Google开源的Deep-Learning项目word2vec
用中文把玩Google开源的Deep-Learning项目word2vec
google最近新开放出word2vec项目,该项目使用deep-learning技术将term表示为向量,由此计算term之间的相似度,对term聚类等,该项目也支持phrase的自动识别,以及与term等同的计算。
word2vec项目首页:https://code.google.com/p/word2vec/,文档比较详尽,很容易上手。可能对于不同的系统和gcc版本,需要稍微改一下代码和makefile。具体到我的mac系统,源代码中所有#include <malloc.h>的地方都需要改成#include <stdlib.h>,makefile编译选项中的-Ofast要更改为-O2,-march=native -Wno-unused-result这两个编译选项都不认,使用予以删除。直接make,按照它的文档提示运行即可。
本文主要说说如何使用word2vec处理中文语料。首先我们打开demo-word.sh看看,脚本开始其实就是去下载语料并解压成text8文件,这份文件约96M大小,less看看其实就是纯文本的英文,每个单词之间有空格隔开:
anarchism originated as a term of abuse first used against early working class radicals including the diggers of the english revolution and the sans culottes of the french revolution whilst the term is still used in a pejorative way to describe any act that used violent means to destroy the organization of society it has also been taken up as a positive label by self defined anarchists the word anarchism is derived from the greek without archons ruler chief king anarchism as a political philosophy is the belief that rulers are unnecessary and should be abolished although there...
所以如果我们有一份分过词的中文语料,每个词(term)之间用空格隔开,就可以用word2vec来处理了。
分词我们使用开源的ansj_seg项目,该项目是用java实现中科院ictclas中的算法(下载ictclas没有源码,且linux 64bit的版本在64位mac下链接库报错,应该是不兼容,ictclas官方并未提供mac 64bit的版本)。ansj_seg的官方主页在:https://github.com/ansjsun/ansj_seg,运行:
git clone https://github.com/ansjsun/ansj_seg
下载该项目会报类似下面的错误:
error: RPC failed; result=22, HTTP code = 413 | 116 KiB/s
fatal: The remote end hung up unexpectedly
Writing objects: 100% (2504/2504), 449.61 MiB | 4.19 MiB/s, done.
Total 2504 (delta 1309), reused 2242 (delta 1216)
fatal: The remote end hung up unexpectedly
在stackoverflow上搜了下解决办法,需要执行下面的命令,配置git的缓冲区大小:
git config --global http.postBuffer 524288000
如果仍然失败的话,可以在ansj_seg主页直接下载项目的.zip文件,解压即可。
如果用eclipse打开该项目,还需要依赖一个tree-split-word的项目,这是一个Trie树实现用来查词表的项目,ansj_seg主页目前给出的链接已经失效,在github搜索treesplitword可以找到这个项目,下载后打成jar包,加入到ansj_seg的项目中,发现仍然有错,原因是当前的tree-split-word的很多接口都与ansj_seg中使用的不兼容了。
这时发现ansj_seg是一个maven项目,直接使用mvn compile命令编译,会自动下载其所需依赖,整个编译过程没有报错,最终取得成功。从中提取出项目使用的tree_split-1.0.1.jar,加入到eclipse项目中,重新build一下,eclipse中的红叉消失。
到ansj_seg项目中的src/demo/java/下的org.ansj.demo包中跑一跑每一个demo文件,会遇到以下问题:
1. 报错找不到library.properties文件,将项目根目录下的library.properties.bak copy成library.properties,并注意添加eclipse项目中的classpath,可以解决这个问题;
2. 初始化词典时会报找不到nature/nature.map文件(词性映射文件,ansj_seg不仅有分词的功能,还能词性标注),find . -iname nature.map会发现其实这个文件是存在的,可以直接加eclipse的classpath指向ansj_seg/src/main/resources目录即可;
3. 跑demo时可能会报OutOfMemory的错误,加载词典可能超出了eclipse的默认jvm大小,可以在run as时,设定argument,-Xmx512M -Xms512M即可。
解决上述问题后,除了demo中需要读文件的没有,其他demo都能成功运行。ansj_seg的接口也非常简洁易用,很容易编程读取自己的语料文件进行分词。
最后我们需要解决的就是语料问题。搜狗实验室公布了许多有用的语料,我使用其中的全网新闻数据:http://www.sogou.com/labs/dl/ca.html,填写姓名邮箱申请得到用户名密码,可以获得一个ftp下载地址。首先下载一个迷你语料news_tensite_xml.smarty.tar.gz做做简单实验,解压文件可以看到文本的格式,很容易理解,该文件是gbk编码的,可以转成utf-8编码再进行处理。基于这个迷你语料和ansj_seg编程分词,生成word2vec的输入文件。代码如下:

1 package org.ansj.demo;
2
3 import java.io.BufferedReader;
4 import java.io.FileOutputStream;
5 import java.io.IOException;
6 import java.io.PrintWriter;
7 import java.io.OutputStreamWriter;
8 import java.util.HashSet;
9 import java.util.List;
10 import java.util.Set;
11
12 import love.cq.util.IOUtil;
13
14 import org.ansj.domain.Term;
15 import org.ansj.splitWord.analysis.ToAnalysis;
16
17 public class MyFileDemo {
18
19 public static final String TAG_START_CONTENT = "<content>";
20 public static final String TAG_END_CONTENT = "</content>";
21
22 public static void main(String[] args) {
23 String temp = null ;
24
25 BufferedReader reader = null;
26 PrintWriter pw = null;
27 try {
28 reader = IOUtil.getReader("corpus.txt", "UTF-8") ;
29 ToAnalysis.parse("test 123 孙") ;
30 pw = new PrintWriter(new OutputStreamWriter(new FileOutputStream
31 ("resultbig.txt"), "UTF-8"), true);
32 long start = System.currentTimeMillis() ;
33 int allCount =0 ;
34 int termcnt = 0;
35 Set<String> set = new HashSet<String>();
36 while((temp=reader.readLine())!=null){
37 temp = temp.trim();
38 if (temp.startsWith(TAG_START_CONTENT)) {
39 int end = temp.indexOf(TAG_END_CONTENT);
40 String content = temp.substring(TAG_START_CONTENT.length(), end);
41 //System.out.println(content);
42 if (content.length() > 0) {
43 allCount += content.length() ;
44 List<Term> result = ToAnalysis.parse(content);
45 for (Term term: result) {
46 String item = term.getName().trim();
47 if (item.length() > 0) {
48 termcnt++;
49 pw.print(item.trim() + " ");
50 set.add(item);
51 }
52 }
53 pw.println();
54 }
55 }
56 }
57 long end = System.currentTimeMillis() ;
58 System.out.println("共" + termcnt + "个term," + set.size() + "个不同的词,共 "
59 +allCount+" 个字符,每秒处理了:"+(allCount*1000.0/(end-start)));
60 } catch (IOException e) {
61 e.printStackTrace();
62 } finally {
63 if (null != reader) {
64 try {
65 reader.close();
66 } catch (IOException e) {
67 e.printStackTrace();
68 }
69 }
70 if (null != pw) {
71 pw.close();
72 }
73 }
74 }
75 }
生成的resultbig.txt即为分好词用空格隔开的语料,使用word2vec,运行:
./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -negative 0 -hs 1 -sample 1e-3 -threads 12 -binary 1
./distance vectors.bin
vectors.bin是word2vec处理resultbig.txt生成的term的向量文件,./distance命令加载该文件计算term之间的距离。mini文件能够跑通,但距离没有什么意义,因为语料实在太少了(word2vec中说语料越多效果越好)。
这时可以放心的下载700+M的全网新闻语料了,最好做下预处理只取出有content的行并转码,限于本人的机器,我只取出前20W行进行分词:
cat news_tensite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<content>" | head -n 200000 > corpus.txt
corpus.txt大小是200+M,分词后有4000W+的term,使用word2vec处理,最后得到的结果还有点意思:

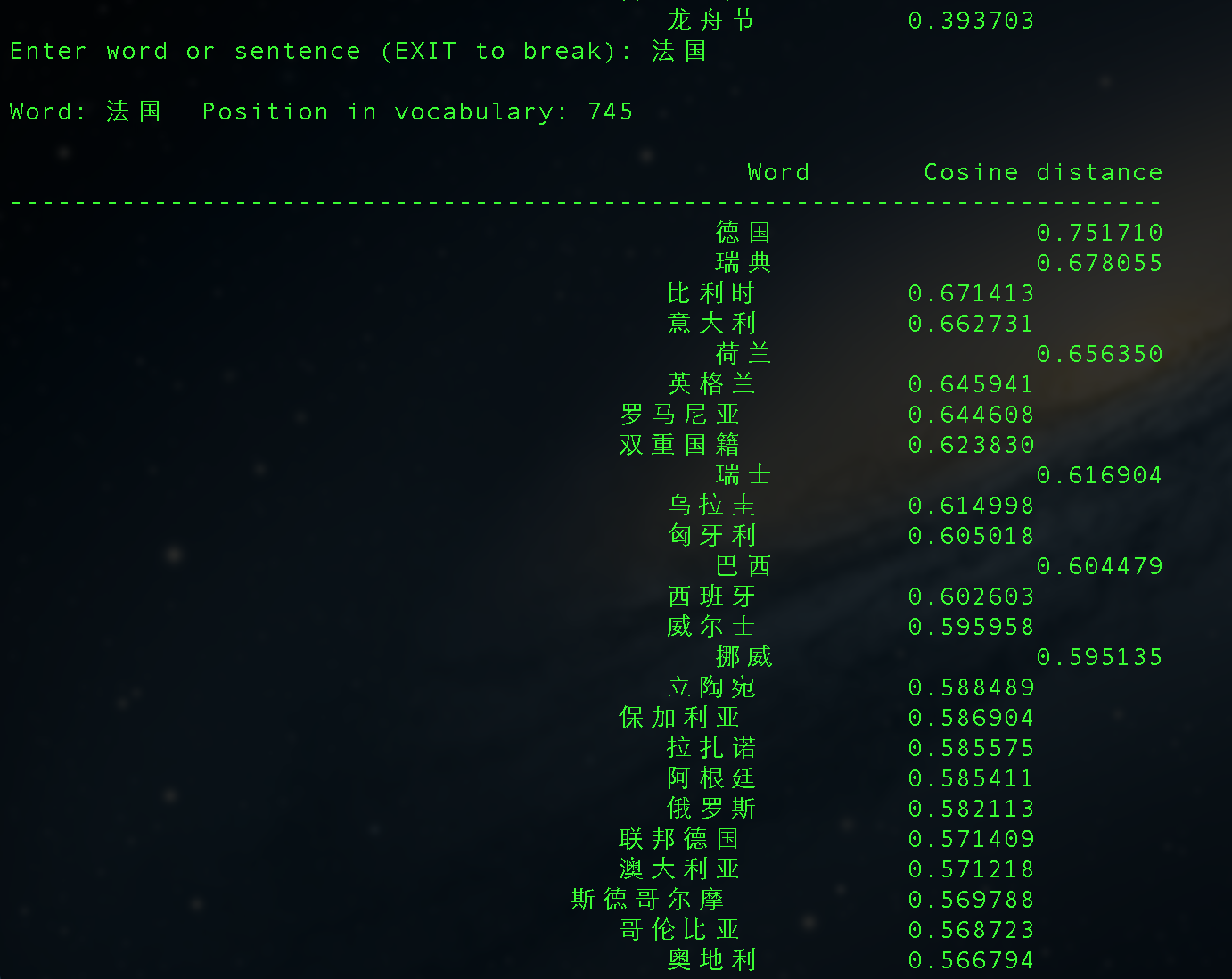
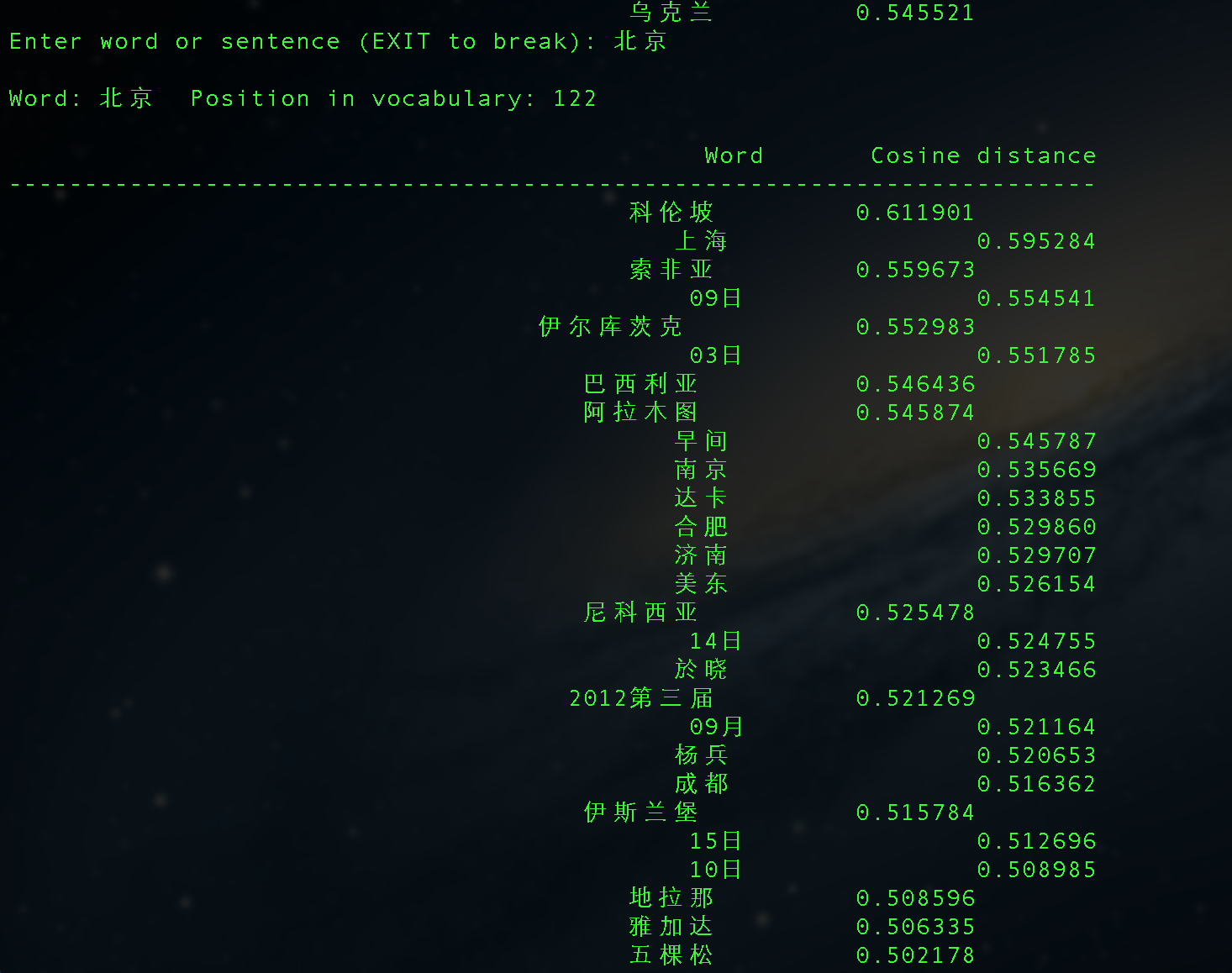
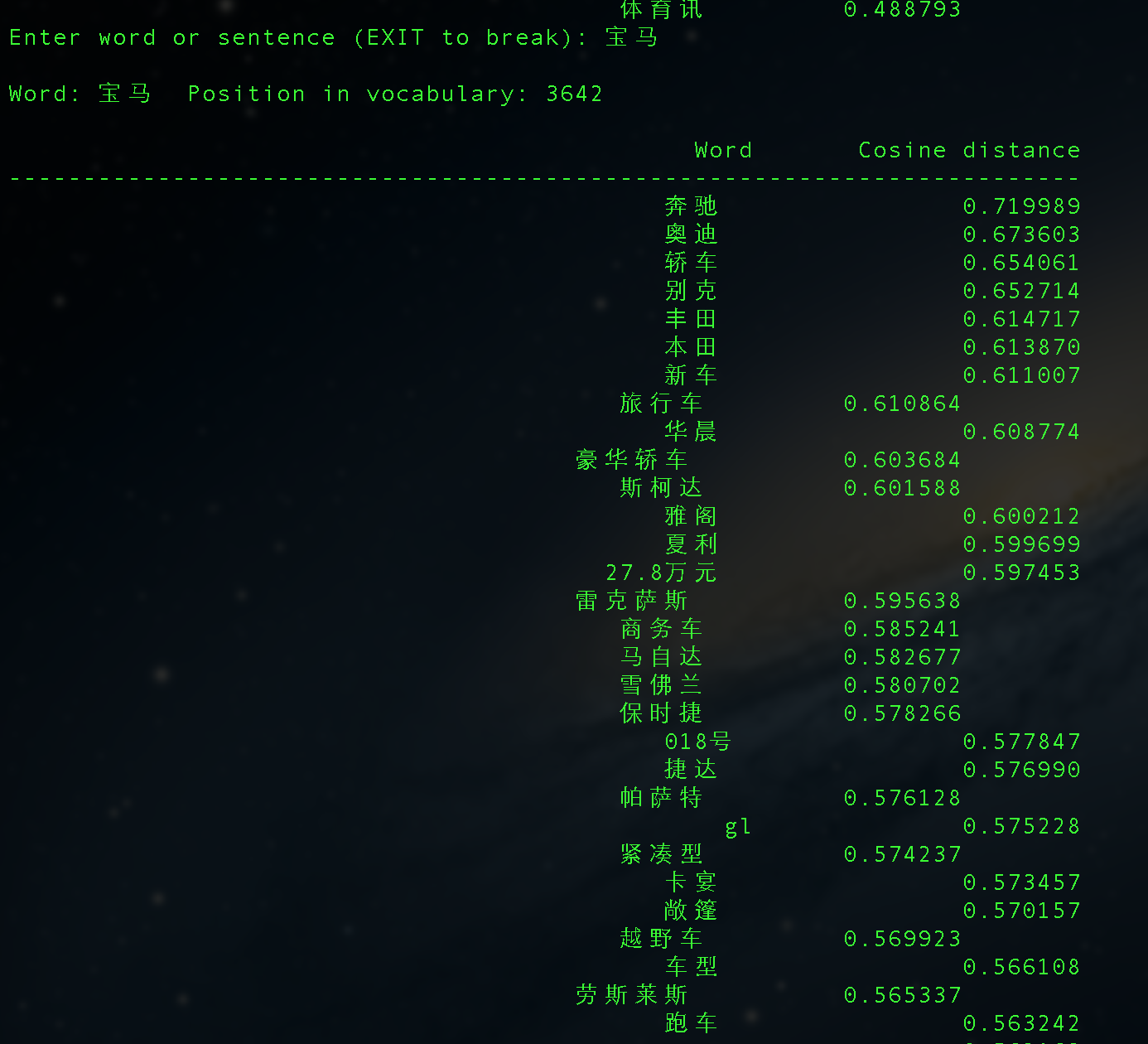
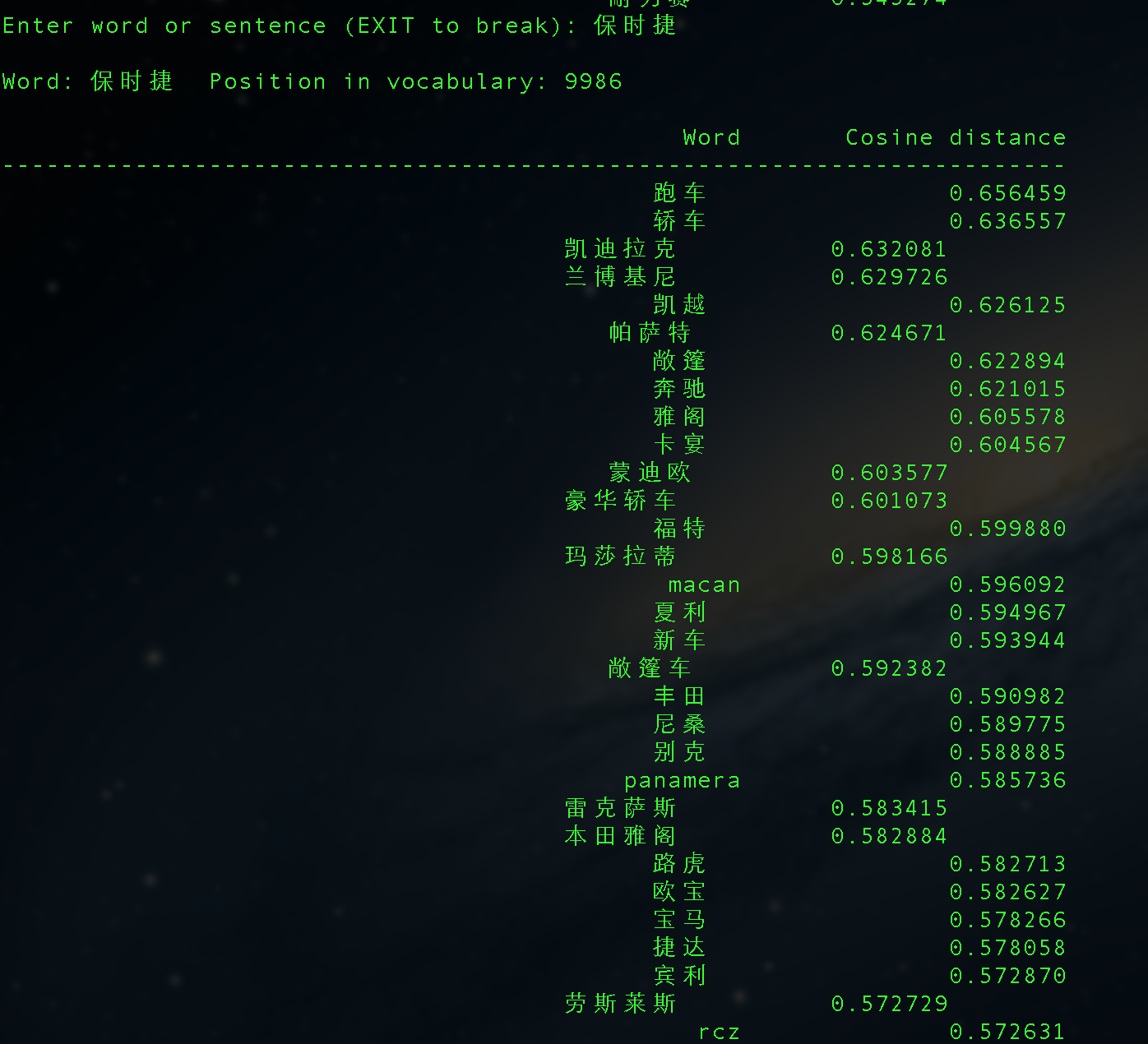
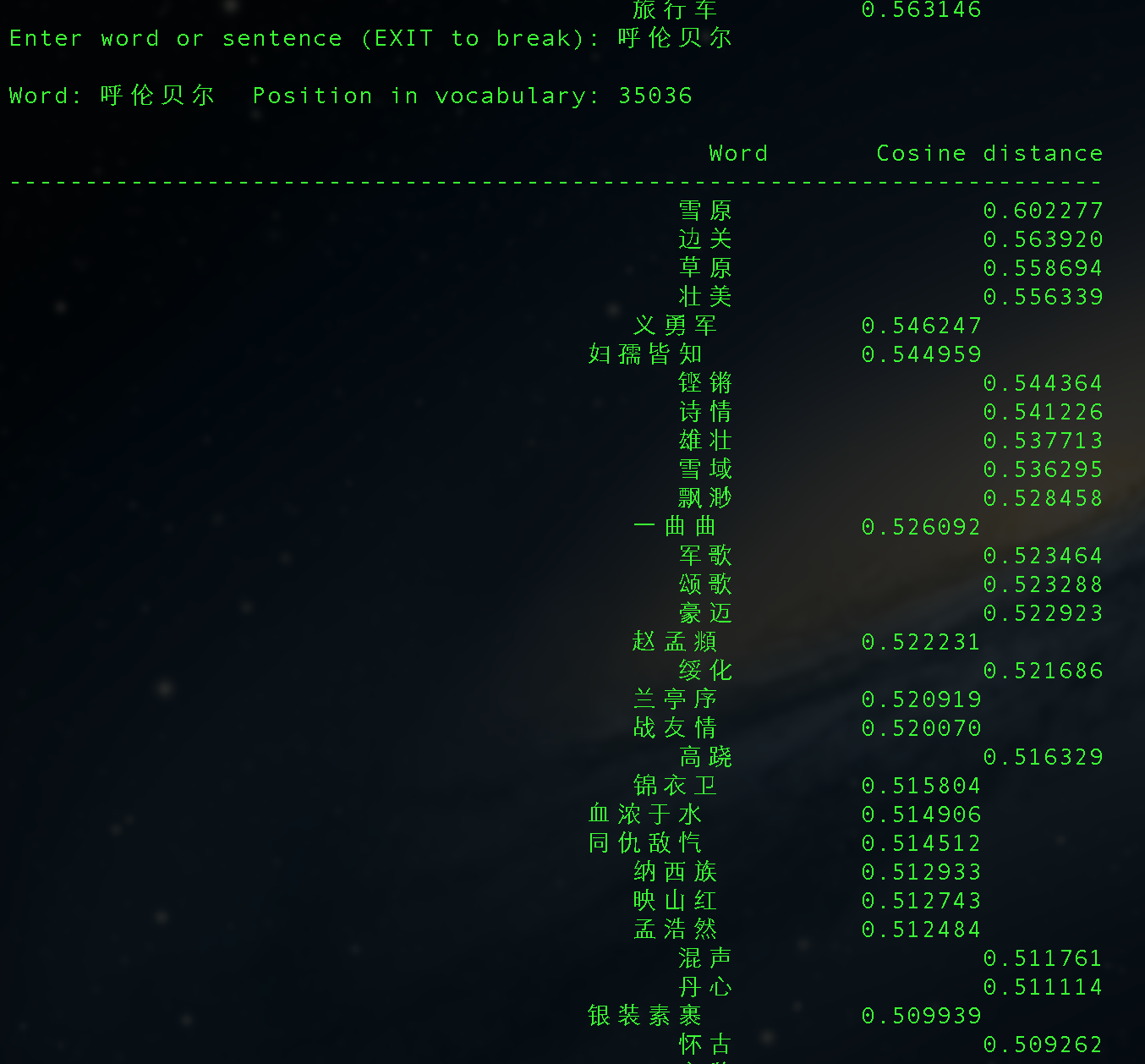
Mac下安装GAE/GoAgent的若干问题
今天尝试在mac下安装翻墙工具,著名的GAE/GoAgent,主要参考这篇文章:http://www.appifan.com/jc/201209/35546.html
但该文有些问题,或者可能是不适合现在版本的goagent,列在下面,供大家参考:
1. goagent的下载:
https://code.google.com/p/goagent/,这个地址经常被墙,不稳定,我搜到了一个百度网盘的备用地址:http://pan.baidu.com/share/link?shareid=230444&uk=1728385475,是2.1.11版本的,也可以使用。官方最新是3.x,据说要配合python 3.0以上版本使用,由于python 3.0和python 2.X版本语法变化较大,可能很多朋友的机器并未升级到python 3.0,所以不建议下载最新的goagent。当然只是据说,有兴趣的可以下来亲自试一下。
2. 启动goagent:
双击已安装的GoAgentMac,然后在控制台上点Show启动,但这时会提示:python-gevent not installed. `curl -k -L http://git.io/I9B7RQ|sh`,这是需要安装gevent,但如果按照提示中的命令,在终端上输入:curl -k -L http://git.io/I9B7RQ|sh命令,下载回来后却会提示:
tar: Unrecognized archive formattar: Error exit delayed from previous errors. |
造成这个错误的原因是是 gevent 转移之后 http://git.io/I9B7RQ 里面的命令没有更新,使用下面几步命令可运行成功:
curl -L -Ohttps://github.com/downloads/surfly/gevent/gevent-1.0rc2.tar.gz tar xvzpf gevent-1.0rc2.tar.gz && cd gevent-1.0rc2 sudo python setup.py install |
最后一步终端会出现较多警告,并编译较长时间,但耐心等待,最终会成功安装gevent。
安装完成后再次双击GoAgentMac点Show查看启动状态,可能仍会提示一个权限方面的错误,这时可以按提示直接用root权限执行goagent中的proxy.py:
cd /Applications/goagent/local/sudo python proxy.py |
这样即可正确启动,此后Ctrl+C退出或者关闭终端,再双击GoAgentMac,就可以正确启动了。
剩下的按照说明中的设置好浏览器中的代理,即可成功翻墙,访问google.com或者twitter.com毫无鸭梨。
200+M的语料,这个结果是不是相当凑合了?小伙伴们,快玩起来吧!剩下phrase,classify的功能各位可以自行探索:)
Google开源的Deep-Learning项目word2vec的更多相关文章
- Deep Learning基础--word2vec 中的数学原理详解
word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,它简单.高效,因此引起了很多人的关注.由于 word2vec 的作者 Tomas Miko ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料汇总 (上)
转载:http://dataunion.org/8463.html?utm_source=tuicool&utm_medium=referral <Brief History of Ma ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
机器学习(Machine Learning)&深度学习(Deep Learning)资料 機器學習.深度學習方面不錯的資料,轉載. 原作:https://github.com/ty4z2008 ...
- 机器学习(Machine Learning)与深度学习(Deep Learning)资料汇总
<Brief History of Machine Learning> 介绍:这是一篇介绍机器学习历史的文章,介绍很全面,从感知机.神经网络.决策树.SVM.Adaboost到随机森林.D ...
- Applied Deep Learning Resources
Applied Deep Learning Resources A collection of research articles, blog posts, slides and code snipp ...
- 通过Visualizing Representations来理解Deep Learning、Neural network、以及输入样本自身的高维空间结构
catalogue . 引言 . Neural Networks Transform Space - 神经网络内部的空间结构 . Understand the data itself by visua ...
- 利用中文数据跑Google开源项目word2vec
一直听说word2vec在处理词与词的相似度的问题上效果十分好,最近自己也上手跑了跑Google开源的代码(https://code.google.com/p/word2vec/). 1.语料 首先准 ...
- Word2Vec之Deep Learning in NLP (一)词向量和语言模型
转自licstar,真心觉得不错,可惜自己有些东西没有看懂 这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领域中应用的理解和总结,在此分享.其中必然有局限性,欢迎各种交 ...
随机推荐
- request的setAttribute()怎么用的?
request.setAttribute()怎么用的?JSP1代码String [] test=new String[2];test[0]="1";test[1]="2& ...
- PHP的垃圾回收机制详解
原文:PHP的垃圾回收机制详解 最近由于使用php编写了一个脚本,模拟实现了一个守护进程,因此需要深入理解php中的垃圾回收机制.本文参考了PHP手册. 在理解PHP垃圾回收机制(GC)之前,先了解一 ...
- jquery 仅仅读
大家都理解这是什么,正常的写法例如以下: if (status == true) { $("#minDelistStr").val(totalAmount);// 去掉首部的&qu ...
- asp.net 给按钮 增加事件
一个页面,有查询,审核,删除,取消审核 按钮,每次结尾 处都要 调用 Initdata方法,重新刷新数据 繁琐哇,我的解决方法是 protected void Page_Load(object sen ...
- PHP实例——输出安全的HTML代码
原文:PHP实例--输出安全的HTML代码 //输出安全的htmlfunction h($text, $tags = null){ $text = trim($text); //完全过滤注释 $tex ...
- java设计模式之三单例模式(Singleton)
单例对象(Singleton)是一种常用的设计模式.在Java应用中,单例对象能保证在一个JVM中,该对象只有一个实例存在.这样的模式有几个好处: 1.某些类创建比较频繁,对于一些大型的对象,这是一笔 ...
- CodeSmith 生成代码
使用CodeSmith 生成代码 CodeSmith是一款优秀的代码生成工具.在ORM中,它能帮助我们生成实体类.XML配置文件,从而简化了我们一部分的开发工作.下面简要说说它的基本用法. 1. 打 ...
- T-SQL: 17 个与日期时间相关的自定义函数(UDF),周日作为周的最后一天,均不受 @@DateFirst、语言版本影响!
原文:T-SQL: 17 个与日期时间相关的自定义函数(UDF),周日作为周的最后一天,均不受 @@DateFirst.语言版本影响! CSDN 的 Blog 太滥了!无时不刻地在坏! 开始抢救性搬家 ...
- robin 今日南
我很高兴,在学校体育馆看到李彦宏博士. 这是第一个真正的一次在媒体上看到,只能看到人才足够多的人,现实,我觉得非常好. 我不是一个真正罗宾的粉丝.百度是不是很热衷于这家公司.,但现在我仍然兴奋,我会被 ...
- php表单(2)
学习php表单 主要是想知道 前端通过submit之后 后端是如何进行操作的.现在实现一个效果:点击submit,输入框的信息不会被刷掉:刷新页面,输入框的信息被刷掉(index.php). < ...