用go实现常用算法与数据结构——队列(queue)
queue 简介
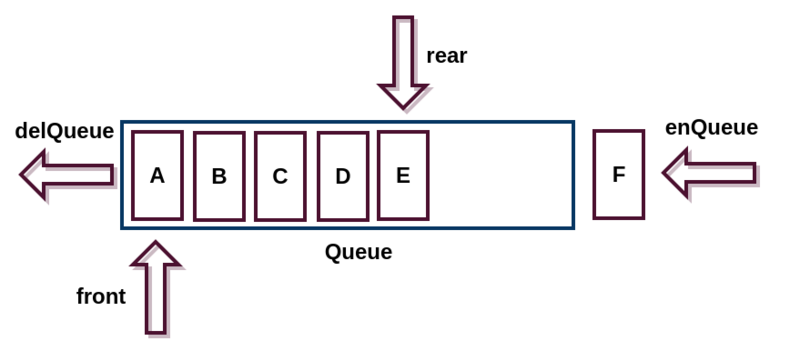
队列是一种非常常见的数据结构,日常生活中也能经常看到。一个典型的队列如下图(图片来自 segmentfault):
可以看出队列和我们日常生活中排队是基本一致的。都遵循 FIFO(First In First Out)的原则。
实现
队列可以使用链表或者数组实现,使用链表的优点是扩容简单,缺点是无法通过索引定位元素,使用数组则相反,扩容不容易但是可以通过索引定位元素。文章采用双向链表实现。代码放在github:
https://github.com/AceDarkknight/AlgorithmAndDataStructure/tree/master/queue
链表一般有下面这几个基本操作,先定义一个接口,方便开发和测试:
type Queue interface {
// 获取当前链表长度。
Length() int
// 获取当前链表容量。
Capacity() int
// 获取当前链表头结点。
Front() *Node
// 获取当前链表尾结点。
Rear() *Node
// 入列。
Enqueue(value interface{}) bool
// 出列。
Dequeue() interface{}
}
笔者的实现中,front 和 rear 节点不保存具体值,只是用来指示真正头尾节点的位置。
链表实现的队列
入列的实现如下:
// normalQueue.go
func (q *NormalQueue) Enqueue(value interface{}) bool {
if q.length == q.capacity || value == nil {
return false
}
node := &Node{
value: value,
}
if q.length == 0 {
q.front.next = node
}
node.previous = q.rear.previous
node.next = q.rear
q.rear.previous.next = node
q.rear.previous = node
q.length++
return true
}
出列的实现:
// normalQueue.go
func (q *NormalQueue) Dequeue() interface{} {
if q.length == 0 {
return nil
}
result := q.front.next
q.front.next = result.next
result.next = nil
result.previous = nil
q.length--
return result.value
}
可以看到,具体实现和链表基本一致,这种方法好处在于不需要考虑数组溢出的问题。但是有时候,我们可能会向 queue 插入相同的元素,我们当前的实现是无法判断数据是否已经存在的,这时我们就需要实现一个无重复元素的 queue。
无重复元素的队列。
我们只需要在原来的基础上加一个 Map 存放我们的具体值就可以了。直接上代码:
// uniqueQueue.go
func (q *UniqueQueue) Enqueue(value interface{}) bool {
if q.length == q.capacity || value == nil {
return false
}
node := &Node{
value: value,
}
// Ignore uncomparable type.
if kind := reflect.TypeOf(value).Kind(); kind == reflect.Map || kind == reflect.Slice || kind == reflect.Func {
return false
}
if v, ok := q.nodeMap[value]; ok || v {
return false
}
if q.length == 0 {
q.front.next = node
}
node.previous = q.rear.previous
node.next = q.rear
q.rear.previous.next = node
q.rear.previous = node
q.nodeMap[value] = true
q.length++
return true
}
因为在 golang 中,map 的 key 必须是可以比较的,所以我们需要排除 Map、slice、function 这些不可比较的类型。剩下的实现和上面的就差不多了。再看出列操作:
// uniqueQueue.go
func (q *UniqueQueue) Dequeue() interface{} {
if q.length == 0 {
return nil
}
result := q.front.next
delete(q.nodeMap, result.value)
q.front.next = result.next
result.next = nil
result.previous = nil
q.length--
return result.value
}
上面两个队列都是基于链表实现的,下面介绍一下基于数组实现的循环队列。
循环队列
循环队列通过复用数组元素来达到“循环”的效果。简单来说就是如果数组前面有位置,就把元素放进去。具体原理可以看这里。入列代码如下:
// cyclicQueue.go
func (q *CyclicQueue) Enqueue(value interface{}) bool {
if q.length == q.capacity || value == nil {
return false
}
node := &Node{
value: value,
}
index := (q.rear + 1) % cap(q.nodes)
q.nodes[index] = node
q.rear = index
q.length++
if q.length == 1 {
q.front = index
}
return true
}
出列操作也类似:
// cyclicQueue.go
func (q *CyclicQueue) Dequeue() interface{} {
if q.length == 0 {
return nil
}
result := q.nodes[q.front].value
q.nodes[q.front] = nil
index := (q.front + 1) % cap(q.nodes)
q.front = index
q.length--
return result
}
Reference
https://www.geeksforgeeks.org/queue-set-1introduction-and-array-implementation/
用go实现常用算法与数据结构——队列(queue)的更多相关文章
- python 下的数据结构与算法---2:大O符号与常用算法和数据结构的复杂度速查表
目录: 一:大O记法 二:各函数高阶比较 三:常用算法和数据结构的复杂度速查表 四:常见的logn是怎么来的 一:大O记法 算法复杂度记法有很多种,其中最常用的就是Big O notation(大O记 ...
- 大数据学习之BigData常用算法和数据结构
大数据学习之BigData常用算法和数据结构 1.Bloom Filter 由一个很长的二进制向量和一系列hash函数组成 优点:可以减少IO操作,省空间 缺点:不支持删除,有 ...
- TypeScript算法与数据结构-队列和循环队列
本文涉及的源码,均在我的github.有两部分队列和循环队列.有问题的可以提个issue,看到后第一时间回复 1. 队列(Queue) 队列也是一种线性的数据结构, 队列是一种先进先出的数据结构.类似 ...
- PHP常用算法和数据结构示例
<?php header("content-type:text/html;charset=utf-8"); $arr=array(3,5,8,4,9,6,1,7,2); ec ...
- php常用算法和数据结构
</pre><pre name="code" class="php"><?php /** * Created by PhpStor ...
- python算法与数据结构-队列(44)
一.队列的介绍 队列的定义:队列是一种特殊的线性表,只允许在表的头部(front处)进行删除操作,在表的尾部(rear处)进行插入操作的线性数据结构,这种结构就叫做队列.进行插入操作的一端称为队尾,进 ...
- Java数据结构与算法(4) - ch04队列(Queue和PriorityQ)
队列: 先进先出(FIFO). 优先级队列: 在优先级队列中,数据项按照关键字的值有序,关键字最小的数据项总在对头,数据项插入的时候会按照顺序插入到合适的位置以确保队列的顺序,从后往前将小于插入项的数 ...
- 用golang实现常用算法与数据结构——跳跃表(Skip list)
背景 最近在学习 redis,看到redis中使用 了skip list.在网上搜索了一下发现用 golang 实现的 skip list 寥寥无几,性能和并发性也不是特别好,于是决定自己造一个并发安 ...
- 数据结构 -- 队列Queue
一.队列简介 定义 队列(queue)在计算机科学中,是一种先进先出的线性表. 它只允许在表的前端进行删除操作,而在表的后端进行插入操作.进行插入操作的端称为队尾,进行删除操作的端称为队头.队列中没有 ...
随机推荐
- python中两种方法实现二分法查找,细致分析二分法查找算法
之前分析了好多排序算法,可难理解了呢!!(泣不成声)这次我要把二分查找总结一下,这个算法不算难度特别大,欢迎大家参考借鉴我不喜欢太官方的定义,太晦涩的语言,让人看了就头晕.我希望加入我自己的理解,能帮 ...
- 前端之BOM和DOM
BOM和DOM简介 BOM(Browser Object Model)是指浏览器对象模型,它使JavaScript有能力与浏览器进行“对话”. DOM(Document Object Model)是指 ...
- power designer 连接mysql提示“connection test failed”
本机环境: win10 64位 jdk8 64位 问题: 测试连接时,总是提示 根据网上搜索: 根源在于:PowerDesigner based on 32 bit JVM kernel 参考: ht ...
- 安卓手机USB共享网络给PC上网
开端 哈哈,最近我又发现了一个校园网的漏洞,但是只能手机连接,于是就想手机连接之后通过usb共享给电脑上网. 在手机上连接校园网WiFi,开启USB网络共享并且连接电脑之后,却发现电脑十分的卡顿!CP ...
- .NET面试资料整理
1.WCF和Web Api的区别答:1WCF是.NET平台开发的一站式框架,Web Api的设计和构建只考虑一件事情,那就是Http,而WCF的设计主要考虑是SOAP和WS-*:Web Api非常轻量 ...
- 百度tn劫持解决办法
最近用右键进行百度搜索的时候总是会跳转到 tn=99135173这类的小尾巴,使得搜索失败,十分恶心,这种广告劫持的手段十分高明隐蔽,很难发觉.开始以为是dns劫持或者是电脑中毒了,更换了几个dns, ...
- React 深入系列3:Props 和 State
文:徐超,<React进阶之路>作者 授权发布,转载请注明作者及出处 React 深入系列3:Props 和 State React 深入系列,深入讲解了React中的重点概念.特性和模式 ...
- springaop问题——Cannot subclass final class org.springframework.boot.autoconfigure.AutoConfigurationPackages$BasePackages
问题描述: 在使用springaop对目标对象增强时,若切点的条件过于宽泛就会出现以下异常! 如: @Before("execution(* *(..))") @Before(&q ...
- vue报错 Do not use built-in or reserved HTML elements as component id:header
组件,不能和html标签重复 header组件,h5新标签重复 Do not use built-in or reserved HTML elements as component id:header ...
- [MongoDB教程] 1.简介
MongoDB (名称来自「humongous (巨大无比的)」), 是一个可扩展的高性能,开源,模式自由,面向文档的NoSQL,基于 分布式 文件存储,由 C++ 语言编写,设计之初旨在为 WEB ...