数栈技术分享:OTS数据迁移——我们不生产数据,我们是大数据的搬运工
数栈是云原生—站式数据中台PaaS,我们在github和gitee上有一个有趣的开源项目:FlinkX,FlinkX是一个基于Flink的批流统一的数据同步工具,既可以采集静态的数据,也可以采集实时变化的数据,是全域、异构、批流一体的数据同步引擎。大家喜欢的话请给我们点个star!star!star!
github开源项目:https://github.com/DTStack/flinkx
gitee开源项目:https://gitee.com/dtstack_dev_0/flinkx
「表格存储」是 NoSQL 的数据存储服务,是基于云计算技术构建的一个分布式结构化和半结构化数据的存储和管理服务。
表格存储的数据模型以「二维表」为中心。
表有行和列的概念,但是与传统数据库不一样,表格存储的表是稀疏的

每一行可以有不同的列,可以动态增加或者减少属性列,建表时不需要为表的属性列定义严格的 schema。
一、概述
OTS的数据迁移可以使用「DataX」完成全量数据迁移。但由于部分数据表的数据量较大,无法在指定的时间窗口内完成全量迁移,且目前DataX只能针对主键值进行范围查询,暂不支持按照属性列范围抽取数据。
所以可以按如下两种方式实现全量+增量的数据迁移:
- 分区键包含范围信息(如时间信息、自增ID),则以指定range为切分点,分批次迁移。
- 分区键不包含范围信息,则可以采用在应用侧双写的模式将数据分批次迁移,写入目标环境同一张业务表。利用OTS的主键唯一性,选择对重复数据执行覆盖原有行的策略来保证数据唯一性。
总而言之,言而总之,我们不生产数据,此刻,我们是大数据的搬运工。
接下来呢,本文就以应用侧调整为双写模式为例,详细说明OTS数据迁移、校验过程。
其中OTS数据迁移流程具体如下图所示:
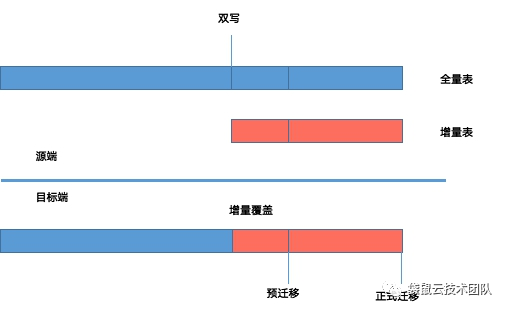
OTS数据迁移之准备工作
- 预迁移阶段:双写模式中的大表全量迁移
- 正式迁移阶段:双写模式中的增量表全量迁移、其余小表的全量迁移

二、预迁移阶段
1、 准备工作
为保证新老环境的数据一致性,需要在开始数据迁移前,对目标环境的OTS数据表进行数据清空操作,Delete操作是通过DataX工具直接删除表内数据,无需重新建表。
具体操作如下:
1) 配置DataX任务
在使用DataX执行数据清空前,需配置对应数据表使用DataX执行Delete任务所需的json文件。在清空数据的配置中,reader与writer均配置目标端的连接信息,且数据写入模式配置DeleteRow即可,具体内容如下:
{
"job": {
"setting": {
"speed": {
"channel": "5"
}
},
"content": [{
"reader": {
"name": "otsreader",
"parameter": {
"endpoint": "http://xxx.vpc.ots.yyy.com/",
"accessId": "dest_accessId",
"accessKey": "dest_accessKey",
"instanceName": " dest_instanceName",
"table": " tablename ",
"column": [{
"name": "xxxxx"
},
{
"name": "xxxxx"
}
],
"range": {
"begin": [{
"type": "INF_MIN"
}],
"end": [{
"type": "INF_MAX"
}]
}
}
},
"writer": {
"name": "otswriter",
"parameter": {
"endpoint": "http://xxx.vpc.ots.yun.yyy.com/",
"accessId": "dest_accessId",
"accessKey": "dest_accessKey",
"instanceName": " dest_instanceName",
"table": " tablename ",
"primaryKey": [{
"name": "xxxxx",
"type": "string"
}],
"column": [{
"name": "xxxxx",
"type": "string"
},
{
"name": "xxxxx",
"type": "string"
}
],
"writeMode": "DeleteRow"
}
}
}]
}
}2 )执行datax任务
- 登录datax所在ECS后,进入datax所在路径
- 在对应的工具机分别执行del_pre.sh脚本,即可开始目标环境对应表的数据清空,具体命令如下:
sh del_pre.sh- del_pre.sh脚本内容如下:
#!/bin/bash
nohup python datax.py del_table_1.json --jvm="-Xms16G -Xmx16G" > del_table_1.log &
2、 数据迁移
在不停服务的情况下把源环境内数据量较大的数据表全部迁移到目标环境内对应的数据表。
1)配置DataX任务
在DataX对数据表配置相应的json文件,迁移配置的具体内容如下:
{
"job": {
"setting": {
"speed": {
"channel": "5"
}
},
"content": [{
"reader": {
"name": "otsreader",
"parameter": {
"endpoint": "http://xxx.vpc.ots.yyy.com/",
"accessId": "src_accessId",
"accessKey": "src_ accessKey ",
"instanceName": " src_instanceName",
"table": "tablename",
"column": [{
"name": "xxxxx"
},
{
"name": "xxxxx"
}
],
"range": {
"begin": [{
"type": "INF_MIN"
}],
"end": [{
"type": "INF_MAX"
}]
}
}
},
"writer": {
"name": "otswriter",
"parameter": {
"endpoint": "http://xxx.vpc.ots.yun.zzz.com/",
"accessId": "dest_accessId",
"accessKey": "dest_accessKey",
"instanceName": " dest_instanceName",
"table": " tablename ",
"primaryKey": [{
"name": "xxxxx",
"type": "string"
}],
"column": [{
"name": "xxxxx",
"type": "string"
},
{
"name": "xxxxx",
"type": "string"
}
],
"writeMode": "PutRow"
}
}
}]
}
}需注意,由于OTS本身是NoSQL系统,在迁移数据的配置中,必须配置所有的属性列,否则会缺失对应属性列的值。
2) 执行datax任务
- 登录datax所在ECS后,进入datax所在路径
- 在对应的工具机分别执行pre_transfer.sh脚本,即可开始专有域OTS到专有云OTS的数据迁移,具体命令如下:
sh pre_transfer.sh- pre_transfer.sh脚本内容如下:
#!/bin/bash
nohup python datax.py table_1.json --jvm="-Xms16G -Xmx16G" >table_1.log &呐,此时,万事俱备,数据只待迁移!

在迁移之前,让我们最后再对焦一下数据迁移的目标:

下面,进入正式迁移阶段!
三、正式迁移阶段
1、OTS数据静默
OTS的数据静默主要是通过观察对应表的数据是否存在变化来判断,校验方式主要包括行数统计、内容统计。
1)行数统计
因OTS本身不提供count接口,所以采用在hive创建OTS外部表的方式,读取OTS数据并计算对应数据表的行数,具体操作如下:
- 创建外部表
启动hive,创建上述数据表对应的外部表;为提高统计效率,外部表可以只读取OTS的主键列,建表语句示例如下:
CREATE EXTERNAL TABLE t_oilcard_expenses_old
(h_card_no string)
STORED BY 'com.aliyun.openservices.tablestore.hive.TableStoreStorageHandler'
WITH SERDEPROPERTIES(
"tablestore.columns.mapping"="card_no")
TBLPROPERTIES ("tablestore.endpoint"="$endpoint ","tablestore.instance"="instanceName","tablestore.access_key_id"="ak","tablestore.access_key_secret"="sk","tablestore.table.name"="tableName");- 进入脚本所在路径
登录Hadoop集群master所在ECS,进入hive所在目录 - 执行行数统计
执行pre_all_count.sh脚本,即可开始源环境内OTS对应表的行数统计
nohup sh pre_all_count.sh >pre_all_count.log &- pre_all_count.sh脚本内容如下:
#!/bin/bash
./bin/hive -e "use ots;select count(h_card_no) from tableName;" >table.rs & 连续执行两次行数统计,若两次统计结果一致则说明数据已经静默,数据写入以停止。
2)内容统计
由于部分数据表分区键对应的值比较单一,导致数据全部存储在同一个分区。若采用hive统计行数会耗时太久,所以对于这个表使用datax将OTS数据导入oss的方式进行内容统计,具体操作如下:
- 进入脚本所在路径
登录上述表格对应的ECS,进入datax所在路径; - 执行内容校验
a、执行check_table.sh脚本,即可将源环境内OTS数据表导出到OSS;
sh check_table.sh- check_table.sh脚本内容如下:
#!/bin/bash
nohup python datax.py table.json --jvm="-Xms8G -Xmx8G">ots2oss01.log &b、获取OSS object的ETAG值,写入对应文件table_check01.rs
连续执行两次内容统计,对比两次导出object的ETAG值,若结果一致则说明数据已经静默,数据写入以停止。
2、OTS数据迁移
1)准备工作
为保证迁移后新老环境数据一致,防止目标环境因测试产生遗留脏数据,在进行数据迁移前,需要将目标环境的OTS的其余全量表进行数据清空。

「数据清空方式」主要有Drop、Delete,两者的区别如下:
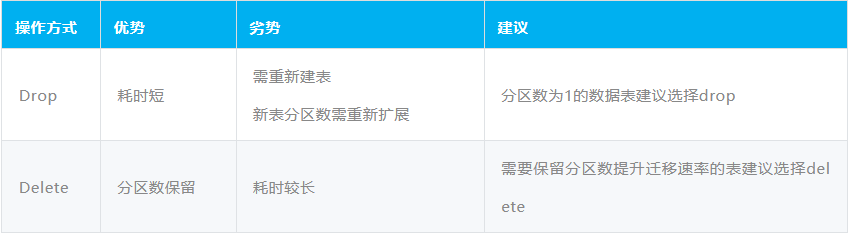
a、Drop表操作
登录OTS图形化客户端所在工具机,使用如下信息连接指定OTS实例,并进行对应表的drop操作;
AK: dest_accessId
SK: dest_accessKey
InstanceName: InstanceName
Endpoint:endpoint确认删除后,再在客户端重新创建对应的数据。
b、 Delete表操作
Delete操作是通过DataX工具直接删除表内数据,无需重新建表。DataX所需的配置文件参考2.1.1所示。
- 登录datax所在ECS后,进入datax所在路径
- 在对应的工具机分别执行delete脚本,即可开始目标环境OTS的对应表的数据清空,具体命令如下:
sh del_table_01.sh- del_table_01.sh脚本内容如下:
#!/bin/bash
nohup python datax.py del_table.json --jvm="-Xms16G -Xmx16G">del_table.log &2)数据迁移
在源环境停止服务的情况下把双写模式中的增量表全量迁移以及其余小表全部迁移到目标环境内对应的数据表。
具体操作如下:
a、配置DataX任务
在DataX对上述数据表配置相应的json文件,迁移配置的具体内容参考2.2.1,在迁移数据的配置中,需要列全所有的属性列。
b、执行DataX任务
- 登录DataX所在ECS后,进入DataX所在路径
- 在对应的工具机分别执行transfer.sh脚本,即可开始专有域OTS到专有云OTS的数据迁移,具体命令如下:
sh transfer.sh- transfer.sh脚本内容如下:
#!/bin/bash
nohup python datax.py Table.json >Table.log &
3、OTS数据校验
新老环境OTS的数据校验方式均包括行数统计、内容统计,具体如下:
1)源环境数据统计
源环境OTS数据表的数据量统计依据数据静默期间最后一次的统计结果即可。
2)目标环境数据统计
a、行数统计
因OTS本身不提供count接口,且目标环境ODPS支持创建OTS外部表,所以采用在ODPS创建OTS外部表的方式,读取OTS数据并计算对应数据表的行数,具体操作如下:
- 创建外部表
登录odpscmd,创建上述数据表对应的外部表; - 进入脚本所在路径
登录odpscmd工具所在ECS,进入odps所在路径; - 执行行数统计
执行newots_count.sh脚本,即可进行目标环境内OTS对应表的行数统计;
nohup sh newots_count.sh >newots_count.log &- newots_count.sh脚本内容如下:
#!/bin/bash
./bin/odpscmd -e "select count(h_card_no) from tableName;" >table.rs
b、 内容统计由于源环境的部分数据表采用内容统计的方式进行数据校验,为了方便对比数据是否一致,所以目标环境也采用内容统计的方式,具体操作参考3.1.2。

数栈技术分享:OTS数据迁移——我们不生产数据,我们是大数据的搬运工的更多相关文章
- 数据迁移_把RAC环境备份的数据,恢复到另一台单机Oracle本地文件系统下
数据迁移_把RAC环境备份的数据,恢复到另一台单机Oracle本地文件系统下 作者:Eric 微信:loveoracle11g 1.创建pfile文件 # su - ora11g # cd $ORAC ...
- 孙荣辛|大数据穿针引线进阶必看——Google经典大数据知识
大数据技术的发展是一个非常典型的技术工程的发展过程,荣辛通过对于谷歌经典论文的盘点,希望可以帮助工程师们看到技术的探索.选择过程,以及最终历史告诉我们什么是正确的选择. 何为大数据 "大 ...
- 写论文,没数据?R语言抓取网页大数据
写论文,没数据?R语言抓取网页大数据 纵观国内外,大数据的市场发展迅猛,政府的扶持也达到了空前的力度,甚至将大数据纳入发展战略.如此形势为社会各界提供了很多机遇和挑战,而我们作为卫生(医学)统计领域的 ...
- 一起来学大数据——走进Linux之门,学习大数据的重中之重
昨天我们看了有关大数据Hadoop的一些知识点,但是要在学习大数据之前,我们还是要为大数据的环境做一些的部署. 那么,今天我们就来讲讲开启我们大数据之路的Linux,跟上我们的脚步yo~ Linux介 ...
- Oracle大数据解决方案》学习笔记5——Oracle大数据机的配置、部署架构和监控-1(BDA Config, Deployment Arch, and Monitoring)
原创预见未来to50 发布于2018-12-05 16:18:48 阅读数 146 收藏 展开 这章的内容很多,有的学了. 1. Oracle大数据机——灵活和可扩展的架构 2. Hadoop集群的 ...
- 【技术与商业案例解读笔记】095:Google大数据三驾马车笔记
1.谷歌三驾马车地位 [关键词]开启时代,指明方向 聊起大数据,我们通常言必称谷歌,谷歌有“三驾马车”:谷歌文件系统(GFS).MapReduce和BigTable.谷歌的“三驾马车”开启了大数据时 ...
- 民生银行十五年的数据体系建设,深入解读阿拉丁大数据生态圈、人人BI 是如何养成的?【转】
早在今年的上半年我应邀参加了由 Smartbi 主办的一个小型数据分析交流活动,在活动现场第一次了解到了民生银行的阿拉丁项目.由于时间关系,嘉宾现场分享的内容非常有限.凭着多年对行业研究和对解决方案的 ...
- 大数据 -- Cloudera Manager(简称CM)+CDH构建大数据平台
一.Cloudera Manager介绍 Cloudera Manager(简称CM)是Cloudera公司开发的一款大数据集群安装部署利器,这款利器具有集群自动化安装.中心化管理.集群监控.报警等功 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 大数据基础--R语言(刘鹏《大数据》课后习题答案)
1.R语言是解释性语言还是编译性语言? 解释性语言 2.简述R语言的基本功能. R语言是一套完整的数据处理.计算和制图软件系统,主要包括以下功能: (1)数据存储和处理功能,丰富的数据读取与存 ...
随机推荐
- Linux 实现OpenSSL 服务器端客户端通信
1.OpenSSL安装 详情参考博文:https://blog.csdn.net/qq_39521181/article/details/96457673 2.SSL 在学习openssl编程之前,先 ...
- 生产环境swarm集群规划和管理
swarm集群角色 swarm集群中有两种角色,manager node和 worker ndoe. manager的功能: 维护集群状态 任务调度 为swarm集群提供HTTP API 可以创建只有 ...
- 【JDBC第4章】操作BLOB类型字段
第4章:操作BLOB类型字段 4.1 MySQL BLOB类型 MySQL中,BLOB是一个二进制大型对象,是一个可以存储大量数据的容器,它能容纳不同大小的数据. 插入BLOB类型的数据必须使用Pre ...
- redis的作用:高性能和高并发
一.高性能 假设这么个场景,你有个操作,一个请求过来,吭哧吭哧你各种乱七八糟操作mysql,半天查出来一个结果,耗时600ms.但是这个结果可能接下来几个小时都不会变了,或者变了也可以不用立即反馈给用 ...
- Git放弃本地修改,强制拉取最新版
git fetch –-all git reset –-hard origin/master git fetch : 下载远程的库的内容(不做合并): git reset :指令把HEAD指向mast ...
- Asp.net mvc基础(十四)Entity Framework
一.EntityFramework介绍 1.ORM:Object Relation Mapping,用操作对象的方式来操作数据库 2.ORM工具有很多,其中Dapper.PetaPoco.NHiber ...
- [亲测]ThinkPHP中where方法中变量不解析的解决方法
2018年5月4日 01:15 血的教训,今天做一个项目,需要批量更新数据,所以where中必须用变量.发现where里的变量不解析并且会直接报错,然后通过搜索发现可以在双引号中的左右加号中包裹变量 ...
- DP刷题总结-2
同步于Luogu blog T1 AT_joisc2007_buildi ビルの飾り付け (Building) 简化题意 最长上升子序列模板 分析 \(O(n^2)\)做法 考虑DP 定义状态:\(d ...
- CF1573B题解
题意: 对于给定的序列 aA1,aA2,-,aAna_{A1},a_{A2},-,a_{An}aA1,aA2,-,aAn.bB1,bB2,-,bBnb_{B1},b_{B2},-,b_{Bn}b ...
- AutoFac学习Demo1——官网Demo
AutoFac实现Demo1 1.创建一个工作台(.NET Core)程序AutofacDemo1,nuget引入AutoFac,搜索第一个就是 2.创建输出接口IOutput及实现ConsoleOu ...