荐几骗博 ...
- SQL Tuning 基础概述03 - 使用sql_trace和10046事件跟踪执行计划
1.使用sql_trace跟踪执行计划 1.1 当前session跟踪: alter session set sql_trace = true; //开始sql_trace alter session ...
- Oracle执行计划详解
Oracle执行计划详解 --- 作者:TTT BLOG 本文地址:http://blog.chinaunix.net/u3/107265/showart_2192657.html --- 简介: ...
随机推荐
- Scheme change not implemented
1.错误描述 2.错误原因 由于在改变Java代码中的方法或运行代码出现,导致Tomcat编译的代码不能替换工作空间的代码,即不能及时同步,出现错误 3.解决办法 (1)关闭Tomcat,clean一 ...
- 用DataRelation给多个DataTable建立关系并显示到TreeView
DataRelation 对象执行两种功能: 它可使与正使用的记录相关的记录可用.如果在父记录 (GetChildRows) 中,则它提供子记录:如果正使用子记录 (GetParentRow),则它提 ...
- (十七)java冒泡排序和compareto
java中的排序有:冒泡排序.快速排序.选择排序.插入排序和希尔排序,还有基数排序.鸡尾酒排序.桶排序.鸽巢排序.归并排序等. 冒泡排序法:利用双重for循环,重复走访要排序的数列,两两比较大 ...
- C#抽象类应用实例
abstract修饰符可以和类.方法.属性.索引器及事件一起使用,在类声明中使用abstract修饰符以表明这个类只能是其他类的基类. 抽象类的特性 (1)抽象类不能被实例化 (2)抽象类可以包含抽象 ...
- class-朴素贝叶斯NaiveBayes
1 朴素贝叶斯法的学习与分类1.1 基本原理2 参数估计2.1 极大似然估计2.2 算法2.3 贝叶斯估计 1 朴素贝叶斯法的学习与分类 Naive Bayes是基于贝叶斯定理和特征条件独立的假设的分 ...
- httpclient的理解(代码理解)
一,httpclient的理解 httpcliet就是模仿浏览器在服务器内部从一个项目调用另一个项目的技术.比如说调用接口等. HttpClient 是 Apache Jakarta Common ...
- 关于webpack,打包时遇到的错误
最近在研究webpack这玩意,然后遇到一个问题,执行npm run build的时候,出现下面这个问题,各种搜索后,各种尝试,都没解决 运行时报错ERROR in ./src/app.vue Mod ...
- JavaScript设计模式(4)-桥接模式
桥接模式 在设计一个 Js API 时,可用来弱化它与使用它的类和对象之间的耦合 1. 事件监听器的回调函数 function getBeerById(id, callback) { asyncReq ...
- C#图解教程 第七章 类和继承
类和继承 类继承访问继承的成员所有类都派生自object类屏蔽基类的成员基类访问使用基类的引用 虚方法和覆写方法覆写标记为override的方法覆盖其他成员类型 构造函数的执行 构造函数初始化语句类访 ...
- oracle数据库和表的操作
一.字符函数 (1)连接符 concat --连接符 select concat('10086','-')||'1531234567' 电话号 from dual; (2)首字母大写 initcap ...