Spark SQL1.2与HDP2.2结合
1.hbase相同的rowkey里存在多条记录问题的调研解决方案
VERSIONS => 3,Hbase version 最多插入三条记录
将一个集群hbase中表 "VerticalDataTable" 数据插入另一张表时遇到问题,本来有十几个版本,但是只插入了3个版本(还是可以插入成功)
hbase(main):079:0> create 'scores',{NAME=>'course',VERSIONS=>2}
//版本为2
hbase(main):080:0> put 'scores','Tom','course:math','97'
hbase(main):082:0> put 'scores','Tom','course:math','100'
hbase(main):026:0> scan 'scores'
ROW COLUMN+CELL
Tom column=course:math, timestamp=1394097651029, value=100
1 row(s) in 0.0110 seconds
//HBASE默认scan出来的结果是最后一条时间戳的记录
hbase(main):032:0> scan 'scores',{VERSIONS=>2}
ROW COLUMN+CELL
Tom column=course:math, timestamp=1394097651029, value=100
Tom column=course:math, timestamp=1394097631387, value=97
1 row(s) in 0.0130 seconds
//查出两条记录
hbase(main):029:0> alter 'member',{NAME=>'info','VERSIONS'=>2}
//修改versions
2.hive表内去重数据解决方案
insert overwrite table store
select t.p_key,t.sort_word from
( select p_key,
sort_word ,
row_number()over(distribute by p_key sort by sort_word) as rn
from store) t
where t.rn=1;
Hive上一个典型表内除重的写法, p_key为除重依据, sort_word 为排序依据,一般为时间 rn为排名。
2.关于用SparkSQL历史数据(DBMS)和大数据平台多数据源同时抽取的调研解决方案
Spark Submit 2014上,Databricks宣布放弃Shark 的开发,而转投Spark SQL,理由是Shark继承了Hive太多,优化出现了瓶颈
2015年3月13日 Databricks发布版本1.3.0, 此次版本发布的最大亮点是新引入的DataFrame API 参考这里 这里
目前HDP有支持Spark 1.2.0(Spark SQL在版本1.1.0中产生)
Apache Spark 1.2.0 on YARN with HDP 2.2 例子程序在此
HDP2.2支持Spark1.2.0,等待测试特性,特别是Spark SQL,要提前了解当前版本的bug
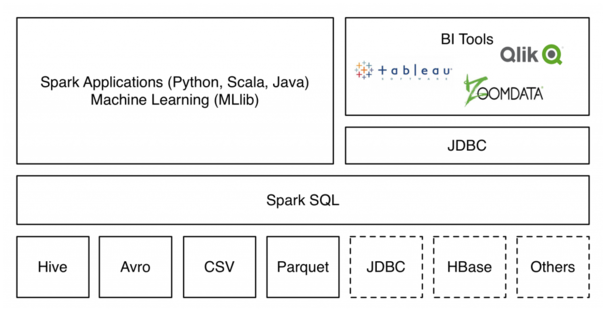
数据源支持:
External data source API在支持了多种如JSON、Avro、CSV等简单格式的同时,还实现了Parquet、ORC等的智能支持;同时,通过这个API,开发者还可以使用JDBC将HBase这样的外部系统对接到Spark中。可以将外部数据来源作为临时表挂在的文件系统之中,减少了全部加载数据过来的种种纠结
保存结果:
统一的load/save API
在Spark 1.2.0中,要想将SchemaRDD中的结果保存下来,便捷的选择并不多。常用的一些包括:
- rdd.saveAsParquetFile(...)
- rdd.saveAsTextFile(...)
- rdd.toJSON.saveAsTextFile(...)
- rdd.saveAsTable(...)
Spark SQL中缓存表一定要用cacheTable(“tableName”)这种形式,否则无法享受到列式存储带来的一系列好处
Using the JDBC data source and the JSON data source to join two tables together to find the traffic log fot the most recently registered users.

先测试HDP最大支持Spark多大版本,再测试其抽取的整合方式,再测试其性能。
3.Spark SQL1.2 与 Spark SQL1.3
External data source API
Spark SQL1.2
在1.2版本之前,开发者已经可以通过扩展RDD的方式支持各种外部数据源
增加了JSON、Avro、CSV等简单格式的外部数据源支持,Spark SQL 1.2中已经搭载了一套新的Parquet数据源实现
External data source API还可以实现Spark与HBase、JDBC等外部系统的高效对接
优化:
Column pruning。在列剪枝中,Column pruning可以完全忽视无需处理的字段,从而显著地减少IO。
Predicate pushdown。将SQL查询中的部分过滤条件下推到更加靠近数据源的位置,利用Parquet、ORC等智能格式写入时记录的统计信息(比如最大值、最小值等)来跳过必 然不存在目标数据的数据段,从而节省磁盘IO。
在Spark 1.2版本中,External data source API只提供了查询支持,尚未提供数据写入支持。在后续版本中还将提供带分片剪枝的分片支持和数据写入支持。今后也期望将Spark SQL的Hive支持迁移到data source API上。
因为对其提供查询支持,可采取方案,数据存放在hive/hbase,目前并没确定是否决定迁移,但是查询时,用到多数据源抽取即可
测试:hive hbase json mysql
Spark SQL1.2与HDP2.2结合的更多相关文章
- Spark SQL1.2测试
Spark SQL 1.2 运行原理 case class方式 json文件方式 背景:了解到HDP也能够支持Spark SQL,但官方文档是版本1.2,希望支持传统数据库.hadoop平台.文本格式 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- SparkSQL基础应用(1.3.1)
一.概述 从1.3版本开始Spark SQL不再是测试版本,之前使用的SchemaRDD重命名为DataFrame,统一了Java和ScalaAPI. SparkSQL是Spark框架中处理结构化数据 ...
- Ambari安装之部署本地库(镜像服务器)(二)
部署本地库(镜像服务器) (1)下载HortWorks官网上的3个库到本地(也可以在线下载,但是速度会很慢) 我们先把hortworks官网上需要下载的3个库下载到本地(这个还是需要很长时间的,当然你 ...
- Ambari集群的搭建(离线安装)
我们先克隆几台机器 我们打开克隆出来的机器 我们先把主机名修改一下 我们把主机名改成am2 下一步我们来配置网卡 把原来的eth0的注释掉,把现在的eth1改成eth0,同时把mac地址记下来 保存退 ...
- ambari单节点集群塔建
配置2台机器,发别为ambari01.ambari03.ambari01上部署Ambari-server和Mirror server,另一台机器上部署agent. 一.配置静态IP 运行命令,让配置生 ...
- Spark(四): Spark-sql 读hbase
SparkSQL是指整合了Hive的spark-sql cli, 本质上就是通过Hive访问HBase表,具体就是通过hive-hbase-handler, 具体配置参见:Hive(五):hive与h ...
- Spark(三): 安装与配置
参见 HDP2.4安装(五):集群及组件安装 ,安装配置的spark版本为1.6, 在已安装HBase.hadoop集群的基础上通过 ambari 自动安装Spark集群,基于hadoop yarn ...
- HDP2.4安装(五):集群及组件安装
HDP(Hortonworks Data Platform)是hortworks推出的100%开源的hadoop发行版本,以YARN 作为其架构中心,包含pig.hive.phoniex.hbase. ...
随机推荐
- Windows下为PHP安装redis扩展
1.使用phpinfo()函数查看PHP的版本信息,这会决定扩展文件版本. 2.下载 php_redis-2.2.7-5.5-ts-vc11-x86.zip 和 php_igbinary-2.0.5- ...
- PHP判断变量是否为空的几种方法小结
1. isset功能:判断变量是否被初始化 说明:它并不会判断变量是否为空,并且可以用来判断数组中元素是否被定义过注意:当使用isset来判断数组元素是否被初始化过时,它的效率比array_key_e ...
- PHP中利用PHPMailer配合QQ邮箱实现发邮件
PHPMailer的介绍: 优点: 可运行在任何平台之上 支持SMTP验证 发送邮时指定多个收件人,抄送地址,暗送地址和回复地址:注:添加抄送.暗送仅win平台下smtp方式支持 支持多种邮件编码包括 ...
- Activity组件安全(下)
什么是Activity劫持 简单的说就是APP正常的Activity界面被恶意攻击者替换上仿冒的恶意Activity界面进行攻击和非法用途.界面劫持攻击通常难被识别出来,其造成的后果不仅会给用户带来严 ...
- zabbix 安装配置介绍
200 ? "200px" : this.width)!important;} --> 介绍 Zabbix是一款能够监控各种网络参数以及服务器健康性和完整性的软件.Zabbi ...
- BZOJ 2142: 礼物 [Lucas定理]
2142: 礼物 Time Limit: 10 Sec Memory Limit: 259 MBSubmit: 1294 Solved: 534[Submit][Status][Discuss] ...
- BZOJ 3998: [TJOI2015]弦论 [后缀自动机 DP]
3998: [TJOI2015]弦论 Time Limit: 10 Sec Memory Limit: 256 MBSubmit: 2152 Solved: 716[Submit][Status] ...
- POJ 3581 Sequence [后缀数组]
Sequence Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 6911 Accepted: 1543 Case Tim ...
- IO&&Serize 利用线程Thread.Sleep实现"自动输出"
查看链接 https://github.com/jungle8884/C-.Net/tree/MyClassLibrary using System; using System.Collections ...
- Angular20 nginx安装,angular项目部署
1 nginx安装(Windows版本) 1.1 下载安装包 到官网下载Windows版本的nginx安装包 技巧01:下载好的压缩包解压即可,无需安装 1.2 启动nginx 进入到解压目录,点击 ...