构建基于Serverless架构的向量检索MCP Server
构建基于Serverless架构的向量检索MCP Server
随着LLM与Agent的快速发展,向量检索成为构建高效语义搜索和智能推荐系统的关键技术之一。OpenSearch Service 作为一款成熟的搜索与分析平台,凭借其内置的向量检索能力和丰富的生态集成,成为实现大规模、高性能向量数据库的重要选择。本文聚焦于基于 Serverless 架构的 Amazon Serverless MCP Server 的设计与实现,旨在提供一个标准化、弹性可扩展且零运维的向量检索服务端,方便 AI Agent 及自动化工具高效调用。通过结合 AWS Lambda、API Gateway 与 OpenSearch 的强大能力,本方案不仅实现了实时流式通信和安全访问控制,还极大地降低了复杂度和运营成本,为构建智能云原生搜索与推荐系统提供了可靠基础和实践范例。
Amazon OpenSearch向量数据库
Amazon OpenSearch Service(AOS)是由亚马逊云科技提供的一项全托管搜索和分析服务,基于 Apache 2.0 许可的开源 OpenSearch 引擎演变而来。它同时支持传统全文检索与向量检索,并包含 OpenSearch Dashboards 可方便进行数据可视化和分析。
当向量数据库概念兴起时,OpenSearch Service 随即引入了用于高维嵌入存储与相似性计算的 k‑NN 插件,支持 FAISS、NMSLIB、Lucene 三种引擎,以及 HNSW 和 IVF 等 ANN 算法。可以为结构化或非结构化数据(如文本、图像、音频)生成向量表示后,存储于 knn_vector 字段,配置相似度度量(余弦、欧氏、内积等),实现高效语义查询。建立在成熟的搜索架构基础之上的Amazon OpenSearch Service,除了能满足海量真实场景(如日志分析、网站检索)外,更支持高效的语义搜索与生成式 AI 用例。
作为一款托管的向量数据库,Amazon OpenSearch Service可以提供以下优势:
- 高性能、低延迟的向量检索:OpenSearch 通过 HNSW 和 IVF 等 ANN 算法,实现对数十亿向量的毫秒级响应,适用于实时推荐和检索场景。配合 UltraWarm 和 Cold 分层存储,能够按冷热数据分层处理,实现成本与性能的最优平衡
- 零运维与弹性扩展:作为 AWS 全托管服务,OpenSearch 自动处理节点管理、扩缩容、备份恢复、安全配置等运维细节。无服务器(Serverless)模式支持资源自动调整,应对流量波动,而无需人工干预
- 高集成能力与通用检索支持:支持向量、关键词、聚合、地理空间等复合查询,同时兼容 CloudWatch、安全认证等 AWS 生态组件,能够与 Bedrock 或 SageMaker 等服务结合,用于构建 RAG、智能聊天机器人、日志异常检测等场景
- 成本优化与资源管理:内置disk-based向量存储/检索与量化功能(如binary量化),可以节约存储空间与内存资源,并降低向量索引查询成本
基于这些优势,本文通过 Amazon Serverless MCP Server 实现了对 Amazon OpenSearch Service 向量检索能力的 Serverless 封装与部署,提供标准化、可扩展的检索服务接口。
Amazon Serverless MCP Server
Amazon Serverless MCP Server 是一套基于 Serverless 架构(如 AWS Lambda 与 API Gateway)实现的 MCP(Model Context Protocol)协议服务端,旨在为 AI Agent(如代码助手、自动化工具等)提供标准化、可扩展的接口。通过该方案,AI 工具可采用支持流式传输(Streamable HTTP)的方式调用 MCP Server 功能,并提供下列优势:
- 零运维与弹性扩展:基于 AWS Lambda 构建的 Serverless MCP Server 不需要预配置服务器,完全由云平台托管,具备按请求计费、自动扩缩容的能力。开发者无需关心基础设施运维,即可获得高可用、可扩展的 MCP 接口能力,尤其适合需求波动大、使用场景分布广的 AI 工具
- 实时流式通信支持:相比传统 HTTP 接口,Serverless MCP Server 支持 Streamable HTTP(例如 chunked transfer 或 Server-Sent Events),允许服务端在同一连接中分批次推送响应。AI Agent 可以持续接收上下文状态、执行日志或中间结果,这在处理长时间任务或需要上下文连续性的应用场景中尤为重要
- 安全性强、权限可控:支持灵活的权限管理与授权机制,并提供详细的访问日志,便于防止服务滥用及满足审计需求,确保系统运行的安全性与可追溯性
Serverless MCP Server 为 AI Agent 接入云原生能力提供了一个标准、高效、易用的实现方案。它不仅降低了 AI 工具调用云资源的门槛,也通过安全、流式、可组合的能力模型,使自动化开发与部署更加智能化与模块化。接下来,本文将通过示例演示如何实现基于 Serverless 架构的 AOS 向量检索 MCP Server。
AOS 向量检索 Serverless MCP Server
架构概述
该解决方案采用完全无服务器架构,主要包含以下组件:
1. AWS Lambda: 处理MCP请求和响应
2. Amazon API Gateway: 提供HTTP接口
3. Amazon OpenSearch Service: 存储文档和向量数据
4. Amazon DynamoDB: 管理MCP会话状态
5. 第三方嵌入服务: 将文本转换为向量表示(中国区使用硅基流动Silicon Flow API)
对应架构图如下所示:
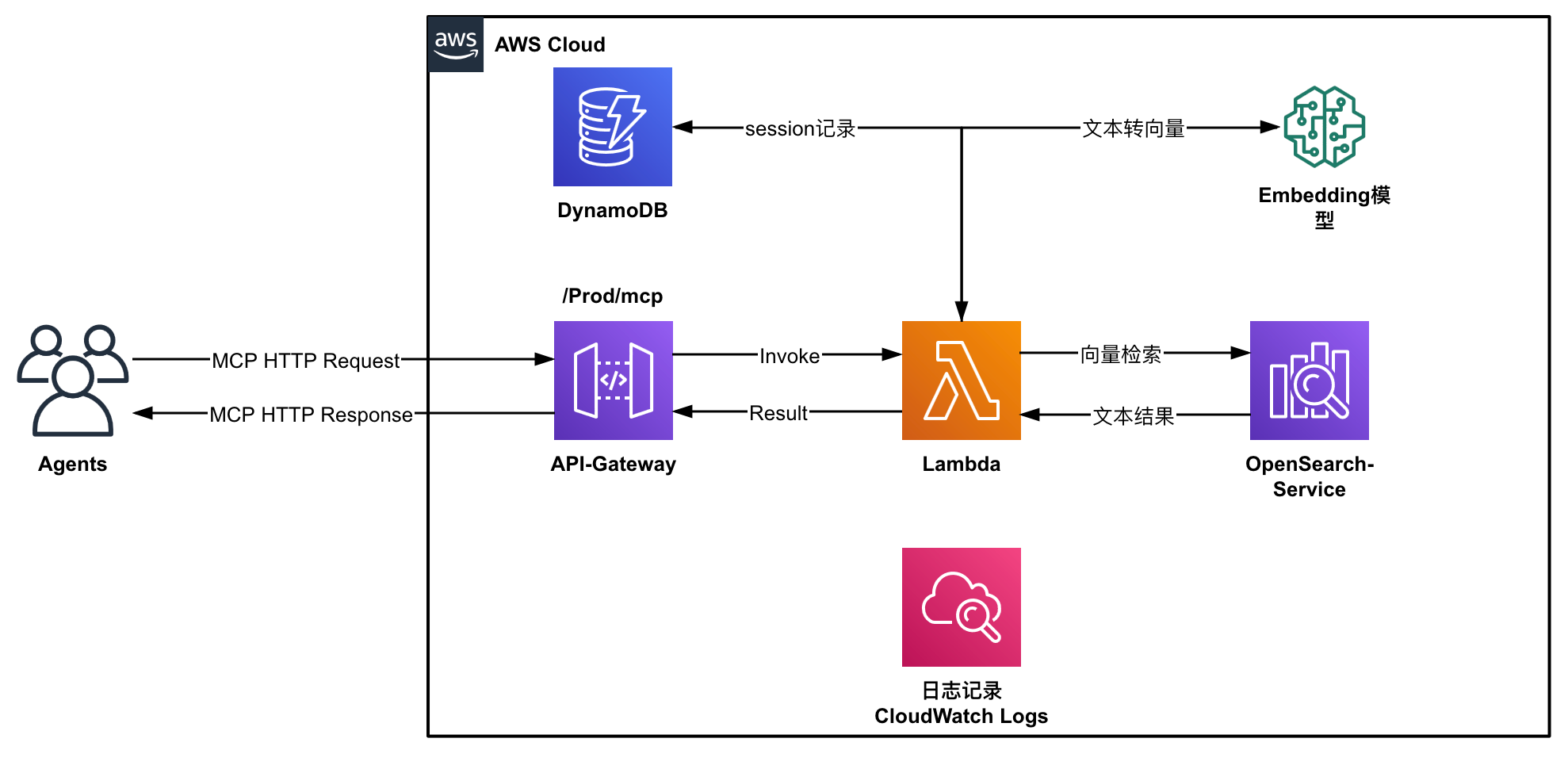
该MCP服务器提供两个主要功能:
- 文本索引与嵌入: 将文本转换为向量并存储到Amazon OpenSearch Service中
- 相似度搜索: 基于向量相似度查找相关文档
实现步骤
下面介绍此Serverless MCP的具体实现步骤以及部分关键代码解释,项目源码与部署说明请参考aos-mcp-serverless。
1. OpenSearch客户端
由于后端需要与Amazon OpenSearch(AOS)做交互,所以首先需要有一个与AOS交互的客户端,此客户端类提供一个初始化的方法,以及对AOS做搜索与检索的方法:
class OpenSearchClient:
def __init__(
self,
opensearch_host: str,
opensearch_port: int,
index_name: str,
username: str = None,
password: str = None,
# 其他参数...
):
# 初始化OpenSearch客户端... async def search_documents(self, query: str, size: int = 10) -> dict:
"""搜索文档"""
# 实现搜索逻辑... async def write_document(self, document_id: str, document: dict) -> dict:
"""写入文档"""
# 实现文档写入逻辑...
2. 文本转向量功能
无论在对AOS做向量注入还是检索,都需要一个对应的向量模型将文本转为向量。这里使用中国区硅基流动提供的BGE-M3模型。参考硅基流动提供的API格式,使用下面的方法将文本转为向量:
async def generate_embedding(text: str, model: str = None) -> Dict:
"""使用Silicon Flow API生成文本的向量嵌入"""
try:
model_name = model if model else DEFAULT_MODEL payload = {
"model": model_name,
"input": text,
"encoding_format": "float"
} headers = {
"Authorization": f"Bearer {embedding_api_token}",
"Content-Type": "application/json"
} response = requests.post(EMBEDDING_API_URL, json=payload, headers=headers)
response.raise_for_status() result = response.json()
return {
"status": "success",
"embedding": result.get("data", [{}])[0].get("embedding", []),
"model": model_name
}
except Exception as e:
return {"status": "error", "message": f"API请求失败: {str(e)}"}
3. Lambda实现MCP Server
在通过Lambda实现MCP Server的功能时,主要参考sample-serverless-mcp-server项目。此项目主要实现了一个基于 AWS Lambda 的 MCP 服务器,它的核心功能包括:
- LambdaMCPServer 类:这是整个 MCP 服务器的核心类,负责处理 JSON-RPC 请求,管理工具注册和调用,以及维护会话状态。它提供了一个装饰器 @tool() 用于注册可被 AI 模型调用的tool
- 会话管理:通过 SessionManager 类与 DynamoDB 交互,创建、获取、更新和删除会话数据,支持有状态的对话
- 类型定义:包含了 JSON-RPC 请求和响应的数据模型,如 JSONRPCRequest、JSONRPCResponse、ServerInfo 等,确保协议一致性
- 工具注册机制:通过反射和类型提示自动生成工具的输入模式,简化了工具开发流程
- 错误处理:提供了标准化的错误响应机制,将内部错误映射到 JSON-RPC 错误码
基于这个项目,即可直接通过LambdaMCPServer类提供的@tool()装饰器,将自定的方法注册为Lambda支持的MCP tool。在此项目中的app.py中,我们提供了两个tool,分别为:
@mcp_server.tool()
def index_text_with_embedding(text: str, document_id: str = None, metadata: str = "{}") -> Dict:
"""
将文本转换为向量并索引到知识库中
"""
# 实现索引逻辑... @mcp_server.tool()
def text_similarity_search(text: str, k: int = 10, score: float = 0.0) -> Dict:
"""
通过向量相似度搜索相关文档
"""
# 实现相似度搜索逻辑...
除此之外,在安全认证部分,使用了API Gateway自定义授权器实现安全认证,与之对应的lambda实现代码为:
def lambda_handler(event, context):
"""Lambda授权器函数"""
token = event.get('authorizationToken')
expected_token = os.environ.get('MCP_AUTH_TOKEN') if token == expected_token:
return generate_policy('Allow', event['methodArn'])
else:
return generate_policy('Deny', event['methodArn'])
4. 部署服务
在准备好lambda函数后,即可将其前端的API Gateway以及管理session的DynamoDB一起部署到亚马逊云上。这里使用SAM CLI部署服务,并在项目中提供了示例模板:
# 构建项目
sam build # 部署项目(中国区)
sam deploy --profile cn --parameter-overrides \
"McpAuthToken=your-auth-token" \
"OpenSearchHost=your-opensearch-endpoint" \
"OpenSearchUsername=your-username" \
"OpenSearchPassword=your-password" \
"EmbeddingApiToken=your-embedding-api-token"
测试使用
部署完成后,在测试阶段需要使用支持 Streamable HTTP 的 MCP 客户端。本文采用亚马逊云科技官方博客中提供的 Python 版 Streamable HTTP MCP 客户端,对已部署的 Serverless MCP Server 进行功能验证与测试。
在启动客户端后,填写部署后的API Gateway endpoint以及auth token,然后点击Connect,即可看到“List Tools”选项。
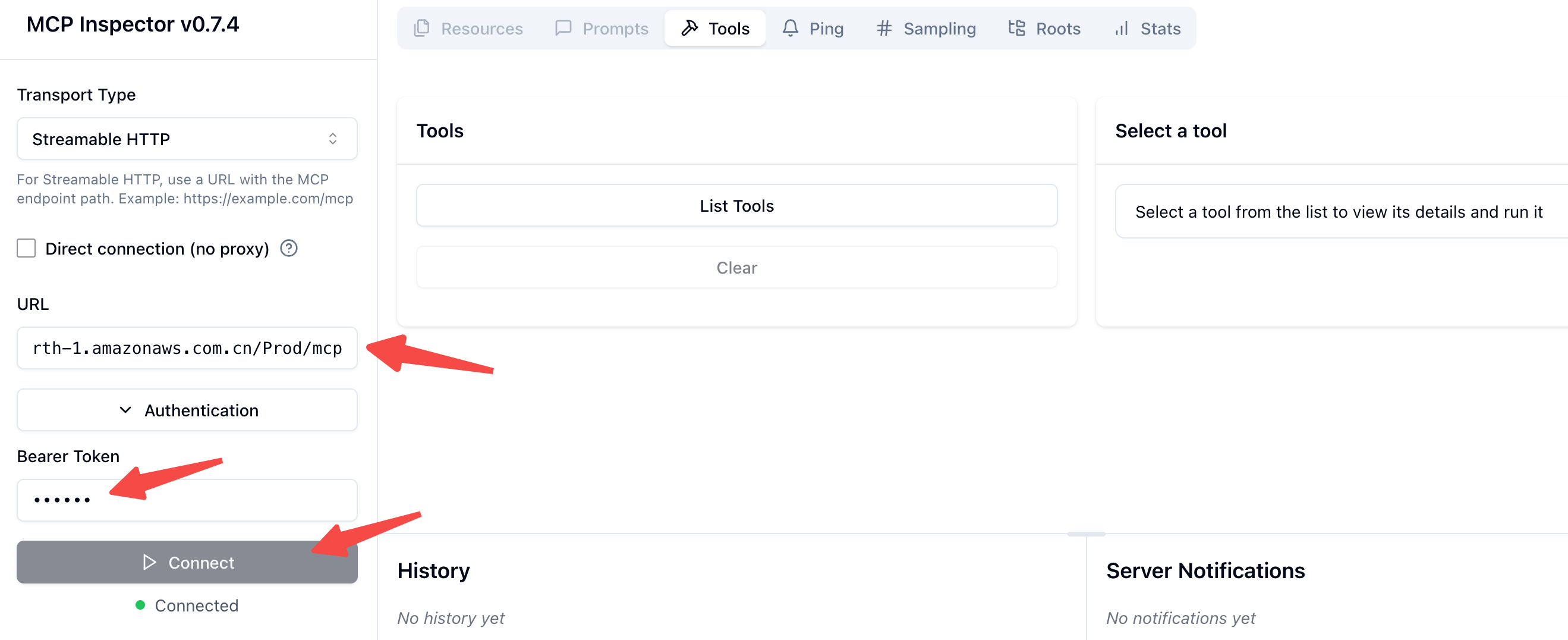
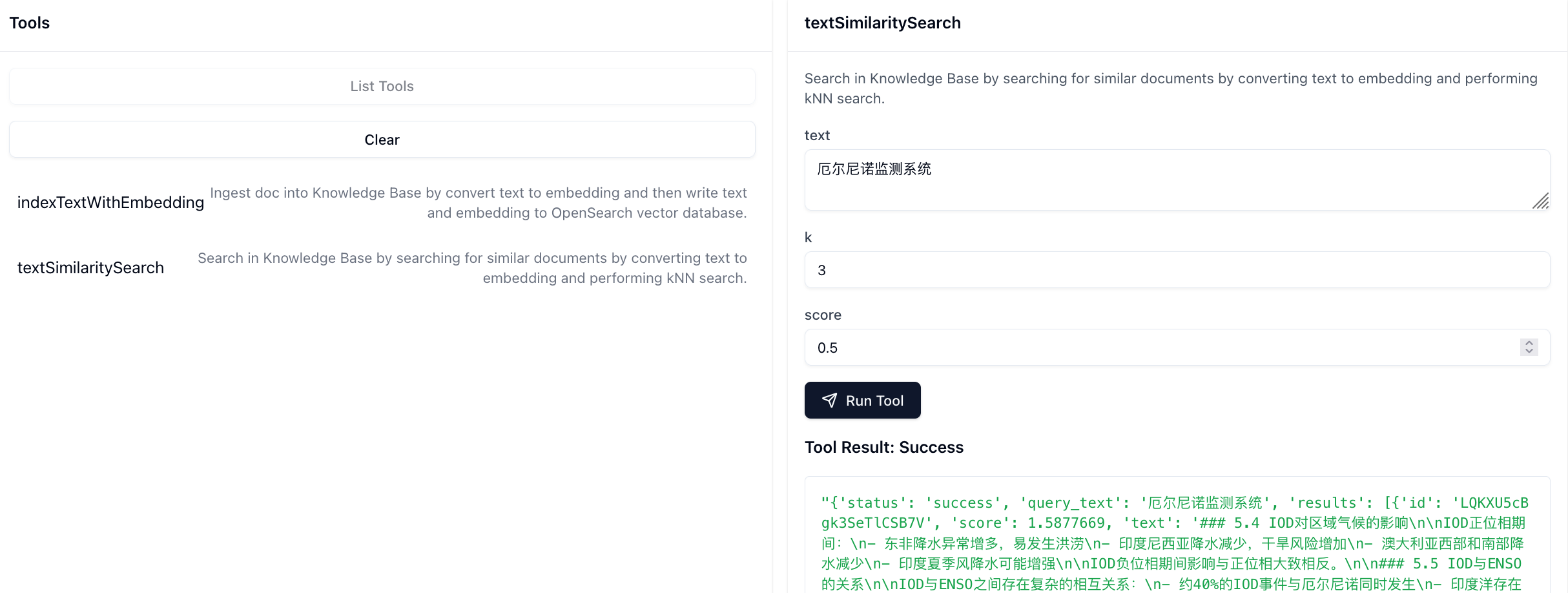
点击List Tools,然后点击textSimilaritySearch即可测试方法,如下图所示,可以得到正常的Tool Result返回:
使用Strands Agent调用Serverless MCP Server
参考 Strands Agent 对 Tool 的定义规范,如retrieve.py。本文同样提供了兼容 Strands Agent 的 Tool,用于调用该 Serverless MCP Server。示例规范主要包含两部分:
- Tool的定义:提供详细的tool的说明,包括名称、描述、输入/输出说明以及示例用法
- Tool的实现:提供一个与tool同名的函数,传入首个参数为ToolUse类型的对象
具体实现细节请参见对应的similarity_search.py源码。
在实现了这个tool方法后,在strands agent里调用此tool非常简单,例如:
agent = Agent(tools=['similarity_search.py'])
API_ENDPOINT = os.getenv("API_ENDPOINT", "")
AUTH_TOKEN = os.getenv("AUTH_TOKEN", "")
results = agent.tool.similarity_search(
text="厄尔尼诺监测系统",
k=5,
score=0.5,
api_endpoint=API_ENDPOINT,
auth_token=AUTH_TOKEN
)
总结
本文介绍了基于 AWS Lambda 与 API Gateway 的 Serverless OpenSearch 向量检索 MCP 服务器的设计与实现,展示了如何高效、弹性地构建面向 AI Agent 的语义搜索和知识库服务。借助 Amazon OpenSearch Service 强大的向量检索能力和成熟的托管生态,结合无服务器架构的零运维特性,实现了高性能、低延迟、成本可控的检索解决方案。通过标准化的 MCP 协议接口与流式通信支持,该方案极大降低了 AI 工具接入云原生检索能力的门槛,提升了自动化开发与部署的智能化和模块化水平。整体架构不仅适合海量文本、图像等多模态数据的语义搜索,还具备良好的安全性和权限管理,尤其适合在 AWS 中国区等环境快速落地。未来,该 Serverless MCP 方案可灵活扩展至更多 AI 应用场景,成为构建智能云原生工具链的重要基石。
构建基于Serverless架构的向量检索MCP Server的更多相关文章
- 轻松构建基于 Serverless 架构的弹性高可用音视频处理系统
前言 随着计算机技术和 Internet 的日新月异,视频点播技术因其良好的人机交互性和流媒体传输技术倍受教育.娱乐等行业青睐,而在当前, 云计算平台厂商的产品线不断成熟完善, 如果想要搭建视频点播类 ...
- 教你轻松构建基于 Serverless 架构的小程序
前言 自 2017 年第一批小程序上线以来,越来越多的移动端应用以小程序的形式呈现.小程序触手可及.用完即走的优点,大大降低了用户的使用负担,也使小程序得到了广泛的传播.在阿里巴巴,小程序也被广泛地应 ...
- COS 数据湖最佳实践:基于 Serverless 架构的入湖方案
01 前言 数据湖(Data Lake)概念自2011年被推出后,其概念定位.架构设计和相关技术都得到了飞速发展和众多实践,数据湖也从单一数据存储池概念演进为包括 ETL 分析.数据转换及数据处理的下 ...
- 构建基于分布式SOA架构的统一身份认证体系
摘要:本文充分利用SOA架构松耦合的特点,通过规范统一网络接口实现业务系统整合,既提升系统安全性,又简化资源访问操作,具有重要的理论和现实意义. 统一身份认证旨在将分散在各个信息系统中的用户和权限资源 ...
- 从函数计算到 Serverless 架构
前言 随着 Serverless 架构的不断发展,各云厂商和开源社区都已经在布局 Serverless 领域,一方面表现在云厂商推出传统服务/业务的 Serverless 化版本,或者 Serverl ...
- Serverless 架构演进与实践
Serverless 架构演进与实践 1. 介绍 Serverless 并不仅仅是一个概念,很多地方都已经有了它的影子和思想,本文将给大家介绍最近比较火的 Serverless. 首先放出官方对 Se ...
- Cola Cloud 基于 Spring Boot, Spring Cloud 构建微服务架构企业级开发平台
Cola Cloud 基于 Spring Boot, Spring Cloud 构建微服务架构企业级开发平台: https://gitee.com/leecho/cola-cloud
- 【转】Serverless架构
这是来自martinfowler.com的Serverless架构一文的大意翻译. 什么是Serverless? Serverless首先是用于描述我们的应用程序是明显或充分地依赖第三方应用或服 ...
- 用 VIPER 构建 iOS 应用架构(2)
[编者按]本篇文章由 Jeff Gilbert 和 Conrad Stoll 共同编写,通过构建一个基础示例应用,深入了解 VIPER,并从视图.交互器等多个部件理清 VIPER 的整体布局及思路.通 ...
- Serverless 架构:用服务代替服务器
Serverless 架构:用服务代替服务器 转载本文需注明出处:EAII企业架构创新研究院(微信号:eaworld),违者必究.如需 加入微信群参与微课堂.架构设计与讨论直播请直接回复此公众号:&q ...
随机推荐
- k8s v1.16.3,Unable to connect to the server: x509: certificate has expired or is not yet valid
前言 kubernetes 版本为 v1.16.3 使用 kubelet get node 后报错: x509: certificate has expired or is not yet valid ...
- 搭建自己的OCR服务,第一步:选择合适的开源OCR项目
一.OCR是什么? 光学字符识别(Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程. 亦即将图像中的文字进行识别 ...
- 【SpringCloud】各种组件的更新情况
关于Cloud各种组件的停更/升级/替换 由停更引发的"升级惨案" 停更不停用 被动修复bugs 不再接受合并请求 不再发布新版本 以前 now2020 服务注册中心 Eureka ...
- CoreOS 手动更新
以阿里云 ECS 安装的 CoreOS 为例,你家装的 CoreOS 基本也一样啦. 查看和修改更新组 第一个问题:"什么是更新组?",请先看CoreOS 发行版本介绍 # 查看更 ...
- CSS实现单行显示文本并适应浏览器大小
实现 .text { white-space:nowrap; /*文本不换行*/ overflow: hidden; /*超出文本隐藏*/ text-overflow:ell ...
- ubuntu 安装挂载mysql, redis和mongodb服务
因为有两台电脑,所以准备把ubuntu电脑作成对外服务提供,各种数据库,中间件都使用docker安装管理,然后挂载配置和日志到本地,提供给另一台电脑的对外服务. 1. 安装docker sudo ap ...
- exe4j工具使用-jar包转exe可执行文件
exe4j介绍 exe4j可以将java打包的jar包转为exe可执行文件,实现在没有jdk环境下运行jar包. 下载链接 https://pan.baidu.com/s/1sfEJyxPABmhsl ...
- CF1774C题解
题目传送门 假设最后一场的环境为 111,即温度大的人赢,那么温度为 111 的人即使活到了最后一场也必输. 同理,如果最后 kkk 场的环境都为 111,那么有 k(1∼k)k(1\sim k)k( ...
- 聊聊四种实时通信技术:长轮询、短轮询、WebSocket 和 SSE
这篇文章,我们聊聊 四种实时通信技术:短轮询.长轮询.WebSocket 和 SSE . 1 短轮询 浏览器 定时(如每秒)向服务器发送 HTTP 请求,服务器立即返回当前数据(无论是否有更新). 优 ...
- 从零开始:基于CUDA 12.6的YOLOv5模型训练实战(RTX 2050显卡全流程)
基于cuda12.6训练yolov5模型 前面完成了使用CPU调用yolov5s模型进行识别车辆,现在想训练自己的模型进行目标识别,使用CPU效率太低,尝试使用GPU加速的Pytorch,再重新整理了 ...