Python在多个Excel文件中找出缺失数据行数多的文件
本文介绍基于Python语言,针对一个文件夹下大量的Excel表格文件,基于其中每一个文件内、某一列数据的特征,对其加以筛选,并将符合要求与不符合要求的文件分别复制到另外两个新的文件夹中的方法。
首先,我们来明确一下本文的具体需求。现有一个文件夹,其中有大量的Excel表格文件(在本文中我们就以csv格式的文件为例);如下图所示。
其中,每一个Excel表格文件都有着如下图所示的数据格式。
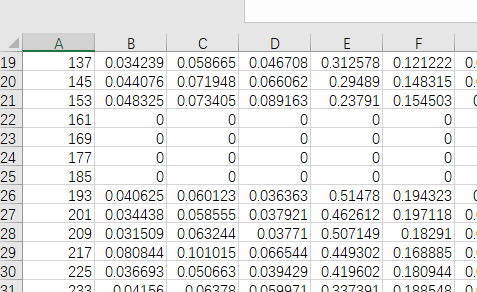
如上图所示,各个文件都有着这样的问题——有些行的数据是无误的,而有些行,除了第一列,其他列都是0值。因此,我们希望就以第2列为标准,找出含有0值数量低于或高于某一阈值的表格文件——其中,0值数量多,肯定不利于我们的分析,我们将其放入一个新的文件夹;而0值数量少的,我们才可以对这一表格文件加以后续的分析,我们就将其放入另一个新的文件夹中。因此,计算出每一个表格文件对应的的0值数量百分比后,我们就进一步将这一Excel表格文件复制到对应的文件夹内。
知道了需求,我们就可以开始代码的撰写。其中,本文用到的代码如下所示。
# -*- coding: utf-8 -*-
"""
Created on Tue May 16 20:19:50 2023
@author: fkxxgis
"""
import os
import shutil
import pandas as pd
def filter_copy_files(original_path, useful_path, useless_path, threshold):
original_all_file = os.listdir(original_path)
for file in original_all_file:
path = os.path.join(original_path, file)
if file.endswith(".csv") and os.path.isfile(path):
df = pd.read_csv(path)
column_value = df.iloc[:, 1]
zero_count = (column_value == 0).sum()
zero_ratio = zero_count / len(column_value)
if zero_ratio < threshold:
new_path = os.path.join(useful_path, file)
shutil.copy(path, new_path)
else:
new_path = os.path.join(useless_path, file)
shutil.copy(path, new_path)
filter_copy_files("E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/13_AllYearAverage",
"E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/14_PointSelection/LowMissingRate",
"E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/14_PointSelection/HighMissingRate",
0.30)
其中,上述代码是一个筛选并复制文件的函数。该函数的目的是根据给定的阈值将具有不同缺失率的文件从一个文件夹复制到另外两个文件夹。
在代码中,filter_copy_files函数接受四个参数:
original_path:原始文件夹的路径,其中包含要筛选的.csv文件。useful_path:有用文件的目标文件夹路径,将满足阈值要求(也就是0值数量低于阈值)的文件复制到此处。useless_path:无用文件的目标文件夹路径,将不满足阈值要求(也就是0值数量高于阈值)的文件复制到此处。threshold:阈值,用于确定文件的缺失率是否满足要求。
函数首先使用os.listdir获取原始文件夹中的所有文件名,然后遍历每个文件名。对于以.csv结尾且为文件的文件,函数使用pd.read_csv读取.csv文件,并通过df.iloc[:, 1]获取第2列的值。
接下来,函数计算第2列中为零的元素数量,并通过将其除以列的总长度来计算缺失率。根据阈值判断缺失率是否满足要求。
如果缺失率小于阈值,函数将文件复制到useful_path目标文件夹中,使用shutil.copy函数实现复制操作。否则,函数将文件复制到useless_path文件夹中。
最后,我们调用了filter_copy_files函数,并传递了相应的参数来执行文件筛选和复制操作。
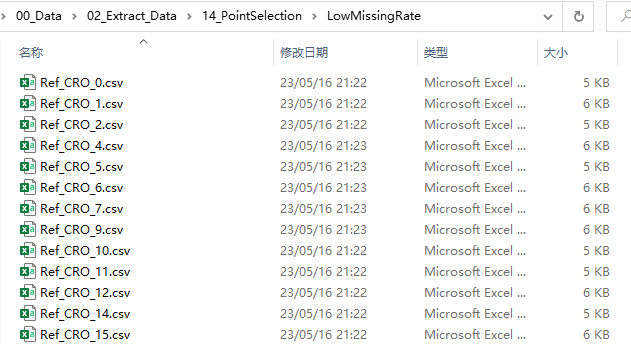
运行上述代码,我们即可在对应的文件夹中看到文件。如下图所示,0值数量低于阈值的表格文件都复制到了这个LowMissingRate文件夹中,我们即可对其加以后续处理;而那些0值数量高于阈值的表格文件,就放到另一个HighMissingRate文件夹中了。
至此,大功告成。
Python在多个Excel文件中找出缺失数据行数多的文件的更多相关文章
- 如何在 Linux 中找出最近或今天被修改的文件
1. 使用 ls 命令,只列出你的 home 文件夹中今天的文件. ls -al --time-style=+%D | grep `date +%D` 其中: -a- 列出所有文件,包括隐藏文件 -l ...
- PHP如何在两个大文件中找出相同的记录?
1.引言 给定a,b两个文件, 分别有x,y行数据, 其中(x, y均大于10亿), 机器内存限制100M,该如何找出其中相同的记录? 2.思路 处理该问题的困难主要是无法将这海量数据一次性读进内存中 ...
- 查看SqlAzure和SQLServer中的每个表数据行数
SqlAzure中的方式: select t.name ,s.row_count from sys.tables t join sys.dm_db_partition_stats s ON t.obj ...
- BD面试题1-两个大文件中找出公共记录[转载]
转自:https://blog.csdn.net/tiankong_/article/details/77234726#commentBox 1.题目 给定a.b两个文件,各存放50亿个url,每个u ...
- 在一张id连续的表中找出缺失的id
有这样一张表: create table tb_lostid( id number(6,0) primary key not null, name nvarchar2(20) not null ) 可 ...
- Linux:从文件中搜索关键字并显示行数(cat,grep函数)
假如有test1.txt的格式如下图所示: 有test2.txt的内容如下: 现需将test2.txt含有的关键字的行搜索出来并显示行数 则可以用到命令: cat test1.txt | grep - ...
- Linux/Unix 怎样找出并删除某一时间点的文件(转)
在Linux/Unix系统中,我们的应用每天会产生日志文件,每天也会备份应用程序和数据库,日志文件和备份文件长时间积累会占用大量的存储空间,而有些日志和备份文件是不需要长时间保留的,一般保留7天内的文 ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
- 另类爬虫:从PDF文件中爬取表格数据
简介 本文将展示一个稍微不一样点的爬虫. 以往我们的爬虫都是从网络上爬取数据,因为网页一般用HTML,CSS,JavaScript代码写成,因此,有大量成熟的技术来爬取网页中的各种数据.这次, ...
- 海量数据中找出前k大数(topk问题)
海量数据中找出前k大数(topk问题) 前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小 ...
随机推荐
- 分支定界方法(branch and cut,branch and price的基础)
分支定界方法(branch and cut,branch and price的基础) 目录 1.基础版的分支定界算法(假设是min问题) 2.分支定界算法的步骤及其注意事项 2.1 具体的分支定界方法 ...
- JS Parser Combinator (解析器组合子)
前言 前些天偶然看到以前写的一份代码,注意有一段尘封的代码,被我遗忘了.这段代码是一个简单的解析器,当时是为了解析日志而做的.最初解析日志时,我只是简单的正则加上分割,写着写着,我想,能不能用一个简单 ...
- Java常见面试真题之中级进阶
前言 本来想着给自己放松一下,刷刷博客,突然被几道面试题难倒!java反射的作用于原理?说说List,Set,Map三者的区别?Object 有哪些常用方法?大致说一下每个方法的含义?Java 创建对 ...
- 【python】利用tqdm实现git下载时的进度条效果
注意1:这里是在python3环境下使用的git,安装要使用 pip install Gitpython 来安装在python环境下的git 注意2:这个方法可适用于 windows 环境和 Linu ...
- Modbus调试、Modbus Slave、ModScan、Modbus Ploll、串口调试
记录一下昨天调试Modbus调试. 上位机往下位机发送modbus指令.发送过去之后没有反应.后来才调试出来原来是下位机错一个位. 调试过程:用modScan 往modbus slave 发送modb ...
- 鸿蒙Navigation拦截器实现页面跳转登录鉴权方案
我们在进行页面跳转时,很多情况下都得考虑登录状态问题,比如进入个人信息页面,下单交易页面等等.在这些场景下,通常在页面跳转前,会先判断下用户是否已经登录,若已登录,则跳转到相应的目标页面,若没有登录, ...
- 干货分享:Air780E开发板如何使用?
一.概述 CORE-AIR780E 开发板是合宙通信推出的基于 Air780E 模组所开发的,包含电源,SIM 卡,USB,天线,音频等必要功能的最小硬件系统.以方便用户在设计前期对 Air780 ...
- 2022 GDOI普及组游记
2022 GDOI普及组游记 注:传送门均为校内网址 day -4 被年级主任集中开会,给我们免了亿堆作业,灌了亿壶鸡汤,宣布了为期一(亿)周的集训开始. day -3 中午一直在复习期中(4.21- ...
- 【一步步开发AI运动小程序】十五、AI运动识别中,如何判断人体站位的远近?
[云智AI运动识别小程序插件],可以为您的小程序,赋于人体检测识别.运动检测识别.姿态识别检测AI能力.本地原生识别引擎,无需依赖任何后台或第三方服务,有着识别速度快.体验佳.扩展性强.集成快.成本低 ...
- apache tomcat 6集群负载和session复制
无意间看到tomcat 6集群的内容,就尝试配置了一下,还是遇到很多问题,特此记录.apache服务器和tomcat的连接方法其实有三种:JK.http_proxy和ajp_proxy.本文主要介绍最 ...