Kubernetes-20:日志聚合分析系统—Loki的搭建与使用
日志聚合分析系统——Loki
什么是Loki?
Loki 是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签,专门为 Prometheus 和 Kubernetes 用户做了相关优化。
与传统日志收集系统(例ELK)相比,Loki的优势有哪些?
- 不对日志进行全文索引。通过存储压缩非结构化日志和仅索引元数据,Loki操作起来会更简单,更省成本
- 通过与 Prometheus 相同的标签记录流对日志进行索引和分组,这使得日志的扩展和操作效率更高
- 特别适合存储 Kubernetes Pod 日志;诸如 Pod 标签之类的元数据会被自动删除和编入索引
- 受 Grafana 原生支持,与 Prometheus 配合更加方便
解决痛点?
无需再去其他界面,或者终端上查看单个Pod的日志
整体架构
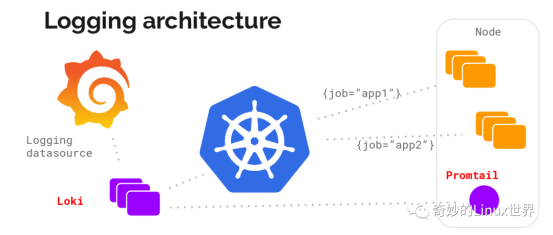
Loki的架构并不难,主要是以下三部分组成:
- Loki 为主服务器。负责存储日志和处理查询
- Promtail 是代理。负责收集日志并将其发送给Loki
- Grafana 用来UI展示。
Loki 使用与 Prometheus 相同的服务发现和标签重新标记库,编写了 Promtail。在 Kubernetes 中 Promtail 以 DaemonSet 方式运行在每个节点中,通过 Kubernetes API 得到日志的正确元数据,并将它们发送到Loki,如下图:
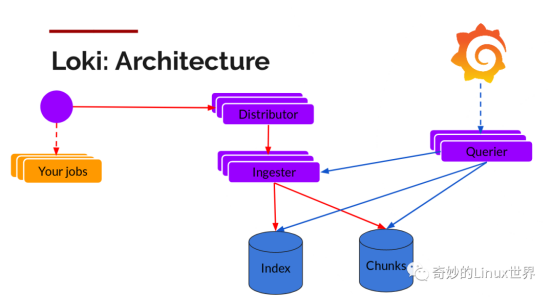
可以看到,Loki中主要的组件有Distributor、Ingester和Querier三个。
负责写入的组件有Distributor和Ingester两个:

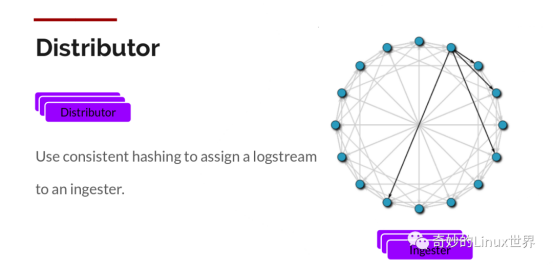
Distributor
Promtaif 一旦将日志发送给Loki,Distributor 就是第一个接收日志的组件。由于日志的写入量可能很大,所以不能在它们传入时并行写入数据库,要先进行批处理和压缩数据。
- Distributor 接收到 HTTP 请求,用于存储流数据
- 通过 hash 环对数据流进行 hash
- 通过hash算法计算出应该发送到哪个Ingester后,发送数据流
- Ingester新建Chunks或将数据追加到已有的Chunk上
Ingester
Ingester 接收到日志并开始构建 Chunk:
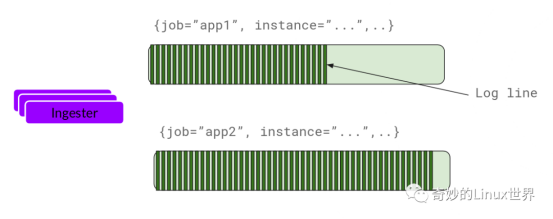
Ingester 是一个有状态组件,负责构建和刷新Chunk,当Chunk达到一定数量或者时间后,刷新到存储中去,每一个流日志对应一个Ingester。index和Chunk各自使用单独的数据库,因为他们存储额数据类型不同。
负责读的组件则是Querier:
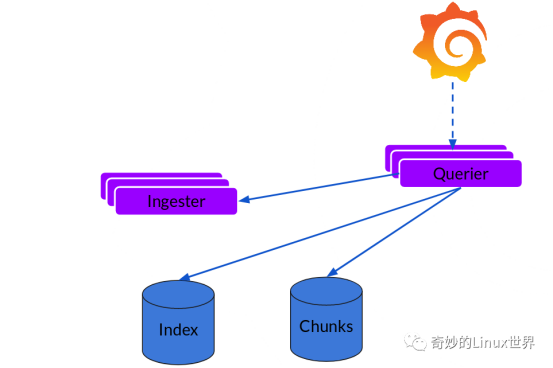
读取就比较简单,由 Querier 负责给定一个时间范围和标签选择器,也就是收到读请求:
- Querier 收到HTTP读请求
- Querier 将请求发送至Ingester读取还未写入Chunks的内存数据
- 随后再去index+chunks中查找数据
- Querier 遍历所有数据并进行去重处理,再返回最终结果
搭建使用
上边主要介绍的Loki的工作流程及组件,下面我们实际搭建操作下:
Loki项目地址:https://github.com/grafana/loki/
一、通过Helm部署:
## 添加chart
helm repo add loki https://grafana.github.io/loki/charts ## 更新chart
helm repo update ## 将loki template下载到本地
helm fetch loki/loki-stack ## 解压并自定义修改参数
tar zxvf loki-stack-2.0.2.tgz
cd loki-stack/ $$ ls
charts Chart.yaml README.md requirements.lock requirements.yaml templates values.yaml cd charts/ $$ ls
filebeat fluent-bit grafana logstash loki prometheus promtail
开始helm安装前要注意几个点:
1、可以修改values.yaml文件,指定是否开启Grafana、Prometheus等服务,默认不开启的:
loki:
enabled: true promtail:
enabled: true fluent-bit:
enabled: false grafana:
enabled: true
sidecar:
datasources:
enabled: true
image:
tag: 6.7.0 prometheus:
enabled: false
在此只开启Grafana
修改Grafana的values.yaml,使其Service暴露方式为NodePort(默认为ClusterIp):
vim charts/grafana/values.yaml
service:
type: NodePort
port: 80
nodePort: 30002 # 端口范围:30000-32767
targetPort: 3000
# targetPort: 4181 To be used with a proxy extraContainer
annotations: {}
labels: {}
portName: service
还有一处账号密码可以自定义修改下:
# Administrator credentials when not using an existing secret (see below)
adminUser: admin
adminPassword: admin
2、promtail服务在构建时会自动挂载:
- 宿主机docker主目录下的containers目录,一般默认都为/var/lib/docker/containers
- pod的日志目录,一般默认为/var/log/pods
这就需要特别注意一下,如果是修改过docker默认的存储路径的,需要将mount的路径进行修改,promtail找不到对应的容器日志
具体docker 存储路径,可以使用docker info 命令查询
vim charts/promtail/values.yaml
volumes:
- name: docker
hostPath:
path: /data/lib/docker/containers ## 我的是放在了data下
- name: pods
hostPath:
path: /var/log/pods volumeMounts:
- name: docker
mountPath: /data/lib/docker/containers ## 挂载点也要进行修改
readOnly: true
- name: pods
mountPath: /var/log/pods
readOnly: true
开始安装:
helm install -n loki --namespace loki -f values.yaml ../loki-stack
2020/11/11 17:18:54 Warning: Merging destination map for chart 'logstash'. The destination item 'filters' is a table and ignoring the source 'filters' as it has a non-table value of: <nil>
NAME: loki
LAST DEPLOYED: Wed Nov 11 17:18:53 2020
NAMESPACE: loki
STATUS: DEPLOYED RESOURCES:
==> v1/ClusterRole
NAME AGE
loki-promtail-clusterrole 1s
loki-grafana-clusterrole 1s ==> v1/ClusterRoleBinding
NAME AGE
loki-promtail-clusterrolebinding 1s
loki-grafana-clusterrolebinding 1s ==> v1/ConfigMap
NAME DATA AGE
loki-grafana 1 1s
loki-grafana-test 1 1s
loki-loki-stack 1 1s
loki-loki-stack-test 1 1s
loki-promtail 1 1s ==> v1/DaemonSet
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
loki-promtail 2 2 0 2 0 <none> 1s ==> v1/Deployment
NAME READY UP-TO-DATE AVAILABLE AGE
loki-grafana 0/1 1 0 1s ==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
loki-0 0/1 ContainerCreating 0 2s
loki-grafana-56bf5d8d-8zcgp 0/1 Init:0/1 0 2s
loki-promtail-6r24r 0/1 ContainerCreating 0 2s
loki-promtail-fvnfc 0/1 ContainerCreating 0 2s ==> v1/Role
NAME AGE
loki-promtail 1s
loki-grafana-test 1s
loki 1s ==> v1/RoleBinding
NAME AGE
loki-promtail 1s
loki-grafana-test 1s
loki 1s ==> v1/Secret
NAME TYPE DATA AGE
loki Opaque 1 1s
loki-grafana Opaque 3 1s ==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loki ClusterIP 10.109.216.219 <none> 3100/TCP 1s
loki-grafana NodePort 10.100.203.138 <none> 80:30002/TCP 1s
loki-headless ClusterIP None <none> 3100/TCP 1s ==> v1/ServiceAccount
NAME SECRETS AGE
loki 1 1s
loki-grafana 1 1s
loki-grafana-test 1 1s
loki-promtail 1 1s ==> v1/StatefulSet
NAME READY AGE
loki 0/1 1s ==> v1beta1/PodSecurityPolicy
NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP READONLYROOTFS VOLUMES
loki false RunAsAny MustRunAsNonRoot MustRunAs MustRunAs true configMap,emptyDir,persistentVolumeClaim,secret,projected,downwardAPI
loki-grafana false RunAsAny RunAsAny RunAsAny RunAsAny false configMap,emptyDir,projected,secret,downwardAPI,persistentVolumeClaim
loki-grafana-test false RunAsAny RunAsAny RunAsAny RunAsAny false configMap,downwardAPI,emptyDir,projected,secret
loki-promtail false RunAsAny RunAsAny RunAsAny RunAsAny true secret,configMap,hostPath,projected,downwardAPI,emptyDir ==> v1beta1/Role
NAME AGE
loki-grafana 1s ==> v1beta1/RoleBinding
NAME AGE
loki-grafana 1s
创建完成后,通过暴露的svc访问Grafana:
[root@Centos8 loki-stack]# kubectl get svc -n loki
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
loki ClusterIP 10.109.216.219 <none> 3100/TCP 113s
loki-grafana NodePort 10.100.203.138 <none> 80:30002/TCP 113s
loki-headless ClusterIP None <none> 3100/TCP 113s
二、开始使用Loki
通过服务器ip+30002访问,登录成功后,有一点需要注意的地方,也是非常容易踩坑的地方!!!
如果是安装Loki时采用的以上方法,开启了Grafana,那系统会自动配置好Data sources,应该不会有什么问题。
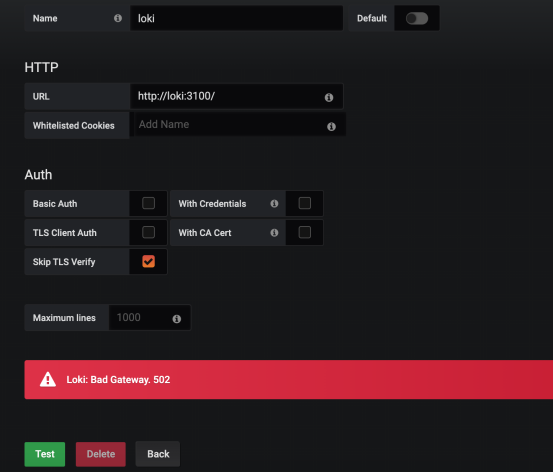
但是,如果是手动搭建的Grafana,需要手动添加Data Sources时,一定注意:
数据源名称中的Loki,L一定要是大写!!!
如果不是大写,会导致连接不到Loki源,一般回报错:Error connecting to datasource: Loki: Bad Gateway. 502
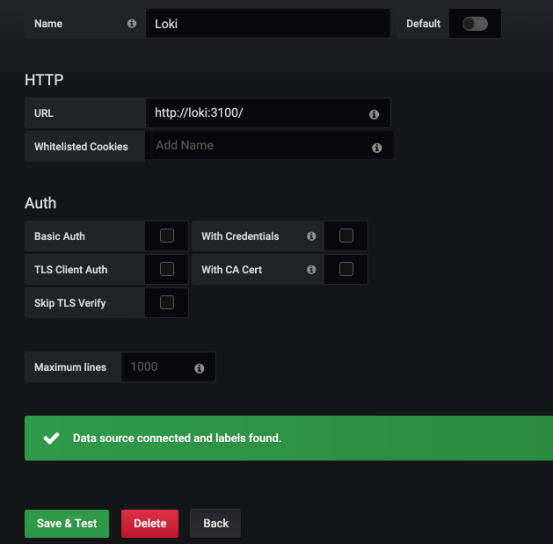
如果是Loki,L大写,结局完全不一样
数据源添加完毕后,开始查看日志
点击Explore,可以看到选择labels的地方
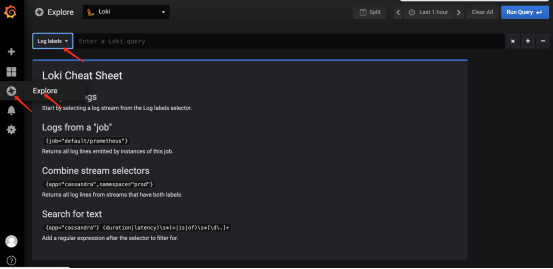
以下是labels的展现形式

选择一个app:grafana的标签查看一下
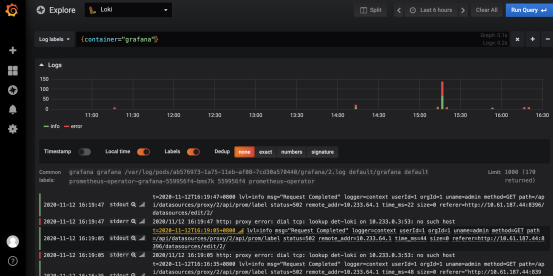
默认Loki会将stdout(正常输出)类型和stderr(错误输出)类型全部展示出来
如果只想查看stderr错误输出类型的日志,可以点击stderr旁边的放大镜来展示:
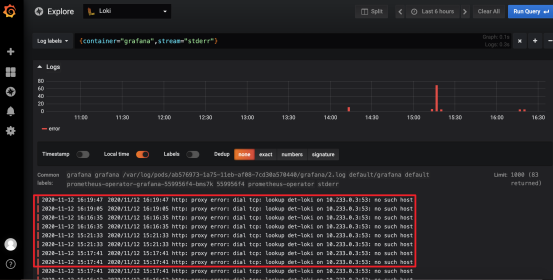
此时显示的全部为错误日志
除了这种办法,还可以直接通过上边的搜索栏,进行自定义的筛选,具体的语法问题,可以再自行查询学习。
还可以查看 Prometheus 的 metrics 信息:
Loki的搭建及简单的使用就到此结束了
Kubernetes-20:日志聚合分析系统—Loki的搭建与使用的更多相关文章
- 用ELK搭建简单的日志收集分析系统【转】
缘起 在微服务开发过程中,一般都会利用多台服务器做分布式部署,如何能够把分散在各个服务器中的日志归集起来做分析处理,是一个微服务服务需要考虑的一个因素. 搭建一个日志系统 搭建一个日志系统需要考虑一下 ...
- 2018年ElasticSearch6.2.2教程ELK搭建日志采集分析系统(教程详情)
章节一 2018年 ELK课程计划和效果演示1.课程安排和效果演示 简介:课程介绍和主要知识点说明,ES搜索接口演示,部署的ELK项目演示 es: localhost:9200 k ...
- logstash+elasticsearch+kibana搭建日志收集分析系统
来源: http://blog.csdn.net/xifeijian/article/details/50829617 日志监控和分析在保障业务稳定运行时,起到了很重要的作用,不过一般情况下日志都分散 ...
- Hadoop日志文件分析系统
Hadoop日志分析系统 项目需求: 需要统计一下线上日志中某些信息每天出现的频率,举个简单的例子,统计线上每天的请求总数和异常请求数.线上大概几十台 服务器,每台服务器大概每天产生4到5G左右的日志 ...
- 2018年ElasticSearch6.2.2教程ELK搭建日志采集分析系统(目录)
章节一 2018年 ELK课程计划和效果演示 1.课程安排和效果演示 简介:课程介绍和主要知识点说明,ES搜索接口演示,部署的ELK项目演示 章节二 elasticSearch 6.2版本基础讲解到 ...
- zipkin+elk微服务日志收集分析系统
docker安装elk日志分析系统 在win10上安装docker环境 tip:win7/8 win7.win8 系统 win7.win8 等需要利用 docker toolbox 来安装,国内可以使 ...
- 日志聚合工具之 Loki
本文使用的 Loki 和 Promtail 版本为 1.6.1,Grafana 版本为 7.2.0:部署在 Linux 服务器 Loki 负责日志的存储和查询:Promtail 负责日志的采集并推送给 ...
- 通过hadoop + hive搭建离线式的分析系统之快速搭建一览
最近有个需求,需要整合所有店铺的数据做一个离线式分析系统,曾经都是按照店铺分库分表来给各自商家通过highchart多维度展示自家的店铺经营 数据,我们知道这是一个以店铺为维度的切分数据,非常适合目前 ...
- ELK+kafka日志收集分析系统
环境: 服务器IP 软件 版本 192.168.0.156 zookeeper+kafka zk:3.4.14 kafka:2.11-2.2.0 192.168.0.42 zookeeper+kaf ...
随机推荐
- 【总结】HTTP
一.HTTP 1.http HTTP 是一种 超文本传输协议(Hypertext Transfer Protocol),HTTP 是一个在计算机世界里专门在两点之间传输文字.图片.音频.视频等超文本数 ...
- git 出现 error: bad signature fatal: index file corrupt
一次大改版,提交了很多代码,但再次提交提交不了,也拉不下来仓库的代码 提示error bad signature fatal: index file corrupt 在项目有.git这同级打开Git ...
- 5G应用的实时决策
背景概述 尽管近几年很多供应商在不断重申着他们对VoltDB持续输出的专业认可,VoltDB也随着技术发展在不断增加一些流行技术词汇,但是真正让大家了解某个技术产品持续演进的特性,单单依靠增加几个技术 ...
- 如何构建高性能服务器(以Nginx为例)
方法论 软件层面 增大CPU利用率 使用全部CPU, worker进程数等于CPU 进程间不做无用的切换 繁忙时不主动让出CPU worker进程之间不争抢CPU CPU切换需要5us,如果大量进程需 ...
- 英特尔与 Facebook 合作采用第三代英特尔® 至强® 可扩展处理器和支持 BFloat16 加速的英特尔® 深度学习加速技术,提高 PyTorch 性能
英特尔与 Facebook 曾联手合作,在多卡训练工作负载中验证了 BFloat16 (BF16) 的优势:在不修改训练超参数的情况下,BFloat16 与单精度 32 位浮点数 (FP32) 得到了 ...
- 针对DEV XtraReport中没有radiobuttonlist的替代方法
private void PrintingSystem_EditingFieldChanged(object sender, DevExpress.XtraPrinting.EditingField ...
- laravel 控制器中获取不到session
protected $middleware = [ \Illuminate\Session\Middleware\StartSession::class, ]; 在 kernel.php中 加入Sta ...
- 设置Eclipse 字体 - MD终于摸到了
以前总是没办法设置Eclipse的 左边 资源管理器 字体.思想老局限在Eclipse的Font Setting里,跳不出这个玄妙的莫比乌斯环似的圈圈儿......每次戴着眼镜设置完字体,然后坐在电脑 ...
- TCP中RTT的测量和RTO的计算
https://blog.csdn.net/zhangskd/article/details/7196707 tcp传输往返时间是指:发送方发送tcp断开时, 到发送方接收到改段立即响应的所耗费的时间 ...
- Kubernetes笔记(六):了解控制器 —— Deployment
Pod(容器组)是 Kubernetes 中最小的调度单元,可以通过 yaml 定义文件直接创建一个 Pod.但 Pod 本身并不具备自我恢复(self-healing)功能.如果一个 Pod 所在的 ...