MapReduce 简单数据统计
1. 准备数据源
摘录了一片散文,保存格式为utf-8
2. 准备环境
2.1 搭建伪分布式环境
上传数据源文件到hdfs中创建的in目录下
2.2 下载相关资源
下载hadoop277
链接:https://pan.baidu.com/s/1xeZx4AVxcjU33hoMLvOojA
提取码:mxic
下载hadoop可执行程序 winutils.exe
链接:https://pan.baidu.com/s/1mPsKk3_TgynAKfJN-kkjSw
提取码:3bfe
2.3 配置环境
2.3.1 配置hadoop的bin和sbin的环境变量
2.3.2 配置Administator访问权限
#两种方式都可
#2.3.2.1 关闭访问权限
<property> #core-site.xml
<name>dfs.permissions</name>
<value>false</value>
</property>
#2.3.2.2 授权
hadoop fs -chmod 777 文件路径
2.4 将资源放到对应位置
1.将hadoopBin.rar中的所有文件拷到hadoop的bin文件夹下
2.将hadoop-2.7.7/share/hadoop里common,hdfs,mapreduce,yarn四个文件夹下的jar包加入到项目中
3. 准备代码
3.1 开发Map类(继承Mapper类)
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
//从文本中读出一行
String line = value.toString();
//将这一行字符串变成字符数组
char[] charArray = line.toCharArray();
//遍历每一个字符
for(char a:charArray) {
//将字符以 字符 1 的格式一行行输出到临时文件中
context.write(new Text(a+""), new IntWritable(1));
//注:MapReduce中有自己的数据类型,需进行转换
}
}
}
3.2 开发Reduce类(继承Reduce类)
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context content) throws IOException, InterruptedException {
//设计一个变量统计总数
int num = 0;
//遍历数据中整数部分
for(IntWritable v:values) {
//get()获得int类型的整数,然后累加
num += v.get();
}
//以 字符 总数 的格式输出到指定文件夹
content.write(key, new IntWritable(num));
}
}
3.3 开发Driver类
public class WordCountDriver{
public static void main(String[] arge) {
System.setProperty("hadoop.home.dir", "F:\\Linux\\hadoop-2.7.7");
//配置访问地址
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.3.8:9000");
try {
//获得job任务对象
Job job = Job.getInstance(conf);
//设置driver类
job.setJarByClass(WordCountDriver.class);
//设置Map类
job.setMapperClass(WordCountMapper.class);
//设置Map类输出的key数据的格式类
job.setMapOutputKeyClass(Text.class);
//设置Map类输出的value数据的格式类
job.setMapOutputValueClass(IntWritable.class);
//设置Reduce类 如果Reduce类输出格式类与Map类的相同,可不写
job.setReducerClass(WordCountReduce.class);
//设置Map类输出的key数据的格式类
job.setOutputKeyClass(Text.class);
//设置Map类输出的value数据的格式类
job.setOutputValueClass(IntWritable.class);
//设置被统计的文件的地址
FileInputFormat.setInputPaths(job, new Path("/in/bob.txt"));
//设置统计得到的数据文件的存放地址
//注:文件所在的文件夹需不存在,由系统创建
FileOutputFormat.setOutputPath(job, new Path("/out/"));
//true表示将运行进度等信息及时输出给用户,false的话只是等待作业结束
job.waitForCompletion(true);
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
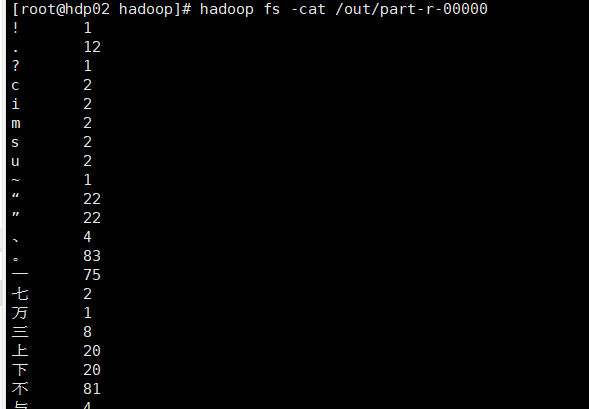
4. 统计结果

5. 相关问题
5.1 问题一
Input path does not exist: file:/in/bob.txt
解决:检查访问地址及相关配置
5.2 问题二
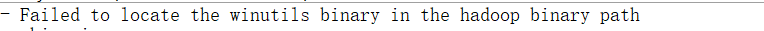
解决:环境变量没配置好或还没生效(选择以下其中一种即可)
- 配置好hadoop环境变量,重启eclipse
- 加入代码System.setProperty("hadoop.home.dir", "F:\Linux\hadoop-2.7.7"),见reduce类代码
5.3 问题三

解决:见上文2.3.2
5.4 问题四
中文乱码
解决:
1.确保eclipse编码格式为utf-8
2.数据源文件保存格式为utf-8
3.使用转换流,字节流转字符流:new OutputStreamWrite(out,"UTF-8")
6. 拓展
6.1 打jar包
- 将FileInputFormat.setInputPaths(job, new Path("/in/bob.txt"))地址改为"/in/",统计in目录下所有文件
- 将此项目打成jar包上传到Linux系统/opt/test目录下
- 运行jar包,代码:hadoop jar jar包名 ,便可得到统计结果
- 以后便可将数据源文件放置于in文件夹中,直接运行jar包进行统计(统计前需删掉hdfs中的out文件夹)
6.2 使用hadoop-eclipse插件开发
6.2.1 下载hadoop-eclipse-plugin
链接:https://pan.baidu.com/s/1mC2KaCMxCmrYL5_RaGTI2w
提取码:zgqg
将该插件放入eclipse的plugin文件夹中

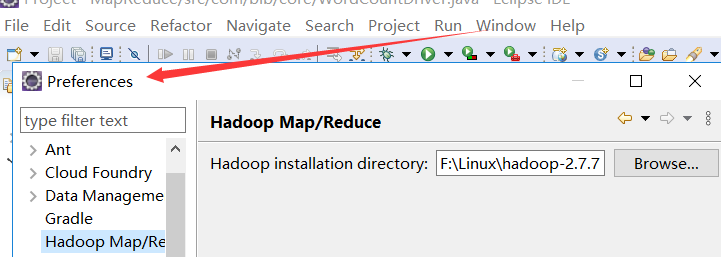
6.2.2 设置hadoop地址
6.2.3 创建项目
6.2.3.1 创建map/reduce项目
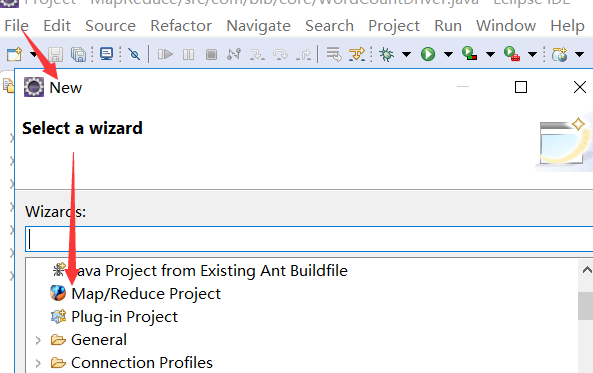
自动添加相关jar包
6.2.3.2 创建对应类
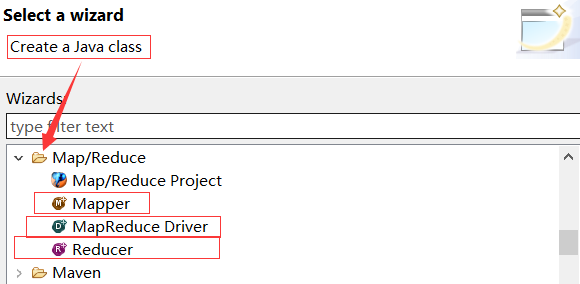
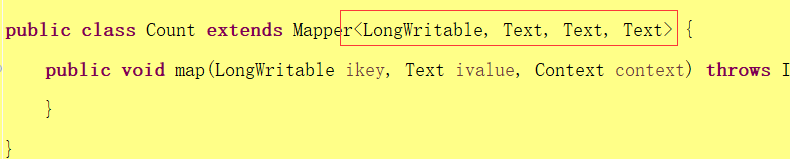
自动写入对应方法(可修改参数格式),如
6.2.4 设置MapReduce
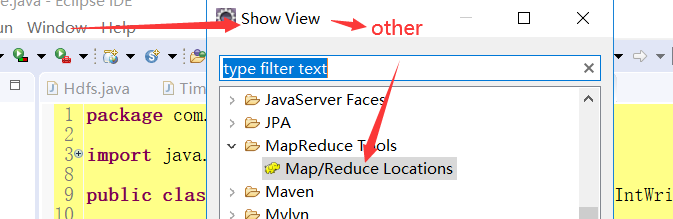

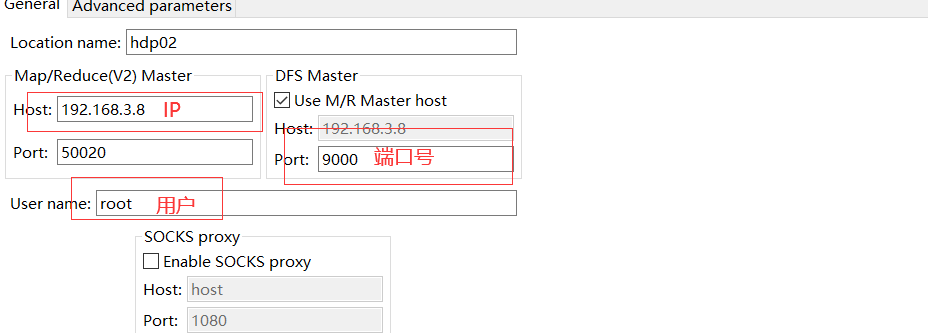

右键点击,选择操作,上传数据源文件或查看文件都便捷许多
MapReduce 简单数据统计的更多相关文章
- MongoDB 的 MapReduce 大数据统计统计挖掘
MongoDB虽然不像我们常用的mysql,sqlserver,oracle等关系型数据库有group by函数那样方便分组,但是MongoDB要实现分组也有3个办法: * Mongodb三种分组方式 ...
- MapReduce处理简单数据
首先要说明的是,关于老师给的实验要求,我在网上看到了原文,原文地址:https://blog.csdn.net/qq_41035588/article/details/90514824,有兴趣的同学可 ...
- 用 python实现简单EXCEL数据统计
任务: 用python时间简单的统计任务-统计男性和女性分别有多少人. 用到的物料:xlrd 它的作用-读取excel表数据 代码: import xlrd workbook = xlrd.open_ ...
- python制作简单excel统计报表3之将mysql数据库中的数据导入excel模板并生成统计图
python制作简单excel统计报表3之将mysql数据库中的数据导入excel模板并生成统计图 # coding=utf-8 from openpyxl import load_workbook ...
- 用python实现简单EXCEL数据统计的实例
用python实现简单EXCEL数据统计的实例 下面小编就为大家带来一篇用python实现简单EXCEL数据统计的实例.小编觉得挺不错的,现在就分享给大家,也给大家做个参考.一起跟随小编过来看看吧 任 ...
- MapReduce实战:统计不同工作年限的薪资水平
1.薪资数据集 我们要写一个薪资统计程序,统计数据来自于互联网招聘hadoop岗位的招聘网站,这些数据是按照记录方式存储的,因此非常适合使用 MapReduce 程序来统计. 2.数据格式 我们使用的 ...
- 有关“数据统计”的一些概念 -- PV UV VV IP跳出率等
有关"数据统计"的一些概念 -- PV UV VV IP跳出率等 版权声明:本文为博主原创文章,未经博主允许不得转载. 此文是本人工作中碰到的,随时记下来的零散概念,特此整理一下. ...
- PHP+Mysql+jQuery实现地图区域数据统计-展示数据
我们要在地图上有限的区块内展示更多的信息,更好的办法是通过地图交互来实现.本文将给大家讲解通过鼠标滑动到地图指定省份区域,在弹出的提示框中显示对应省份的数据信息.适用于数据统计和地图区块展示等场景. ...
- 【转载】国内网站博客数据统计选免费Google Analytics还是百度统计
[转载]国内网站博客数据统计选免费Google Analytics还是百度统计 Google Analytics谷歌统计是我用的第一个网站统计工具,当然现在也一直在用.Google Analytics ...
随机推荐
- 吴裕雄--天生自然python学习笔记:python文档操作批量替换 Word 文件中的文字
我们经常会遇到在不同的 Word 文件中的需要做相同的文字替换,若是一个一个 文件操作,会花费大量时间 . 本节案例可以找出指定目录中的所有 Word 文件(包含 子目录),并对每一个文件进行指定的文 ...
- CMOS
CMOS是Complementary Metal Oxide Semiconductor(互补金属氧化物半导体)的缩写.它是指制造大规模集成电路芯片用的一种技术或用这种技术制造出来的芯片,是电脑主板上 ...
- springboot学习笔记:3.配置文件使用概要
Spring Boot允许外化(externalize)你的配置,这样你能够在不同的环境下使用相同的代码. 你可以使用properties文件,YAML文件,环境变量和命令行参数来外化配置.使用@Va ...
- ArcGIS Server10.2忘记密码怎么办?重置ArcGIS Server Manager密码
忘记了ArcGIS Server Manager的密码不要慌张,下面简单的几步就可以重置密码. 第一步:找到ArcGIS Server的安装目录,然后找到..\ArcGIS\Server\tools\ ...
- 手机安装fiddler证书
如果电脑浏览器和手机抓包有证书问题,那就把电脑的证书都删除,然后在fiddler里重置,手机上删除不了单个证书,可以重新下载一个证书安装 如果电脑抓包正常,手机抓包不正常,那就手机重新下载证书安装 手 ...
- 关于后端下载后端返回的blob类型文件的下载
关于后端返回blob类型的文件下载记录,在请求的时候前端设置响应类型 responseType: 'blob', const blob = new Blob([r], {type: r.type}); ...
- Yii2创建管理员登录
1. 创建管理员表 进入项目根目录,在根目录执行命令: 1 $ ./yii migrate 2. 创建管理的控制器 1 $ cd console/controllers/ 编写代码如下: 123456 ...
- mac命令日常总结
查看某个端口被占用 lsof -i tcp:8080 kill进程: 找到进程的PID,使用kill命令:kill -9 716(PID) date 显示系统日期 mkdir xx 创建xx目录 rm ...
- 使用 ActiveMQ 示例
« Lighttpd(fastcgi) + web.py + MySQLdb 无法正常运行关于 Jms Topic 持久订阅 » 使用 ActiveMQ 示例 企业中各项目中相互协作的时候可能用得到消 ...
- 吴裕雄--python学习笔记:通过sqlite3 进行文字界面学生管理
import sqlite3 conn = sqlite3.connect('E:\\student.db') print("Opened database successfully&quo ...