python爬虫框架scrapy初试(二点一)
功能:爬取某网站部分新闻列表和对应的详细内容。
列表页面http://www.zaobao.com/special/report/politic/fincrisis


实现代码:
import scrapy
class ZaobaoSpider(scrapy.Spider):
name = 'zaobao'
start_urls=["http://www.zaobao.com/special/report/politic/fincrisis"] def parse(self,response):
for href in response.xpath('//*[@id="DressUp"]/div[2]/div[1]/div/div/div/a/@href'):
full_url = response.urljoin(href.extract())
yield scrapy.Request(full_url,callback=self.parse_news) #将列表url返回给parse_news函数进行详细爬取
def parse_news(self,response):
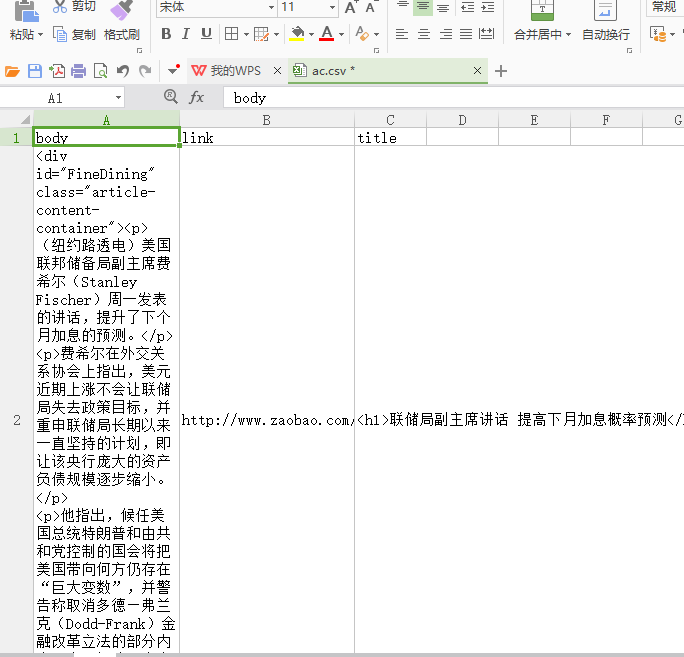
yield {
'title':response.xpath('//*[@id="MainCourse"]/div/h1').extract(),'body':response.xpath('//*[@id="FineDining"]').extract(),
'link':response.url }
运行方法:
scrapy runspider zao.py -o ac.csv #-o 输出为文件,保存格式为csv格式
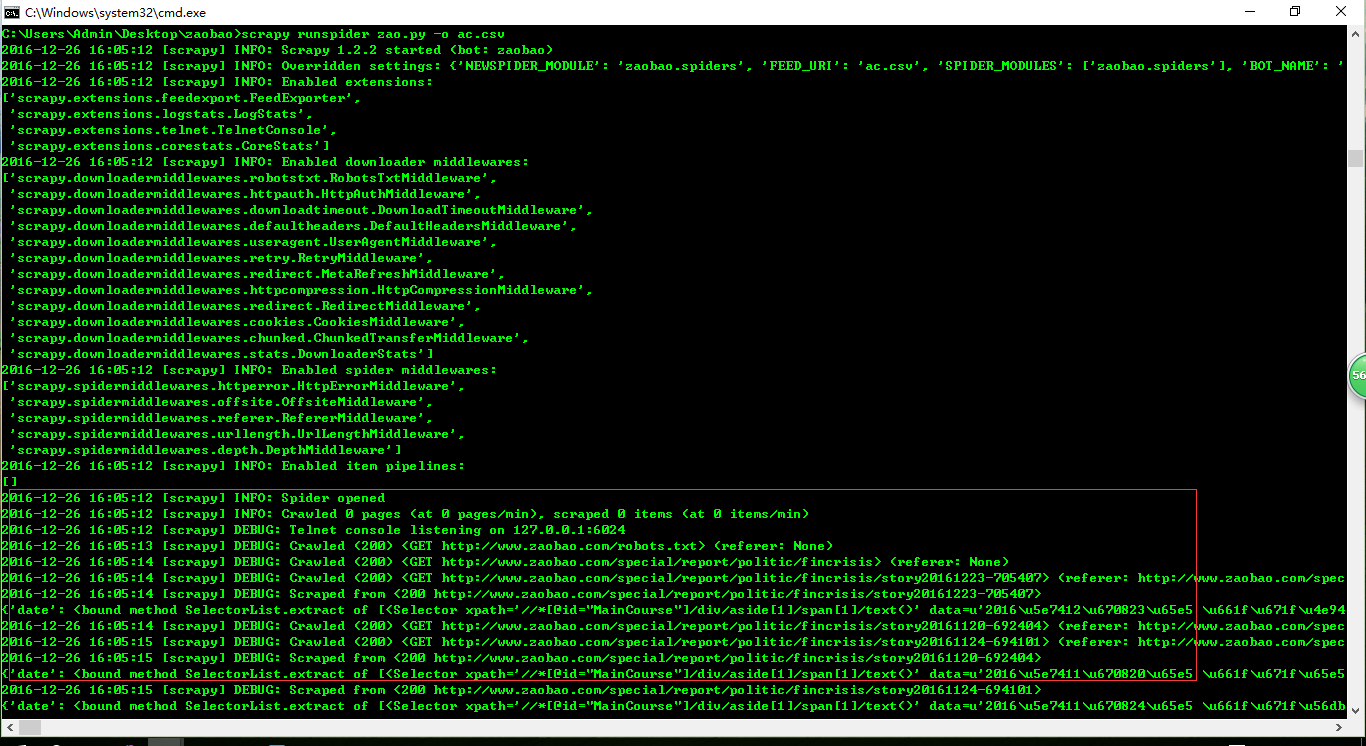
结果:

python爬虫框架scrapy初试(二点一)的更多相关文章
- python爬虫框架scrapy初试(二)
将该导航网站搜索出结果的页面http://www.dmoz.org/Computers/Programming/Languages/Python/Books/里面标题,及标题的超链接和描述爬下来. 使 ...
- 教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http://www.xiaohuar.com/,让你体验爬取校花的成就感. Scr ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Linux 安装python爬虫框架 scrapy
Linux 安装python爬虫框架 scrapy http://scrapy.org/ Scrapy是python最好用的一个爬虫框架.要求: python2.7.x. 1. Ubuntu14.04 ...
- Python爬虫框架Scrapy实例(三)数据存储到MongoDB
Python爬虫框架Scrapy实例(三)数据存储到MongoDB任务目标:爬取豆瓣电影top250,将数据存储到MongoDB中. items.py文件复制代码# -*- coding: utf-8 ...
- 《Python3网络爬虫开发实战》PDF+源代码+《精通Python爬虫框架Scrapy》中英文PDF源代码
下载:https://pan.baidu.com/s/1oejHek3Vmu0ZYvp4w9ZLsw <Python 3网络爬虫开发实战>中文PDF+源代码 下载:https://pan. ...
- Python爬虫框架Scrapy教程(1)—入门
最近实验室的项目中有一个需求是这样的,需要爬取若干个(数目不小)网站发布的文章元数据(标题.时间.正文等).问题是这些网站都很老旧和小众,当然也不可能遵守 Microdata 这类标准.这时候所有网页 ...
- 《精通Python爬虫框架Scrapy》学习资料
<精通Python爬虫框架Scrapy>学习资料 百度网盘:https://pan.baidu.com/s/1ACOYulLLpp9J7Q7src2rVA
- Python爬虫框架Scrapy
Scrapy是一个流行的Python爬虫框架, 用途广泛. 使用pip安装scrapy: pip install scrapy scrapy由一下几个主要组件组成: scheduler: 调度器, 决 ...
随机推荐
- 简单的php和apache的安装
今天刚刚接触到PHP 要想深入学习一门语言 首先我们先从安装开始 对于php和apache这两个程序是比较难以安装的 好了 下面我们开始正式安装: 首先我们得准备好 apache 以及 ...
- dcmtk常用命令
dump2dcm 把普通文件转换成含有dcm头的文件,参数为源文件,目标文件 例:dump2dcm q1.txt query.dcm 表示把q1.txt文件转换为query.dcm dcmdump 阅 ...
- Node填坑教程——过滤器
所谓“过滤器”,只是一个概念,可以理解是一个路由,也可以理解为一个中间件.原理非常简单,就是利用匹配规则,让其有限匹配在正常的路由前面处理就行了. 比如有如下路由 app.get('/', funct ...
- 打开Openstack dashboard出现Internal Server Error
最近研究openstack,想把自己遇到的问题记录下来,同时如果有别的朋友也碰到同样问题的时候可以有个参考. 这次的问题是在openstack搭建好之后,dashboard本身是能用的,但是在某一天后 ...
- Javascript技巧实例精选(5)—显示当前的日期和时间
用Javascript实现在屏幕中打印当前的日期和时间 >>点击这里下载完整html源码<< 这是显示的效果 目前的日期/时间是:Wed Sep 25 2013 23:40:0 ...
- 《剑指Offer》面试题-从头到尾打印链表
题目描述: 输入一个链表,从尾到头打印链表每个节点的值. 输入: 每个输入文件仅包含一组测试样例.每一组测试案例包含多行,每行一个大于0的整数,代表一个链表的节点.第一行是链表第一个节点的值,依次类推 ...
- Vijos: P1046观光旅游
背景 湖南师大附中成为百年名校之后,每年要接待大批的游客前来参观.学校认为大力发展旅游业,可以带来一笔可观的收入. 描述 学校里面有N个景点.两个景点之间可能直接有道路相连,用Dist[I,J]表示它 ...
- discuz X3.1的门户文章实现伪静态,利于搜索引擎收录url的地址修改
最近在捣鼓DZ框架,这两天发现文章的收录情况并不是太理想,做了很多优化方面的工作,今天主要解决了DZ门户的文章链接伪静态化,在这次修改之前,也做过一次在网上找的静态化修改,之前做的方式是: 1.在DZ ...
- Navicat Premium 11.0.10破解补丁
Navicat Premium 11.0.10破解补丁 Navicat Premium 是一个可多重连接的数据库管理工具,让你以单一程序同時连接到 MySQL.SQL Server.SQLite. ...
- WebForms vs. MVC
[译]WebForms vs. MVC(推荐阅读) 正文如下======================================================= 原文示例(VS2012): ...