论文笔记:AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models(AlphaEdit)
论文发表于人工智能顶会ICLR(原文链接)。基于定位和修改的模型编辑方法(针对ROME和MEMIT等)会破坏LLM中最初保存的知识,特别是在顺序编辑场景。为此,本文提出AlphaEdit:
1、在将保留知识应用于参数之前,将扰动投影到保留知识的零空间上。
2、从理论上证明,这种预测确保了在查询保留的知识时,编辑后的LLM的输出保持不变,从而减轻中断问题。
3、对各种LLM(包括LLaMA3、GPT2XL和GPT-J)的广泛实验表明,AlphaEdit只需一行额外的投影代码,即可将大多数定位编辑方法的性能平均提高36.4%。
阅读本文请同时参考原始论文图表。
AlphaEdit
零空间
基于前面ROME/MEMIT的工作,对于LLM中的MLP矩阵$W$,可被表示为关于已有知识$(K_0,V_0)$的优化结果:
$W= \arg \min\limits_{\tilde{W}} \left\| \tilde{W} K_0 - V_0 \right\|^2$
其中矩阵$K_0\in \mathbb{R}^{d_0\times n},V_0\in \mathbb{R}^{d_0\times n}$,$n$表示已有知识数量。对于新增知识$(K_1,V_1)$,MEMIT的做法为优化扰动$\Delta$来更新$W$:
$\Delta = \arg \min\limits_{\tilde{\Delta}} \left( \left\| (W + \tilde{\Delta}) K_1 - V_1 \right\|^2 + \left\| (W + \tilde{\Delta}) K_0 - V_0 \right\|^2 \right)$
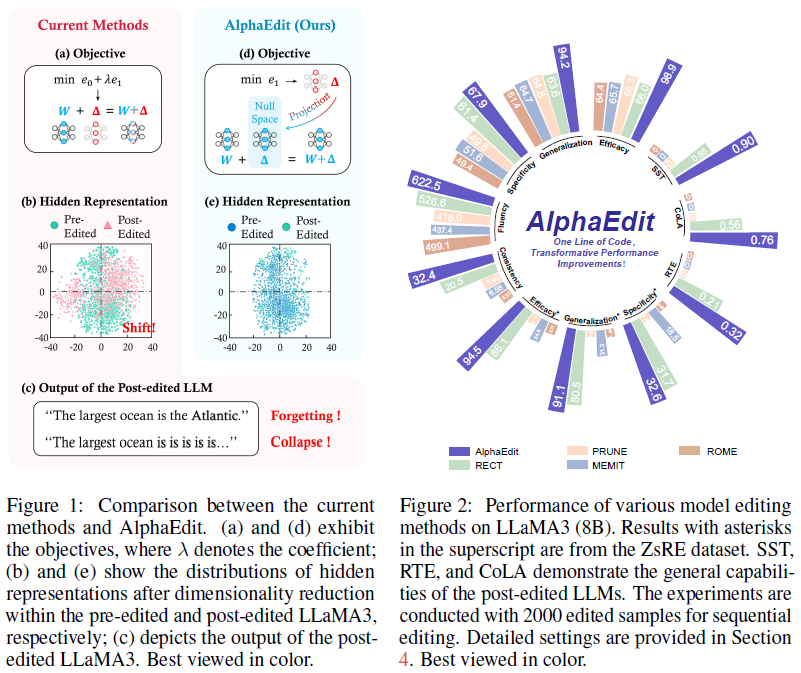
上式为二次优化,可通过求导直接获得闭式解。然而,耦合的优化不可避免会是扰动量对原始知识产生影响,从而在终身编辑场景中鲁棒性不强。文中通过将中间token表示映射到二维空间的分布偏移来表明这一观点:如图1be所示,MEMIT在编辑后token表示的分布产生了较大偏移,而AlphaEdit则没有。
因此,AlphaEdit期望找到$K_0$的零空间,把$\Delta$映射到其上,从而权重更新将对这些知识不产生影响。矩阵$A$在矩阵$B$的零空间内,当且仅当$BA=0$。也就是说,期望找到$\Delta$有:
$(W + \Delta) K_0 = W K_0 = V_0$
那么如何将$\Delta$映射到$K_0$的零空间呢?
SVD分解获取零空间映射
考虑对称方阵$K_0K_0^T\in\mathbb{R}^{d_0\times d_0}$,对其进行奇异值分解(SVD),得到:
$\{ U, \Lambda, U^T \} = \text{SVD} \left( K_0 K_0^T \right)$
其中$U$为正交矩阵($UU^T =I$),$\Lambda$对角矩阵,主对角线为奇异值。将奇异值在主对角线降序排序:
$\Lambda = \begin{bmatrix} \Lambda_1 & 0 \\ 0 & \Lambda_2 \end{bmatrix}$
取其中为零的部分$\Lambda_2$(假设$\Lambda_2$都很小几乎为0,文中取小于0.01的值)在$U$中对应的特征向量矩阵$\hat{U}\in\mathbb{R}^{d_0\times m}$。则$P = \hat{U}\hat{U}^T$为将任意矩阵映射到$K_0K^T_0$零空间的矩阵。这是由于,对于任意矩阵$\Delta$,有:
$\Delta PK_0K^T_0 = \Delta\hat{U}\hat{U}^TK_0K^T_0= \Delta\hat{U}\hat{U}^TU\Lambda U^T$
由于其中$\hat{U}^TU\Lambda=0$,上式为零。$P$为$K_0K_0^T$的零空间映射矩阵,同时也$K_0$的零空间映射矩阵,这是由于:
\begin{align*} &P K_0 K_0^T = 0 \\ \Rightarrow &P K_0 K^T P^T = 0 \\ \Rightarrow &P K_0 (K P)^T = 0 \\ \Rightarrow & P K_0 = 0 \end{align*}
AlphaEdit优化
基于ROME/EMMIT工作,$K_0K_0^T$可通过计算10万条数据获得,即可进一步获得映射矩阵$P$。有了$P$,优化就无需再考虑原有知识$K_0$,则AlphaEdit将优化式改为:
$\Delta = \arg \min\limits_{\tilde{\Delta}} \left( \left\| (W + \tilde{\Delta} P) K_1 - V_1 \right\|^2 + \left\| \tilde{\Delta} P \right\|^2 +\left\| \tilde{\Delta} P K_p\right\|^2\right)$
其中第二项控制$\Delta$的范数,避免数值过大,第三项额外考虑终身编辑场景中已编辑的知识$(K_p,V_p)$。原始MEMIT没有考虑第三项。求导得到方程:
$(\Delta PK_1 - R)K_1^T P + \Delta P + \Delta PK_p K_p^T P = 0$
其中$R=V_1 −WK_1$表示新值$V_1$与原始矩阵在新键下的残差。可得AlphaEdit的矩阵变化量$\Delta_\text{AlphaEdit}$为:
$\Delta_\text{AlphaEdit} =\Delta P = R K_1^T P \left( K_p K_p^T P + K_1 K_1^T P + I \right)^{-1}$
MEMIT的原始闭式解如下所示(额外考虑了已编辑知识),文中表明,仅仅这里改动一行代码,产生较好的编辑性能。
$\Delta_{\text{MEMIT}} = R K_1^T \left( K_p K_p^T P + K_1 K_1^T + K_0 K_0^T \right)^{-1}$
实验
表1:2000条知识的编辑实验,AlphaEdit的编辑批量为100,编辑20次。
图5:token表示分布偏移对比。
其它图表:一些对比和增强效果。
论文笔记:AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models(AlphaEdit)的更多相关文章
- 论文笔记 - Calibrate Before Use: Improving Few-Shot Performance of Language Models
Motivation 无需参数更新的 In-Context Learning 允许使用者在无参数的更新的情况下完成新的下游任务,交互界面是纯粹的自然语言,无 NLP 技术基础的用户也可以创建 NLP ...
- 论文笔记——Deep Model Compression Distilling Knowledge from Noisy Teachers
论文地址:https://arxiv.org/abs/1610.09650 主要思想 这篇文章就是用teacher-student模型,用一个teacher模型来训练一个student模型,同时对te ...
- 【论文笔记】Learning Fashion Compatibility with Bidirectional LSTMs
论文:<Learning Fashion Compatibility with Bidirectional LSTMs> 论文地址:https://arxiv.org/abs/1707.0 ...
- 【论文笔记】用反事实推断方法缓解标题党内容对推荐系统的影响 Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue
Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue Authors: 王文杰,冯福利 ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记之:Natural Language Object Retrieval
论文笔记之:Natural Language Object Retrieval 2017-07-10 16:50:43 本文旨在通过给定的文本描述,在图像中去实现物体的定位和识别.大致流程图如下 ...
- Video Frame Synthesis using Deep Voxel Flow 论文笔记
Video Frame Synthesis using Deep Voxel Flow 论文笔记 arXiv 摘要:本文解决了模拟新的视频帧的问题,要么是现有视频帧之间的插值,要么是紧跟着他们的探索. ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
- Self-paced Clustering Ensemble自步聚类集成论文笔记
Self-paced Clustering Ensemble自步聚类集成论文笔记 2019-06-23 22:20:40 zpainter 阅读数 174 收藏 更多 分类专栏: 论文 版权声明 ...
- 【论文笔记】SamWalker: Social Recommendation with Informative Sampling Strategy
SamWalker: Social Recommendation with Informative Sampling Strategy Authors: Jiawei Chen, Can Wang, ...
随机推荐
- Linux防火墙操作指令
firewall-cmd --list-ports # 查看开放的端口号 firewall-cmd --zone=public --add-port=8888/tcp --permanent # 开放 ...
- ThreadPoolExecutor的corePoolSize、maximumPoolSize和poolSize
看两段源码: 1 public ThreadPoolExecutor(int corePoolSize, 2 3 int maximumPoolSize, 4 5 long keepAliveTime ...
- [开源] Layouter(桌面助手)开源发布
Layouter(桌面助手)是一款简洁.易用.美观的桌面整理软件,基于.net 6开发,支持Windows 7及以上操作系统.以 Apache-2.0 license 进行开源. 开源地址 https ...
- 2025dsfz集训Day10:区间、树形DP
Day10:区间.树形DP 区间DP 区间类型动态规划是线性动态规划的拓展,它在分阶段划分问题时,与阶段中元素出现的顺序和由前一阶段的哪些元素合并而来有很大的关系.(例:\(f[i][j]=f[i][ ...
- wso2~介绍
1. Wso2-apim的介绍 WSO2 API Manager 是一个开源的 API 管理解决方案,旨在帮助组织设计.发布.管理和分析 API.它提供了全面的功能,支持企业在现代应用程序开发中实现更 ...
- SQL 日常练习 (十八)
也没啥, 就是入坑 sql 根本停不下来, 势必要达到所谓 "精通" 的地步. 从网上的例子也快搬运完了, 而工作中的 sql 又是万万不能外泄了. 因此想着, 该去哪里搬砖呢, ...
- Django REST框架中处理JWT令牌的认证的源码解析
想了解`JWTAuthentication`这个类的源码解析.`JWTAuthentication`是来自`rest_framework_simplejwt.authentication`模块的,它用 ...
- 端到端自动驾驶系统实战指南:从Comma.ai架构到PyTorch部署
引言:端到端自动驾驶的技术革命 在自动驾驶技术演进历程中,端到端(End-to-End)架构正引领新一轮技术革命.不同于传统分模块处理感知.规划.控制的方案,端到端系统通过深度神经网络直接建立传感器原 ...
- JVM知识总结-01
1 程序计数器 程序计数寄存器(Program Counter Register),是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器.在虚拟机的概念模型里,字节码解释器工作时就是 ...
- AI工程师跑路了-怎么办?
从雪山飞狐到百年孤独 百无聊赖中翻开了又一本金庸的小说<雪山飞狐>,江湖侠气,快意恩仇瞬间跃然纸上,唯有最后胡斐那一刀才让读者回到了现实.之前刚读了<明朝那些事儿>,最后重 ...