Maximum Entropy Model(最大熵模型)初理解
0,熵的描述
熵(entropy)指的是体系的混沌的程度(可也理解为一个随机变量的不确定性),它在控制论、概率论、数论、天体物理、生命科学等领域都有重要应用,在不同的学科中也有引申出的更为具体的定义,是各领域十分重要的参量。熵由鲁道夫·克劳修斯(Rudolf Clausius)提出,并应用在热力学中。后来在,克劳德·艾尔伍德·香农(Claude Elwood Shannon)第一次将熵的概念引入到信息论中来。----baidu
下面我们将从随机变量开始一步一步慢慢理解熵。
1,随机变量(random variable)
1.1 随机变量(random variable)
什么事随机变量?
表示随机现象(在一定条件下,并不总是出现相同结果的现象称为随机现象)各种结果的实值函数(一切可能的样本点)。如掷一颗骰子,它的所有可能结果是出现1点、2点、3点、4点、5点和6点 ,若定义X为掷一颗骰子时出现的点数,则X为一随机变量。
随机变量 X∈{1,2,3,4,5,6}
图(1)

1.2 随机变量概率(The probability of a random variable)
什么是随机变量的概率?
要全面了解一个随机变量,不但要知道它取哪些值,而且要知道它取这些值的规律,即要掌握它的概率分布。概率分布可以由分布函数刻画。若知道一个随机变量的分布函数,则它取任何值和它落入某个数值区间内的概率都可以求出。所以我们可以P(X=x)其中一种情况出现的概率。而P(X)我们叫它为概率分布函数。
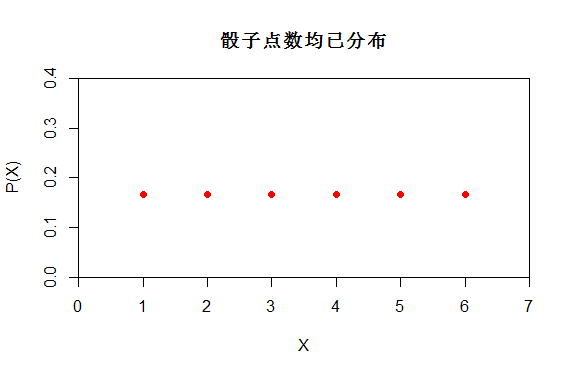
如上述掷一颗骰子,X是均匀分布 X~U[1,6]。而P(X)的分布函数如下,也可以看出P(X=1)=1/6
图(2)
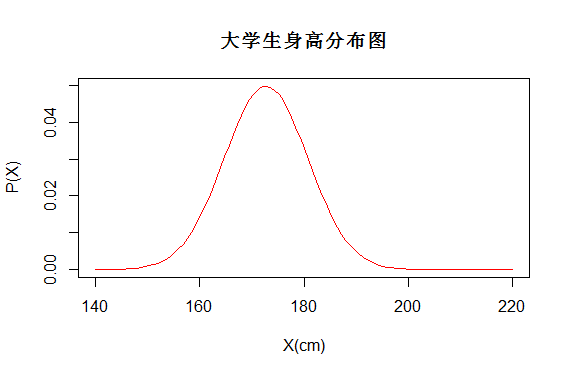
又如某一地区的大学生身高为正态分布,若定义X为男性身高可能出现的值,则X也是一个随机变量,服从X~N(172.70, 8.01)。用P(X)表示随机变量的概率分布。
分布函数
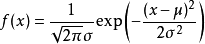
概率分布图如下,而每个学生的身高都对应了一个概率,如P(X=1.7)就能得到相应的概率
图(3)
1.3 随机变量的期望(Expected value)
期望又如何表示,表示什么?
假设随机变量X有值x1概率为p1,X有值x2概率为p2,..X有值xk概率为pk。则离散随机变量的期望可以定义为:
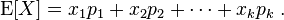
如骰子点数的期望E[X]=1/6(1+2+3+4+5+6)
其实期望就是我们生活中常常遇到的平均值,相当于用一个值简单的描述一个随机变量的分布情况与取值情况。
1.4 随机变量的随机性(randomness of a random variable)
如何刻画一个随机变量的随机性(不确定性)?
a:韦小宝用灌铅作弊骰子投掷的随机变量X更随机 还是我们用正常骰子投掷更随机呢?
明显正常骰子投掷更为随机。正常骰子投掷时有6种可能性{1,2,3,4,5,6},而韦小宝投掷时只有一种可能性6.
b:那么随机性又是受什么影响呢?
X的值?明显不是!X取{1,2,3,4,5,6}与X取{2,3,4,5,6,7}可能性都是6种。
那么什么影响了X的随机性呢?
图(4)
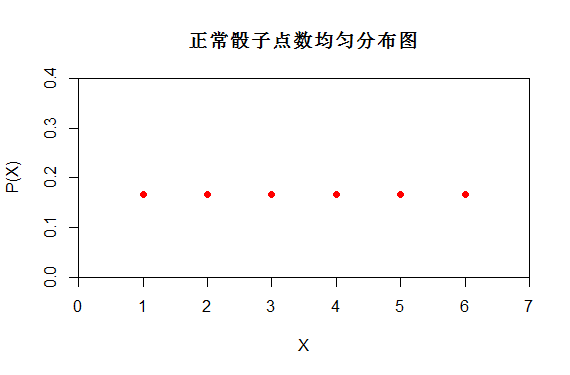
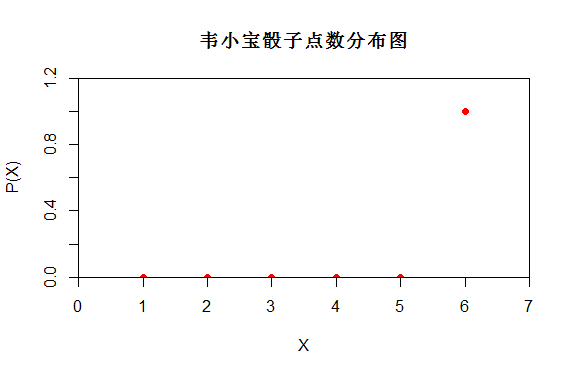
从上面对比图可以看出P(X)不同,它们的随机性不同。正常骰子的分布更为随机。
但是图(5)哪个随机变量分布哪个更随机呢?
第一个图服从均匀分布X~U(1,6)
第二个图服从高斯分布X~N(3.5,1)
两组都是X都是{1,2,3,4,5,6}只是它们取得概率不同。
图(5)
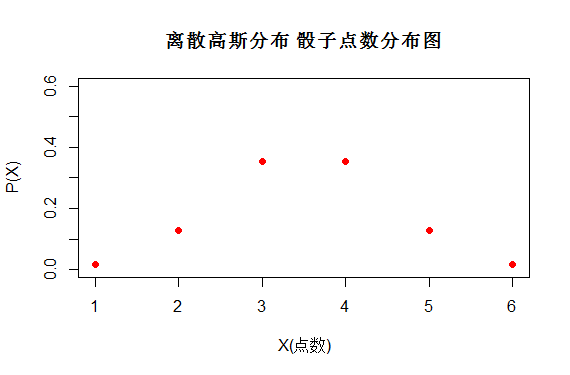
因此我们急需引入一个概念来表述随机变量的随机性,这也就是我们将要说的熵(Entropy)。
2, 最大熵原理(Principle of maximum entropy)
2.1 熵的定义
熵的计算公式:(为什么要将熵计算公式定义成这样? 香农这样定义肯定有他的道理哈。在后面推导以及应用的时候就能感受到香农这么定义的强大。
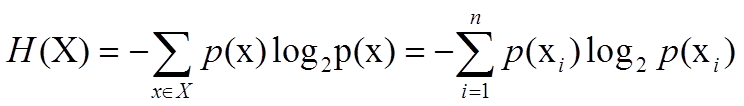
其中,x表示随机变量,与之相对应的是所有可能输出的集合,定义为符号集,随机变量的输出用x表示。P(x)表示输出概率函数。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大.
现在我们可以用熵的公式来比较图4与5中到底哪个更随机了。
P(X)均匀分布,正常骰子投掷时的熵: 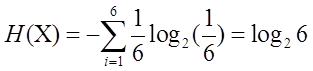 =2.584963
=2.584963
P(X)特殊分布,韦小宝骰子投掷时的熵: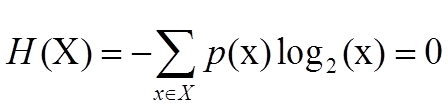 =0
=0
P(X)正态分布,正态骰子投掷的熵:H(X)=2.028845
代入正态分布函数,可以得到 6个点的概率分别为{ 0.0175283 0.1295176 0.3520653 0.3520653 0.1295176 0.0175283}
代入公式H(X)可以推出H(X)=
-(0.0175283*log2(0.0175283)+
0.1295176*log2(0.1295176)+
0.3520653*log2(0.3520653)+
0.3520653*log2(0.3520653)+
0.1295176*log2(0.1295176)+
0.0175283*log2(0.0175283)
)=2.028845
故得出结论:对于投掷骰子这个事件,随机变量X,当X概率分布P(X)是均匀分布时,熵H(X)值最大,是最随机的。
猜测:对于一个随机变量X,当它的分布是均匀分布时,它的熵H(X)是最大的(X是最随机的)。 这也就是我们说的最大熵。
2.2 单约束 最大熵推导
单约束最大熵的基本想法就是在一定条件下(概率和为1),找到一个分布p*(X),使熵H(X)的值达到最大。可以写成:
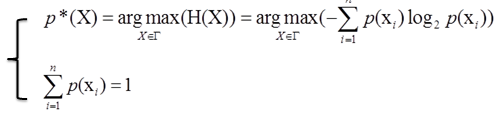
在约束下求最大值,使用拉格朗日乘子法。设

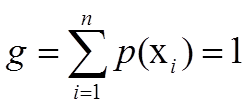
推出拉格朗日方程
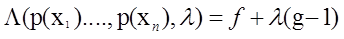
要求最大值,则考虑对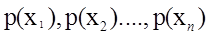 求偏到导得到:
求偏到导得到:
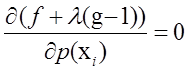 可以改写成:
可以改写成: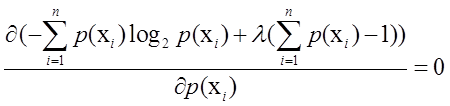
=> 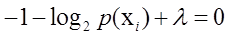
从而得到方程组
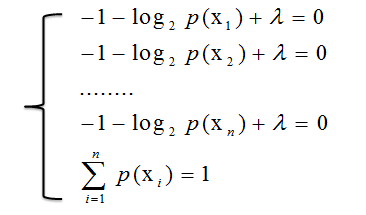 得到
得到 
得到

证明猜想是正确的,一个随机变量X,当p(X)为均匀分布时,熵H(X)最大。
2.3 多约束 最大熵推导
多约束最大熵的基本想法就是在多个条件下(共m+1个约束),找到一个分布p*(X),使熵H(X)的值达到最大。可以写成:
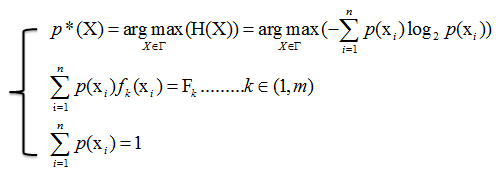
设

=>拉格朗日方程

对所有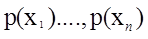 求偏导
求偏导
=> 
=>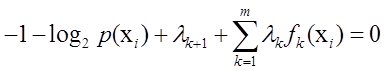
又因为:
=> 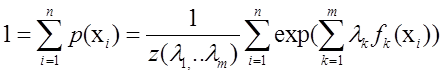
=>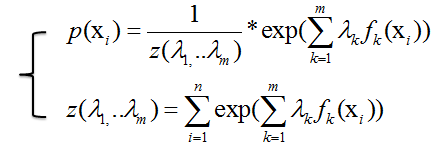
3,最大熵模型(Maximum Entropy Model)
上面讲的都是关于一个随机变量的熵H(X),对于条件概率模型P(Y|X)的条件熵H(Y|X)也常常被用到,定义为

其中集合Z包含变量X,Y的所有范围。(x,y都是向量)
具体推导如下:
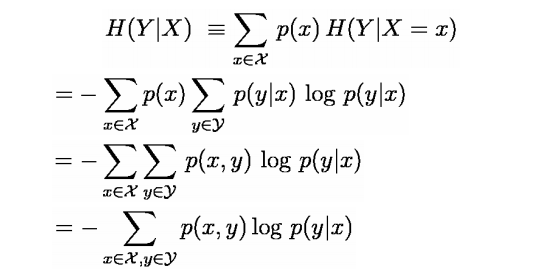
求最大熵就相当于求一个条件分布p(y|x)使得条件熵H(y|x)最大,其中x,y表示向量
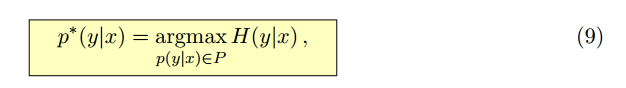
已知存在m+1个约束:
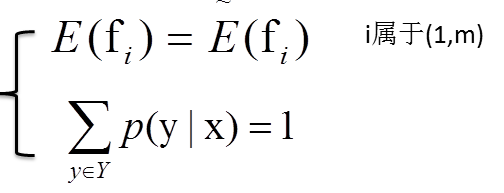
而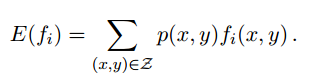
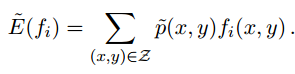
p(x,y)表示边缘概率,f(x,y)表示x与y的函数,~p(x,y)表示经验分布
使用拉格朗日乘子法可以得到拉格朗日方程:
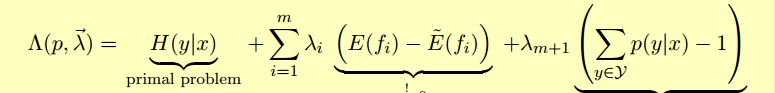
于各个部分对p(x1),p(x2)...求偏导数,
最后解方程可得

具体推导请看 http://pan.baidu.com/s/1i31hnEX
4,图模型表示
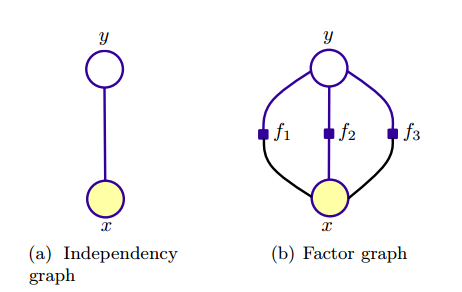
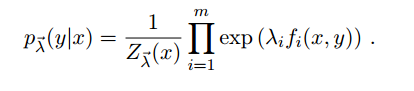
5,引用
http://pan.baidu.com/s/1i31hnEX
http://pan.baidu.com/s/1ntBO2pj
http://pan.baidu.com/s/1nt9M7ln
http://pan.baidu.com/s/1o6v7vfW
http://pan.baidu.com/s/1hqvJ9lE
http://pan.baidu.com/s/1qWHhYSO
Maximum Entropy Model(最大熵模型)初理解的更多相关文章
- 最大熵模型 Maximum Entropy Model
熵的概念在统计学习与机器学习中真是很重要,熵的介绍在这里:信息熵 Information Theory .今天的主题是最大熵模型(Maximum Entropy Model,以下简称MaxEnt),M ...
- softmax为什么使用指数函数?(最大熵模型的理解)
解释1: 他的假设服从指数分布族 解释2: 最大熵模型,即softmax分类是最大熵模型的结果. 关于最大熵模型,网上很多介绍: 在已知部分知识的前提下,关于未知分布最合理的推断就是符合已知知识最不确 ...
- 逻辑斯特回归(logistic regression)与最大熵模型(maximum entropy model)
- class-逻辑回归与最大熵模型
我们知道,线性回归能够进行简单的分类,但是它有一个问题是分类的范围问题,只有加上一个逻辑函数,才能使得其概率值位于0到1之间,因此本次介绍逻辑回归问题.同时,最大熵模型也是对数线性模型,在介绍最大熵模 ...
- 最大熵模型The Maximum Entropy
http://blog.csdn.net/pipisorry/article/details/52789149 最大熵模型相关的基础知识 [概率论:基本概念CDF.PDF] [信息论:熵与互信息] [ ...
- 最大熵模型(Maximum Etropy)—— 熵,条件熵,联合熵,相对熵,互信息及其关系,最大熵模型。。
引入1:随机变量函数的分布 给定X的概率密度函数为fX(x), 若Y = aX, a是某正实数,求Y得概率密度函数fY(y). 解:令X的累积概率为FX(x), Y的累积概率为FY(y). 则 FY( ...
- 统计学习方法6—logistic回归和最大熵模型
目录 logistic回归和最大熵模型 1. logistic回归模型 1.1 logistic分布 1.2 二项logistic回归模型 1.3 模型参数估计 2. 最大熵模型 2.1 最大熵原理 ...
- Maximum Entropy Population-Based Training for Zero-Shot Human-AI Coordination
原文:https://www.cnblogs.com/Twobox/p/16791412.html 熵 熵:表述一个概率分布的不确定性.例如一个不倒翁和一个魔方抛到地上,看他们平稳后状态.很明显,魔方 ...
- EventBus初理解
缘由: 平时工作,因为懒于动笔的原因,也没注重技术和经验的积累,导致之前曾经研究过的问题现在又忘记了,所以要慢慢注重积累,那么就从写作开始,谈谈对工作中碰到的问题进行整理和归纳. 我们 ...
随机推荐
- Linux下查找大文件以及目录
转自:http://www.cnblogs.com/kerrycode/p/4391859.html 在Windows系统中,我们可以使用TreeSize工具查找一些大文件或文件夹,非常的方便高效,在 ...
- 深入理解JAVA虚拟机之JVM性能篇---垃圾回收
一.基本垃圾回收算法 1. 判断对象是否需要回收的方法(如何判断垃圾): 1) 引用计数(Reference Counting) 对象增加一个引用,即增加一个计数,删除一个引用则减少一个计数.垃圾回 ...
- dubbo调用负载均衡
dubbo负载均衡的地址:http://dubbo.io/books/dubbo-user-book/demos/loadbalance.html 随机策略: public class RandomL ...
- SPOJ Highways [矩阵树定理]
裸题 注意: 1.消元时判断系数为0,退出 2.最后乘ans要用double.... #include <iostream> #include <cstdio> #includ ...
- python---协程 学习笔记
协程 协程又称为微线程,协程是一种用户态的轻量级线程 协程拥有自己的寄存器和栈.协程调度切换的时候,将寄存器上下文和栈都保存到其他地方,在切换回来的时候,恢复到先前保存的寄存器上下文和栈,因此:协程能 ...
- 使用sed修改配置项的值
起先我的想法是根据等号来求得配置项所在的行号, sed -n '/aaa/=' config.ini 然后根据行号删除这一行,再增加一行比如行号是9 sed -i '9d' config.ini s ...
- error: Autoconf version 2.67 or higher is required
error: Autoconf version 2.67 or higher is required 今天linux下遇到这种错误,顺便记录下来. #rpm -qf /usr/bin/autoconf ...
- PLEC-交流电机系统+笔记
1.固有机械特性近似图 2.三相交流电机的控制系统 1)理论推导 第一次制动选择能耗制动,第二次制动选择倒拉制动. 2)模型搭建 3)模拟仿真 3.心得体会和笔记总结 制动方式的选择主要是根据各个制动 ...
- iOS 8 UIAlertController 和 UIAlertAction
将alertView 和 actionSheet 封装在UIAlertController 里面化整为零,使开发者更便利 当我们一味的追求高内聚,低耦合的时候,伟大的苹果反其道而行之,这也告诉了我们一 ...
- CSS3总结(干货)
1.css3中好用的选择器 :target //突出显示活动的HTML锚 ::after / ::before{content:" ";} //content必须有,若无内容,用空 ...