一个完整的机器学习项目在Python中的演练(二)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习。但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中。就像你的脑海中已经有了一块块”拼图“(机器学习技术),你却不知道如何讲他们拼起来应用在实际的项目中。如果你也遇见过同样的问题,那么这篇文章应该是你想要的。本系列文章将介绍一个针对真实世界实际数据集的完整机器学习解决方案,让您了解所有部分如何结合在一起。
本系列文章按照一般机器学习工作流程逐步进行:
- 数据清洗与格式处理
- 探索性数据分析
- 特征工程和特征选取
- 机器学习模型性能指标评估
- 微调最佳模型(超参数)
- 在测试集上评估最佳模型
- 解释模型结果
- 总结分析
通过完成所有流程,我们将看到每个步骤之间是怎么联系起来的,以及如何在Python中专门实现每个部分。该项目可在GitHub上可以找到,附实现过程。第二篇文章将详细介绍第三个步骤,其余的内容将在后面的文章中介绍。
特征工程和特征选择
特征工程和特征选择虽然是完成机器学习项目中很小的一个环节,但它模型最终的表现至关重要。在特征工程与特征选择阶段做的工作都会准时在模型的表现上得以体现。首先,让我们来了解一下这两项任务是什么:
- 特征工程:特征工程是一项获取原始数据并提取或创建新特征的过程。也就是说可能需要对变量进行转换。例如通过取自然对数、取平方根或者对分类变量进行独热(one-hot)编码的方式以便它们可以在模型中更好的得以利用。通常来说,特征工程就是通过对原始数据的一些操作构建额外有效特征的过程。(可参考:https://machinelearningmastery.com/discover-feature-engineering-how-to-engineer-features-and-how-to-get-good-at-it/)
- 特征选择:特征选择是一项选择数据中与任务最相关的特征的过程。在特征选择的过程中,我们通过删除无效或重复的数据特征以帮助模型更好地学习和总结数据特征并创建更具可解释性的模型。通常来说,特征选择更多的是对特征做减法,只留下那些相对重要的特征。(可参考:https://machinelearningmastery.com/an-introduction-to-feature-selection/)
因为机器学习模型只能从我们提供的数据中学习特征,所以确保数据包含我们任务的所有相关信息至关重要。如果我们没有给模型提供正确的数据,那么机器学习模型将不会达到我们所期望的表现。
在本项目中,我们将按照以下步骤完成特征工程:
- 独热(one-hot)编码分类变量(borough(自治区)和 property use type(财产使用类型))
- 对数值变量做自然对数转换并作为新特征添加到原始数据中
独热(one-hot)编码对于在模型训练中包含分类变量是必要的。例如:机器学习算法无法理解“办公室”这种建筑类型,因此如果建筑物是办公室,则必须对其进行将其记录为1,否则将其记录为0。
添加转换的特征可以使我们的模型学习到数据中的非线性关系。取平方根、取自然对数或各种各样的数值转换是数据科学中特征转换的常见做法,并通过领域知识或在多次实践中发现最有效的方法。这里我们将对所有数值特征取自然对数并添加到原始数据中。
下面的代码实现了数值特征选择并对这些特征进行了取对数操作,选择两个分类变量并对这些特征进行独热(one-hot)编码、然后将两列特征连接在一起。这一系列操作可以通过pandas库很快捷的实现。
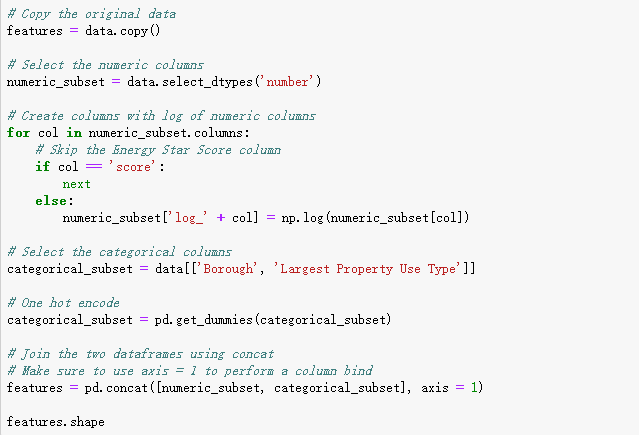
完成上述操作之后,我们有110列(features)、总共超过11,000个对象(buildings)。但是,这些特征并非所有都能够对预测能源之星得分(ENERGY STAR Score)有用,所以接下来我们将通过特征选择去除一些变量。
特征选择
在上面做特征工程的过程之后得到的数据中的110列特征,许多都是多余或重复的,因为它们彼此高度相关。
例如,下图是Site EUI与Weather Norm EUI相关系数为0.997的情况。

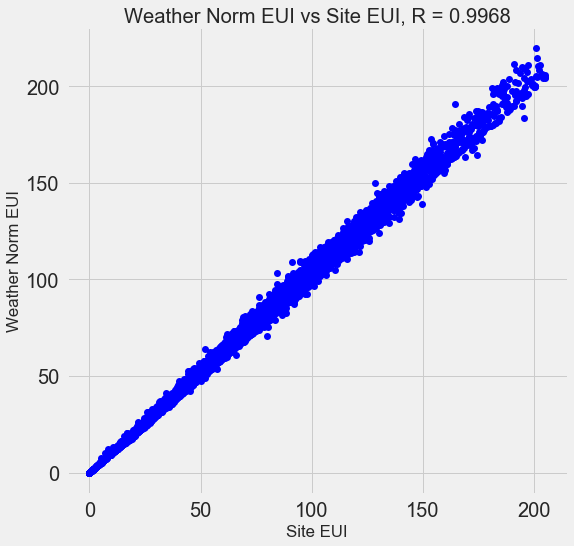
那些相互之间有很强关联性的特征被称为共线(collinear)https://en.wikipedia.org/wiki/Multicollinearity,而且消除这些“特征对”中的一个变量通常可以使机器学习模型更鲁棒并且具有更强的可解释性。(需要注意的一点是,现在是在讨论特征与其他特征的相关性,而不是与目标的相关性。)
有许多方法可以计算特征之间的共线性(collinearity),其中最常见的是方差膨胀因子(VIF)。在本项目中,我们将使用相关系数来识别和删除共线特征。如果它们之间的相关系数大于0.6,我们将放弃一对特征中的一个。

也许你会认为这个值(0.6)是随便定义的,其实并不是,而是通过多次尝试不同的阈值比较后得到的。使用0.6这个值可以产生了最好的模型。机器学习是一个经验性领域,通常是通过试验发现性能最好参数组合。选择特征后,我们剩下64列特征和1列目标特征(能源之星得分)。

建立基线
我们现在已经完成了数据清洗,探索性数据分析和特征工程,开始建立模型之前还需要做最后一步:建立一个初步的基线(baseline)。这实际上是设置一项可以用来核对我们最终模型的实际表现的预估表现。我们可以通过拿最终模型表现与预估模型表现做比较反过来评测此次项目的整体思路。如果机器学习模型的最终表现没有超越我们的预估表现,那么我们可能不得不得出如下结论:
- 使用机器学习的方法无法解决此问题。
- 或者我们可能需要尝试其它不同的方法。
对于回归问题,一个合理的基线是通过预估测试集中所有示例的运行结果为训练集中目标结果的中值。这种方式建立的基线为对比模型表现结果设定了一个相对较低的门槛。
我们将使用的度量标准是平均绝对误差(mae)–计算出预测的平均绝对误差。其实存在很多种回归问题的度量指标,但我喜欢Andrew Ng的建议去选择一个指标然后一直在以后模型评估中使用它。平均绝对误差(mae)是一个不错的选择,它不仅容易计算并且可解释性强。
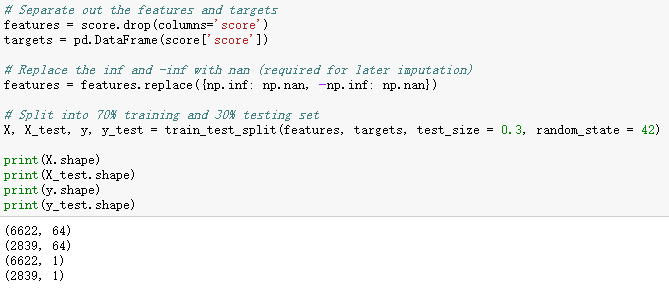
在计算基线之前,我们需要将我们的数据分成一个训练集和一个测试集:
- 训练集的作用就是通过给模型提供有标签的数据来训练模型能力,换句话说就是训练集既能“提供问题”又能“提供答案”。旨在让模型学习特征与目标之间的映射。
- 测试集的作用是用来评估训练好模型。评估过程中不允许模型查看测试集的标签,只能使用特征进行预测。我们可以通过对比测试集的预测值与标签真实值来评估模型的表现。换句话说就是测试集只“提供问题”给模型不“提供答案”。
我们将使用70%的数据进行训练,30%用于测试:

计算基线并得出预估表现值(mae):

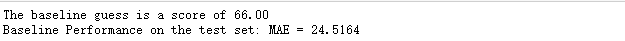
通过计算得出预估模型表现为66,在测试集中的误差约为25左右(分值:1-100)。这是一个很容易达到的性能。
结论
在前两篇的分析中,我们走过了一个完整机器学习项目的前三个步骤。在明确定义问题之后,我们:
- 清洗并格式化了原始数据
- 执行探索性数据分析以了解数据集
- 转换出了一系列我们将用于模型的特征
- 建立了可以判断整个机器学习算法的基线。
接下来将展示如何使用Scikit-Learn评估机器学习模型,选择最佳模型和微调超参数来优化模型。
一个完整的机器学习项目在Python中的演练(二)的更多相关文章
- 一个完整的机器学习项目在Python中的演练(一)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块"拼 ...
- 一个完整的机器学习项目在Python中演练(四)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往d是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块" ...
- 一个完整的机器学习项目在Python中演练(三)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块"拼 ...
- Sklearn 与 TensorFlow 机器学习实战—一个完整的机器学习项目
本章中,你会假装作为被一家地产公司刚刚雇佣的数据科学家,完整地学习一个案例项目.下面是主要步骤: 项目概述. 获取数据. 发现并可视化数据,发现规律. 为机器学习算法准备数据. 选择模型,进行训练. ...
- Hands on Machine Learning with sklearn and TensorFlow —— 一个完整的机器学习项目(加州房地产)
数据集地址:https://github.com/ageron/handson-ml/tree/master/datasets 先行知识准备:NumPy,Pandas,Matplotlib的模块使用 ...
- 3.Scikit-Learn实现完整的机器学习项目
1 完整的机器学习项目 完成项目的步骤: (1) 项目概述 (2) 获取数据 (3) 发现并可视化数据,发现规律. (4) 为机器学习算法准备数据. (5) ...
- 手把手搭建一个完整的javaweb项目
手把手搭建一个完整的javaweb项目 本案例使用Servlet+jsp制作,用MyEclipse和Mysql数据库进行搭建,详细介绍了搭建过程及知识点. 下载地址:http://download.c ...
- react全家桶从0搭建一个完整的react项目(react-router4、redux、redux-saga)
react全家桶从0到1(最新) 本文从零开始,逐步讲解如何用react全家桶搭建一个完整的react项目.文中针对react.webpack.babel.react-route.redux.redu ...
- 机器学习算法与Python实践之(二)支持向量机(SVM)初级
机器学习算法与Python实践之(二)支持向量机(SVM)初级 机器学习算法与Python实践之(二)支持向量机(SVM)初级 zouxy09@qq.com http://blog.csdn.net/ ...
随机推荐
- 量化投资学习笔记29——《Python机器学习应用》课程笔记03
聚类的实际应用,图像分割. 利用图像的特征将图像分割为多个不相重叠的区域. 常用的方法有阈值分割,边缘分割,直方图法,特定理论(基于聚类,小波分析等). 实例:利用k-means聚类算法对图像像素点颜 ...
- Mac开发环境部署
1. 安装 Xcode command line tools xcode-select --install 2. 安装 Homebrew 安装 Homebrew 之前,必须先安装 Xcode Comm ...
- 整合 KAFKA+Flink 实例(第一部分,趟坑记录)
2017年后,一大波网络喧嚣,说流式处理如何牛叉,如何高大上,抱歉,工作满负荷,没空玩那个: 今年疫情隔离在家,无聊,开始学习 KAFKA+Flink ,目前的打算是用爬虫抓取网页数据,传递到Kafk ...
- nginx 命令行参数 启动 重启 重载 停止
今天和大家分享关于 nginx 的一些参数使用 首先,你应该安装了nginx CentOS 安装 nginx 这是很早之前的一篇博客,可以参考. 之前,我们如何去操作 nginx ##简单粗暴法 pk ...
- 位运算基础(Uva 1590,Uva 509题解)
逻辑运算 规则 符号 与 只有1 and 1 = 1,其他均为0 & 或 只有0 or 0 = 0,其他均为1 | 非 也就是取反 ~ 异或 相异为1相同为0 ^ 同或 相同为1相异为0,c中 ...
- 使用HBuilder开发移动APP:开发环境准备(转)
一直想开发个APP玩玩的,但是作为一个PHP码农,需要新学习JAVA或者Object C,这也是一直没能实现这个目标的原因.但是现在HTML5+.APPCAN.apicloud很多工具利用前端技术就能 ...
- echart 之实现温度计
百度这个图表支持不是很好,有的需要自己写,看大神们实现温度计都是用 水球特效实现的我这里雕虫小计啊但是满足我了我的项目需求特此分享出来,可惜自己不是专业的前端 这是我的实现结果 好了上代码html: ...
- Ubuntu16.04下安装python3.6.4详细步骤
记录一下: Ubuntu16.04自带的python版本为python2.7和python3.5,现在想要安装python3.6.4,注意:系统自带的python版本别删除 步骤: # 官网下载安装包 ...
- Yuchuan_Linux_C编程之六 Makefile项目管理
一.整体大纲 二.makefile的编写 一个规则 两个函数 三个变量 1. 一个规则 三要素:目标, 依赖, 命令 目标:依赖 命令: 第一条规则是用来生成终 ...
- 前端解决跨域问题的终极武器——Nginx反向代理
提到代理,分为:正向代理和反向代理. 正向代理:就是你访问不了Google,但是国外有个VPN可以访问Google,你访问VPN后叫它访问Google,然后把数据传给你. 正向代理隐藏了真实的客户端. ...