Python字符串编码——Unicode
ASCII码
我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从0000000到11111111。
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格"SPACE"是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0。
非ASCII编码
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用ASCII码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示256x256=65536个符号。
中文编码的问题需要专文讨论,这篇笔记不涉及。这里只指出,虽然都是用多个字节表示一个符号,但是GB类的汉字编码与后文的Unicode和UTF-8是毫无关系的。
Unicode
正如上一节所说,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字"严"。具体的符号对应表,可以查询unicode.org,或者专门的汉字对应表。
Unicode的问题
需要注意的是,Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字"严"的unicode是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题,第一个问题是,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?第二个问题是,我们已经知道,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:1)出现了Unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示Unicode。2)Unicode在很长一段时间内无法推广,直到互联网的出现。
UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种Unicode的实现方式。其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读UTF-8编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字"严"为例,演示如何实现UTF-8编码。
已知"严"的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100 10111000 10100101",转换成十六进制就是E4B8A5。
python 中的字符串编码
在使用
#!/usr/bin/env python
# -*- coding:utf-8 -*-
默认的中文编码为utf8
>>> kel = '中'
>>> kel
'\xe4\xb8\xad'
加入u以后,变成unicode
>>> kel = u'中'
>>> kel
u'\u4e2d'
python 文件字符串编码
保存Unicode字符到文本文档
#coding=utf-8
import os
def write_use_open(filepath):
try:
file = open(filepath, 'wb')
try:
content = '中华人民共和国abcd \r\nee ?!>??@@@!!!!!???¥@#%@%#xx学校ada\r\n'
print file.encoding
print file.newlines
print file.mode
print file.closed
print content
file.write(content)
finally:
file.close()
print file.closed
except IOError, e:
print e
if __name__ == '__main__':
filepath = os.path.join(os.getcwd(), 'file.txt')
write_use_open(filepath)
开始我是IDLE编写的,并直接按F5运行,没发现问题,文件也被正确地保存,文件的编码类型也是utf-8.
可是我用命令行运行,却发现显示出现乱码了,然后在打开文件发现文件被正确保存了,编码还是utf-8:
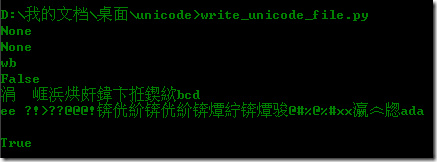
问题是命令行不能自动识别字符编码吧,因为IDLE显示是正确的,它支持utf-8。
于是我修改了代码,在字符串前加了'u',表明content是unicode:
content = u'中华人民共和国abcd \r\nee ?!>??@@@!!!!!???¥@#%@%#xx学校ada\r\n'
可是运行发现,命令行是正确显示了,但是却出现异常:
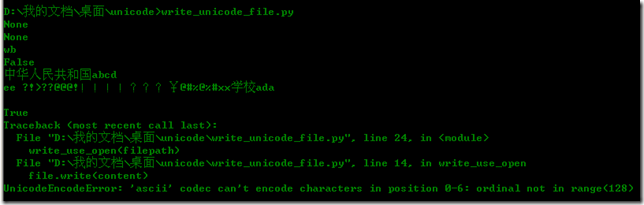
很明显,content里包含了非ASCII码字符,肯定不能使用ASCII来进行编码的,write方法是默认使用ascii来编码保存的。
很容易就可以想到,在保存之前,先对unicode字符进行编码,我选择utf-8
#coding=utf-8
import os
def write_use_open(filepath):
try:
file = open(filepath, 'wb')
try:
content = u'中华人民共和国abcd \r\nee ?!>??@@@!!!!!???¥@#%@%#xx学校ada\r\n'
print file.encoding
print file.newlines
print file.mode
print file.closed
print content
print unicode.encode(content, 'utf-8')
file.write(unicode.encode(content, 'utf-8'))
finally:
file.close()
print file.closed
except IOError, e:
print e
if __name__ == '__main__':
filepath = os.path.join(os.getcwd(), 'file.txt')
write_use_open(filepath)
看看运行结果:
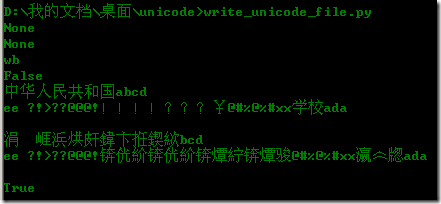
OK了打开文档也是正确的。
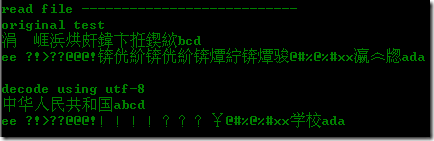
读取文件又怎样?同样道理,只是这次不是编码了,而解码:
def read_use_open(filepath):
try:
file = open(filepath, 'rb')
try:
content = file.read()
content_decode = unicode(content, 'utf-8')
print 'original text'
print content
print 'decode using utf-8'
print content_decode
finally:
file.close()
except IOError, e:
print e
if __name__ == '__main__':
filepath = os.path.join(os.getcwd(), 'file.txt')
write_use_open(filepath)
print 'read file ---------------------------'
read_use_open(filepath)
为什么不直接在open的时候就解码呢?呵呵,可以啊,可以使用codecs的open方法
import codecs
def read_use_codecs_open(filepath):
try:
file = codecs.open(filepath, 'rb', 'utf-8')
try:
print 'using codecs.open'
content = file.read()
print content
finally:
file.close()
except IOError, e:
print e

网络中乱码的解决
中文网页中,有些网页抓取下来以后,由于网页编码的问题,需要进行解码。首先我们需要判断网页中到底使用的是什么编码,在根据这个编码把字符串变成utf8编码。
在探测编码时,chardet第三方库非常的方便。
网页编码判断:
import urllib
rawdata = urllib.urlopen('http://tech.163.com/special/00097UHL/tech_datalist.js').read()
import chardet
print chardet.detect(rawdata)
{'confidence': 0.99, 'language': 'Chinese', 'encoding': 'GB2312'}
通过 chardet 探测出,网页的字符编码为GB2312编码,通过unicode转化为utf8编码:
str_body = unicode(rawdata, "gb2312").encode("utf8")
更多入门教程可以参考:[http://www.bugingcode.com/python_start/] (http://www.bugingcode.com/python_start/)
Python字符串编码——Unicode的更多相关文章
- python字符串编码理解(转载)
(转载)字符编码和python使用encode,decode转换utf-8, gbk, gb2312 (http://www.cnblogs.com/jxzheng/p/5186490.html) A ...
- python 字符串编码
通过字符串的decode和encode方法 1 encode([encoding,[errors]]) #其中encoding可以有多种值,比如gb2312 gbk gb18030 bz2 zlib ...
- 不得不知道的Python字符串编码相关的知识
开发经常会遇到各种字符串编码的问题,例如报错SyntaxError: Non-ASCII character 'ascii' codec can't encode characters in posi ...
- 【转载】不得不知道的Python字符串编码相关的知识
原文地址:http://www.cnblogs.com/Xjng/p/5093905.html 开发经常会遇到各种字符串编码的问题,例如报错SyntaxError: Non-ASCII charact ...
- python字符串编码
python默认编码 python 2.x默认的字符编码是ASCII,默认的文件编码也是ASCII. python 3.x默认的字符编码是unicode,默认的文件编码是utf-8. 中文乱码问题 无 ...
- python 字符串编码 str和unicode 区别以及相互转化 decode('utf-8') encode('utf-8')
- Python字符串编码问题
编码问题:Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了. ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节.字母A用ASC ...
- python 字符串编码 ,区别 utf-8 和utf-8-sig
Python 读取文件首行多了"\ufeff"字符串 python读取B.txt文件时,控制台打印首行正常,但是若是用首行内容打开文本的话,就会报错: Traceback (mos ...
- Python字符串编码转换
使用encode()方法编码 str.encode([encoding="utf-8"][,errors="strict"]) str:表示需要转换的字符串 e ...
随机推荐
- 配对t检验
- Methyl-SeqDNA的甲基化图谱|DNase I-Seq|ChIP-Seq|3C-Seq|
生物医学大数据 Methyl-SeqDNA的甲基化图谱 DNase I-Seq全基因组染色质DNA的开放程度.非基因编码区的调控元件的分布 DNase I高敏感位点:基因处于转录活性状态时,其染色质结 ...
- Linux常见指令x-mind
- vue 项目在scope中使用@import引入css ,作用域是全局
有时候引入第三ui插件,修改样式 时候,需要再单独定义style标签,才有效果,可是会影响全局影响全局,如下所示 加上/deep/,就可以了,
- Angular(二)
Angular开发者指南(二)概念概述 template(模板):带有附加标记的模板HTMLdirectives(指令):使用自定义属性和元素扩展HTMLmodel(模型):用户在视图中显示的数据 ...
- android物理动画、Kotlin客户端、架构组件、菜单效果、应用选择器等源码
Android精选源码 Android一个有趣的Android动画交互设计 android可伸缩日历效果源码 关于界面,全新的卡片风格,支持夜晚模式 Android 用 Kotlin 实现的基于物理的 ...
- Ubuntu16.04中Mysql 5.7 安装配置
记录在Ubuntu 16.04安装Mysql 5.7时遇到的一些问题. Mysql安装 使用如下命令进行安装: 1 sudo apt-get install mysql-server mysql-cl ...
- 27)PHP,视图
其实,视图就是一堆select形成的一个表格,但是这个表格也是存在一个数据库里面的,但是,他不会和一般的表格似得在数据库中显示,就好像虚拟存储器的那种感觉一样. 比如 必看我的一下句子 create ...
- Docker系列八: 数据卷
什么是数据卷 生成环境中使用docker的过程中,往往需要对数据进行持久化,或者需要多个容器之间进行数据共享,这个就涉及到了容器数据管理 容器中管理数据主要有两种方式: 数据卷:容器内数据之间映射到本 ...
- java通过jdbc插入中文到mysql显示乱码(问号或者乱码)
对于很多初学者来说,中文字符编码不相同的问题,是一个很烦躁的问题!! 因为很多时候,我们并不知道,到底是哪一层出现了问题? 在这里稍微做个总结~也怕自己今后忘了!! 其实也就三层: 1.前端页面 2. ...