web scraper插件爬虫进阶(能满足非技术人员的爬虫需求,建议收藏!!!!)
为了照顾更多的小伙伴,大家的学习能力及了解程度都不同,因此大家可以通过以下目录来有选择性的学习,节约大家的时间。
备注: 一定要实操!!!
一定要实操!!!
一定要实操!!!
目录:
#了解和介绍
#下载及安装说明
#工欲善其事必先利其器
#简单尝试(初期用法)案例解析:豆瓣电影TOP250名称爬取
#初级用法(控制链接完成批量爬虫)进阶 案例解析:豆瓣电影TOP250名称爬取
#中级用法(同步完成多项参数爬虫)进阶 案例解析:豆瓣电影TOP250名称爬取
#高级进阶(完成动态类(翻页;滚动加载))爬虫
#了解和介绍
相信能看到这篇文章的小伙伴们应该多多少少对web scraper有些了解,在这里就不再过度阐述。
首先先简单介绍一下web scraper(web scraper 网页刮板)插件
是一款浏览器插件,或者是一款应用程序,用于简单的非代码工程化的爬虫工具,当然正是因为如此所以它的缺点便是对大规模的(数据集大、网页复杂)爬虫工程较为吃力,优点便是简单易操作,能满足小白的日常爬虫需求。
#下载及安装说明
其实一直一来web scraper是Googled的插件,但是因为Google下载商场在国内受到限制,所以为了节约时间我就不介绍Goog浏览器如何下载此插件(感兴趣的可自行查阅相关的资料,有很多)。
而FireFox浏览器插件可以正常在国内访问及安装,并且适配环境和Google浏览器一致,所以建议大家下载Firefox浏览器来使用web scraper插件。
1.下载安装Firefox浏览器(地址:https://www.mozilla.org/zh-CN/firefox/download/thanks/)
2.打开浏览器,点击右上角菜单栏,找到附加组件选项
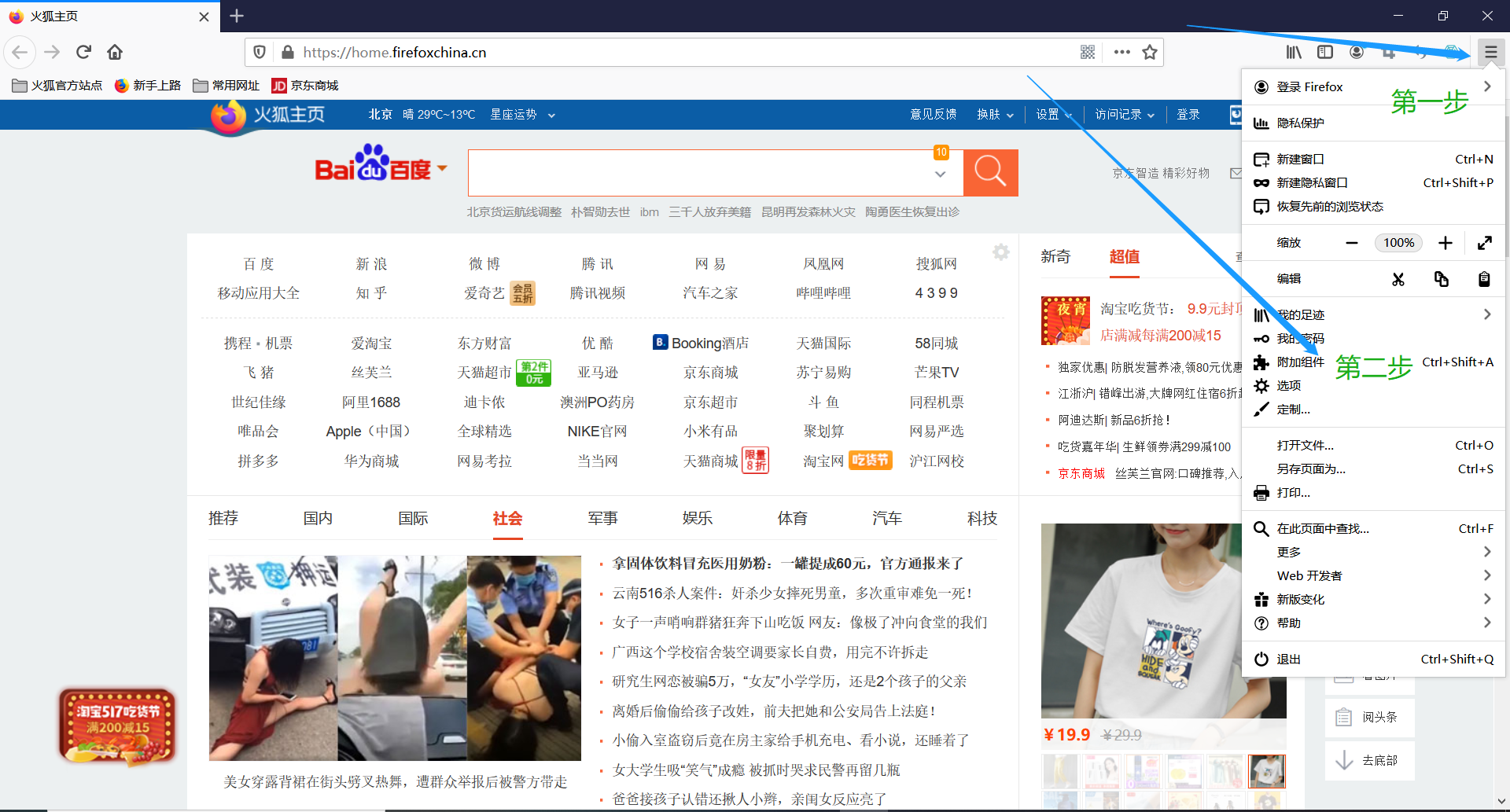
3.进入附加组件管理器,左侧选择栏选择组件,搜索栏内搜索 web scraper,点击添加到Firefox即可,插件安装成功后,Firefox浏览器右上角便会显示web scraper图标,这表示安装成功了。
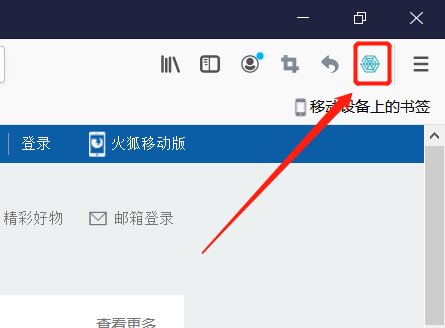
#工欲善其事必先利其器(后面的都要认真学了哦)
首先使用插件需要打开浏览器的开发者后台(想深入了解的小伙伴可以打开https://www.cnblogs.com/mojita/p/5769350.html学习)
如何打开呢,首先定格在浏览器页面,然后按 F12 就可以实现(QQ 浏览器 F12 被禁掉了)。有的电脑需要fn+f12,Mac 电脑也可以用 option + command + I 打开,Win 电脑可以用 Ctrl + Shift + I 打开。
打开后会发现工具栏最右侧出现web scraper图标,点击后便进入web scraper插件,爬虫工作就从这里展开了!
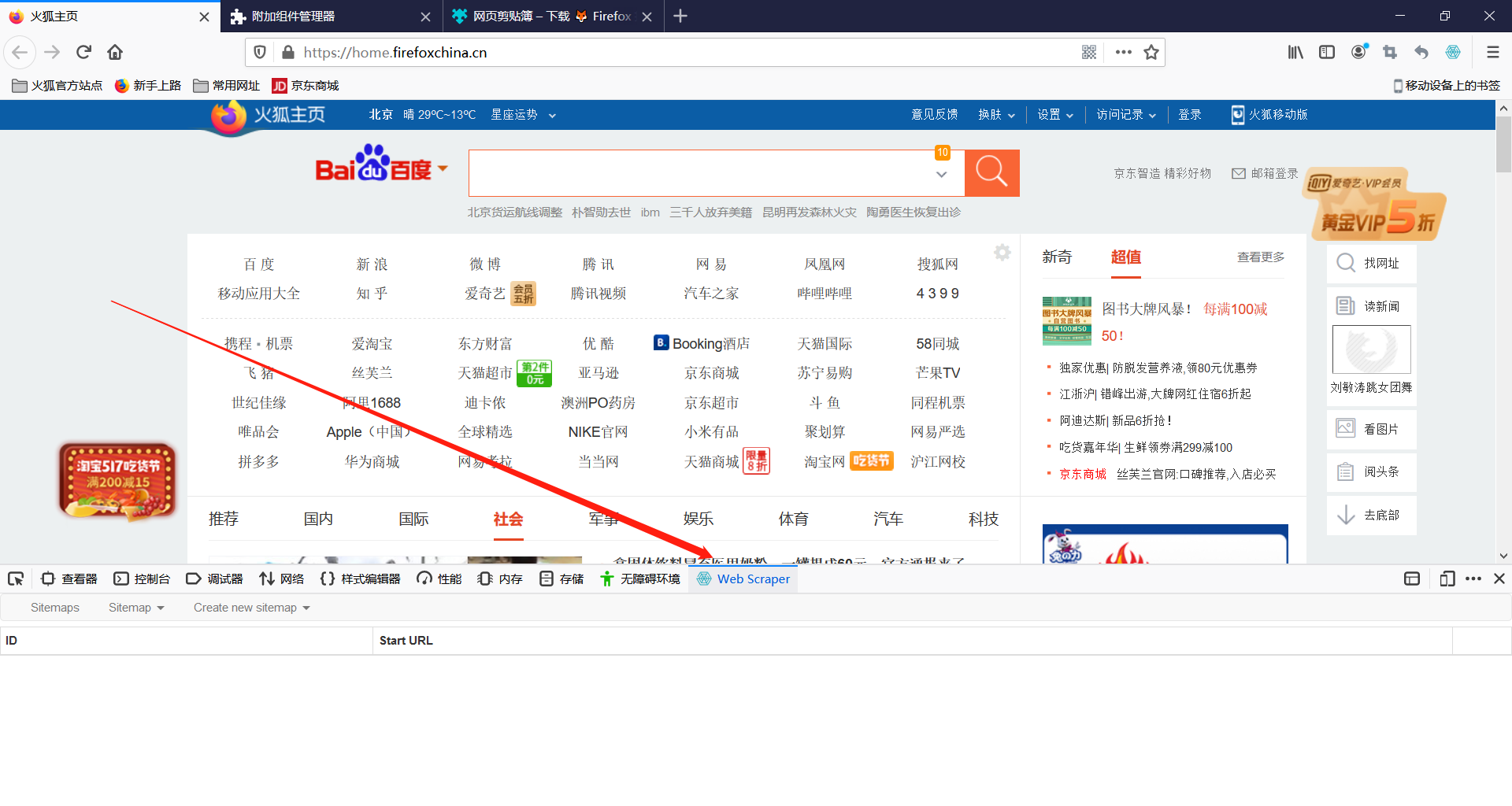
打开后发现有三个工作栏:

先介绍以下URL:统一资源定位符,说白了就是一个网页地址,常用的https://www.baidu.com/ 这便是一个URL
sitemaps:网站地图
create new sitemap:创建新的网站地图
create new sitemap子工作栏:
create sitemap (创建网站地图),打开后会name和URL选项
import sitemap (导入网站地图),打开后会有个Sitemap JSON的选项,顾名思义,这个选项需要我们自主添加json来创建网站地图,(后面会学习到)
好了,先知道这么多即可,下面开始我们的web scraper爬虫进阶,冲啊
web scraper插件爬虫进阶(能满足非技术人员的爬虫需求,建议收藏!!!!)的更多相关文章
- 使用 Chrome 浏览器插件 Web Scraper 10分钟轻松实现网页数据的爬取
web scraper 下载:Web-Scraper_v0.2.0.10 使用 Chrome 浏览器插件 Web Scraper 可以轻松实现网页数据的爬取,不写代码,鼠标操作,点哪爬哪,还不用考虑爬 ...
- Web Scraper——轻量数据爬取利器
日常学习工作中,我们多多少少都会遇到一些数据爬取的需求,比如说写论文时要收集相关课题下的论文列表,运营活动时收集用户评价,竞品分析时收集友商数据. 当我们着手准备收集数据时,面对低效的复制黏贴工作,一 ...
- 简易数据分析 02 | Web Scraper 的下载与安装
这是简易数据分析系列的第 2 篇文章. 上篇说了数据分析在生活中的重要性,从这篇开始,我们就要进入分析的实战内容了.数据分析数据分析,没有数据怎么分析?所以我们首先要学会采集数据. 我调研了很多采集数 ...
- 简易数据分析 04 | Web Scraper 初尝--抓取豆瓣高分电影
这是简易数据分析系列的第 4 篇文章. 今天我们开始数据抓取的第一课,完成我们的第一个爬虫.因为是刚刚开始,操作我会讲的非常详细,可能会有些啰嗦,希望各位不要嫌弃啊:) 有人之前可能学过一些爬虫知识, ...
- Web Scraper 翻页——控制链接批量抓取数据
 这是简易数据分析系列的第 5 ...
- Web Scraper 翻页——控制链接批量抓取数据(Web Scraper 高级用法)| 简易数据分析 05
这是简易数据分析系列的第 5 篇文章. 上篇文章我们爬取了豆瓣电影 TOP250 前 25 个电影的数据,今天我们就要在原来的 Web Scraper 配置上做一些小改动,让爬虫把 250 条电影数据 ...
- Web Scraper 高级用法——使用 CouchDB 存储数据 | 简易数据分析 18
这是简易数据分析系列的第 18 篇文章. 利用 web scraper 抓取数据的时候,大家一定会遇到一个问题:数据是乱序的.在之前的教程里,我建议大家利用 Excel 等工具对数据二次加工排序,但还 ...
- web scraper无法解决爬虫问题?通通可以交给python!
今天一位粉丝的需求所涉及的问题值得和大家分享分享~~~ 背景问题 是这样的,他看了公号里的关于web scraper的系列文章后,希望用它来爬取一个网站搜索关键词后的文章标题和链接,如下图 按照教程, ...
- 简易数据分析 06 | 如何导入别人已经写好的 Web Scraper 爬虫
这是简易数据分析系列的第 6 篇文章. 上两期我们学习了如何通过 Web Scraper 批量抓取豆瓣电影 TOP250 的数据,内容都太干了,今天我们说些轻松的,讲讲 Web Scraper 如何导 ...
随机推荐
- alfred workflow 开发
alfred python demo
- anaconda 使用conda命令创建虚拟环境
1.首先在所在系统中安装Anaconda.可以打开命令行输入conda -V检验是否安装以及当前conda的版本. 2.conda常用的命令. 1)conda list 查看安装了哪些包. 2)con ...
- JDK的下载安装与环境变量的配置
第一步:下载 方式一:在地址栏输入 www.oracle.com 访问该网址自行下载 方式二:百度网盘下载链接1.8 64位版本: https://pan.baidu.com/s/10ZMK7NB6 ...
- 微信小程序入门(持续更新)
微信小程序的主要文件介绍: . js:脚本文件 .json:配置文件 .wxss:样式表文件 .wxml:页面 微信小程序差不多也是和mvc模式差不多的,采用数据和页面分离的模式,在js上写的数据可以 ...
- 梁国辉获Yes评分表系统3.0计算机软件著作权
梁国辉获Yes评分表系统3.0计算机软件著作权 Liang Guohui won the Yes score system 3 computer software copyright 登记证书如下 R ...
- ElementUI表单验证攻略:解决表单项启用和禁用验证的切换,以及动态表单验证的综合性问题
试想一种比较复杂的业务场景: 表格(el-table)的每一行数据的第一列是勾选框,最后一列是输入框.当某一行的勾选框勾上时,启用该行的输入框,并开启该行输入框的表单验证:取消该行的勾选框,则禁用该行 ...
- Xftp的下载安装,以及如何使用XFtp连接虚拟主机/服务器
1.下载ftp软件 下载地址: 点我立即下载 2.下载后双击安装 下一步 选择Free for Home/School 然后其他的默认下一步即可 3.打开之前领取的免费一年虚拟主机的网址,登 ...
- Node.js中的express框架,修改内容后自动更新(免重启),express热更新
个人网站 https://iiter.cn 程序员导航站 开业啦,欢迎各位观众姥爷赏脸参观,如有意见或建议希望能够不吝赐教! 以前node中的express框架,每次修改代码之后,都需要重新npm s ...
- GPTL—练习集—006树的遍历
#include<bits/stdc++.h> using namespace std; typedef int daTp;//datatype typedef struct BTNode ...
- linux系统单网卡绑定多个IP地址
说明: 单网卡绑定两个IP地址,电信和联通,目的:是为了当电信出故障联通正常使用. 系 统 IP地址 子网掩码 网关 CentOS 6.3_64bit eth0:116.18.176.19 255.2 ...