LRU Cache & Bloom Filter

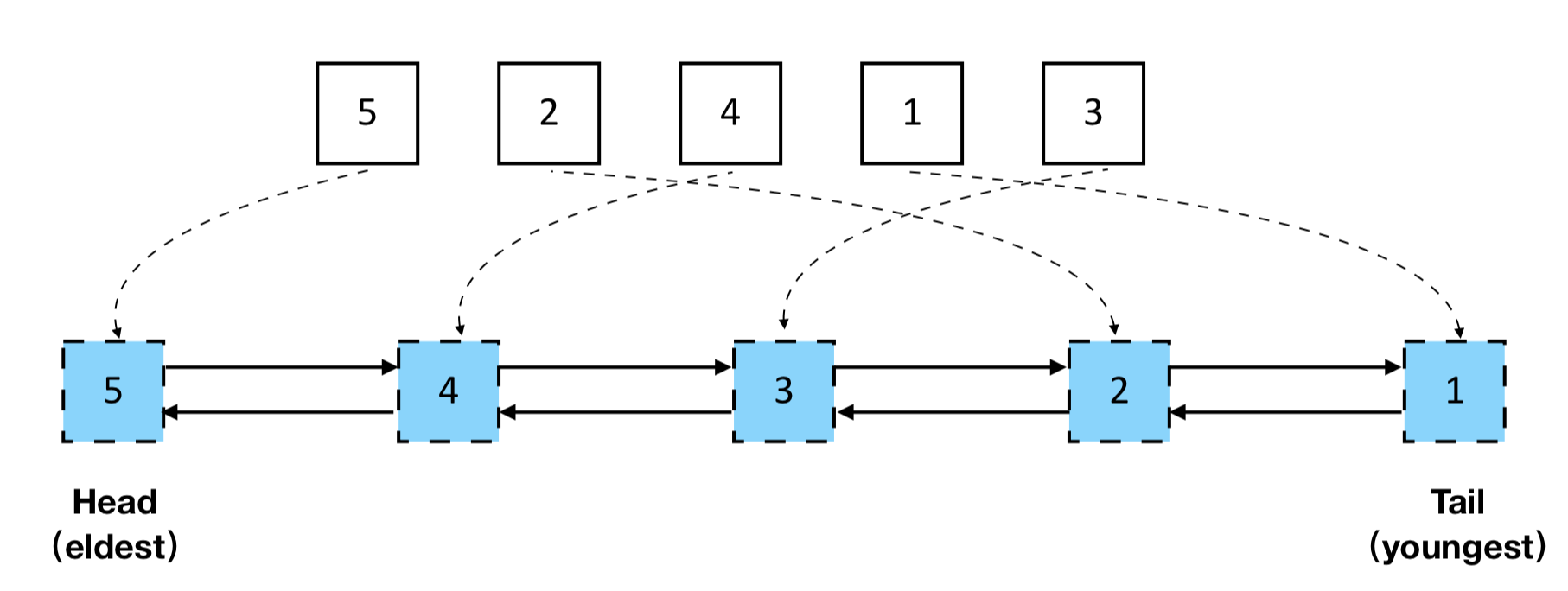
LFU Cache
也记录元素出现的频次,即使最近刚出现的,也未必就会挪到最前面。
缓存内始终按频次排序,如果超了缓存空间限制,还是新进的元素把原先频次最低的顶走。
1. LFU - least frequently used(最近最不常用⻚⾯置换算法,频次越高的放越前面)
2. LRU - least recently usd(最近最少使⽤页⾯置换算法)
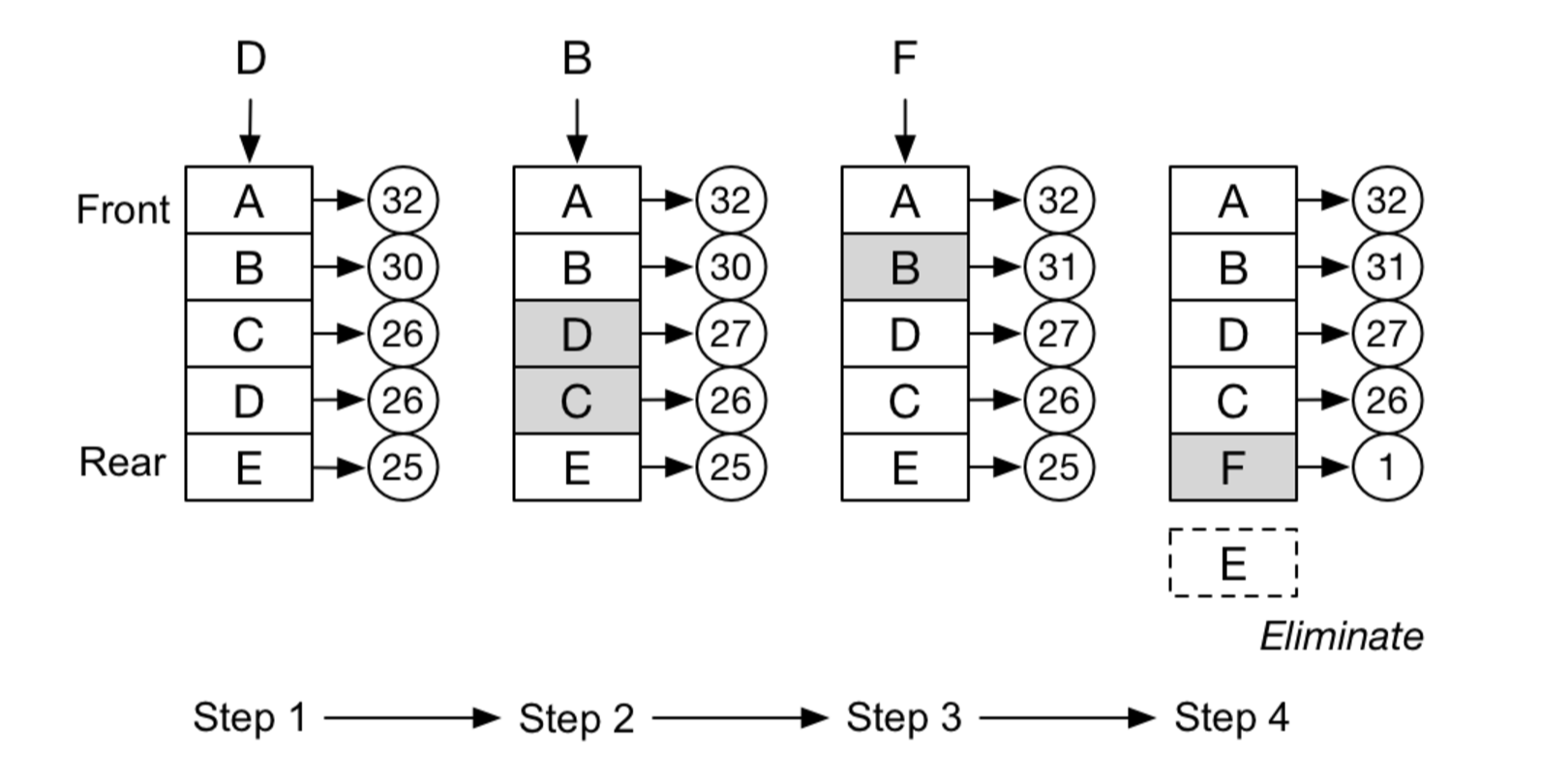
Leetcode 146. LRU缓存机制 https://leetcode-cn.com/problems/lru-cache/
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
解:
考虑用 ordered dict 实现
1 import collections
2 class LRUCache:
3 def __init__(self, capacity: int):
4 self.dic = collections.OrderedDict()
5 self.remain = capacity
6
7 def get(self, key: int) -> int:
8 if key not in self.dic:
9 return -1
10 v = self.dic.pop(key)
11 self.dic[key] = v # 如果在key在dict中,就pop出来后再set成最新的key
12 return v
13
14 def put(self, key: int, value: int) -> None:
15 if key in self.dic:
16 self.dic.pop(key)
17 else:
18 if self.remain > 0:
19 self.remain -= 1
20 else: # 如果已经满了,就删除第一个key-value对(即最早put的键值对。令last=False即可)
21 self.dic.popitem(last=False)
22
23 self.dic[key] = value # put进去作为最新的键值对
24
25
26 # Your LRUCache object will be instantiated and called as such:
27 # obj = LRUCache(capacity)
28 # param_1 = obj.get(key)
29 # obj.put(key,value)
布隆过滤器 Bloom Filter
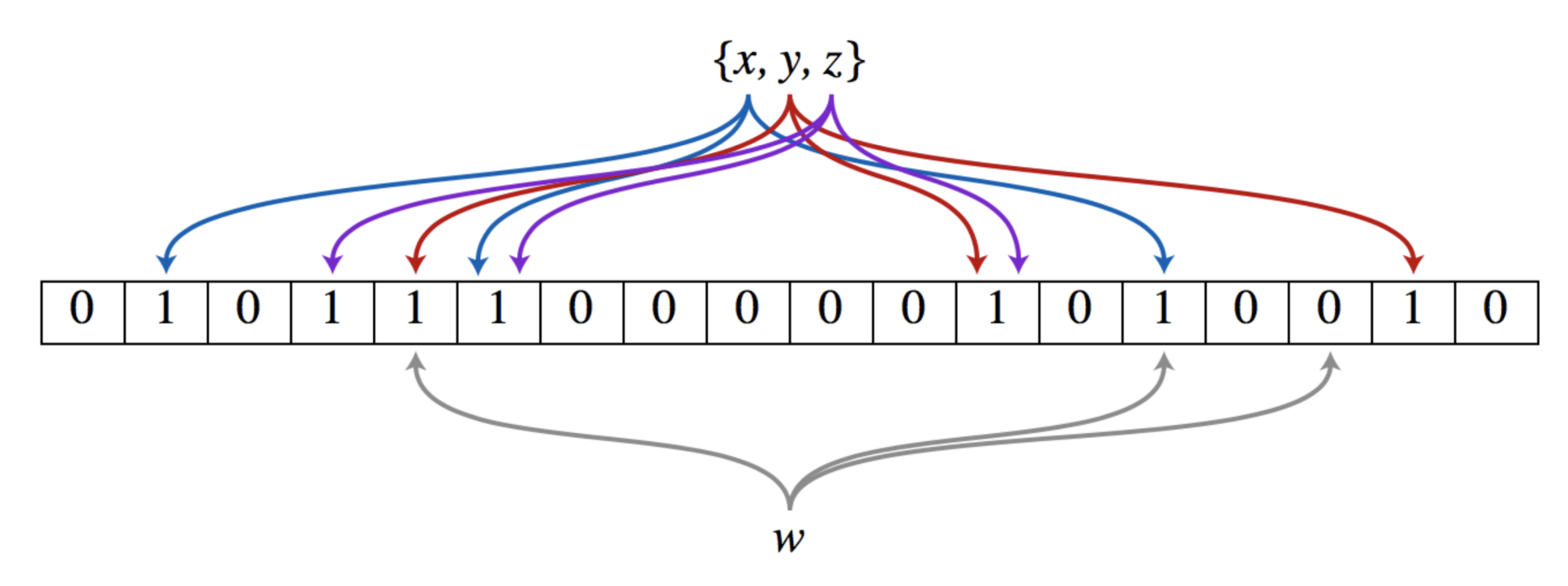
过滤器的作用:判断元素在还是不在。(如图查询 w 在不在集合中)
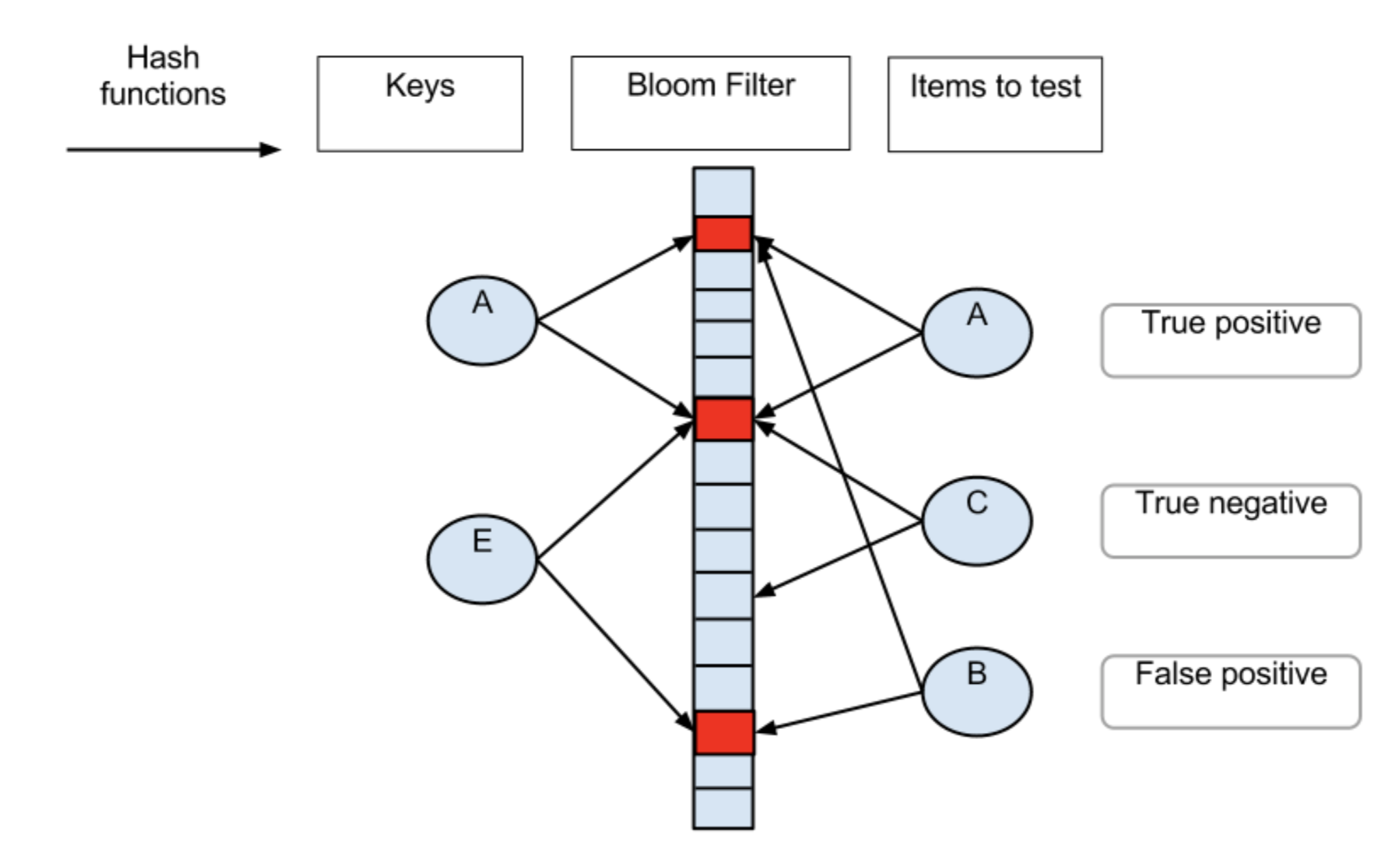
案例
1. ⽐特币网络
2. 分布式系统(Map-Reduce)
LRU Cache & Bloom Filter的更多相关文章
- 布隆过滤器(Bloom Filter)详解——基于多hash的概率查找思想
转自:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- Bloom Filter 原理与应用
介绍 Bloom Filter是一种简单的节省空间的随机化的数据结构,支持用户查询的集合.一般我们使用STL的std::set, stdext::hash_set,std::set是用红黑树实现的,s ...
- 海量数据处理算法—Bloom Filter
海量数据处理算法—Bloom Filter 1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出.它可以用于检索一个元素是否在一个集合中. Bl ...
- [转载] 布隆过滤器(Bloom Filter)详解
转载自http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 布隆过滤器(Bloom Filter)详解
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中.和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一 ...
- Java Bloom filter几种实现比较
英文原始出处: Bloom filter for Scala, the fastest for JVM 本文介绍的是用Scala实现的Bloom filter. 源代码在github上.依照性能测试结 ...
- 大数据处理算法--Bloom Filter布隆过滤
1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出.它可以用于检索一个元素是否在一个集合中. Bloom Filter(BF)是一种空间效率很 ...
- 【转】海量数据处理算法-Bloom Filter
1. Bloom-Filter算法简介 Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合.它是一个判断元素是否存在于 ...
- 浅谈布隆过滤器Bloom Filter
先从一道面试题开始: 给A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL. 这个问题的本质在于判断一个元素是否在一个集合中.哈希表以O(1) ...
随机推荐
- Combine 框架,从0到1 —— 3.使用 Subscriber 控制发布速度
本文首发于 Ficow Shen's Blog,原文地址: Combine 框架,从0到1 -- 3.使用 Subscriber 控制发布速度. 内容概览 前言 在发布者生产元素时消耗它们 使 ...
- Qt QString转char[]数组
Qt QString转char[]数组 QString s1="1234456";char str[20]={0};strcpy(str,s1.toStdString().c_st ...
- [BUUOJ记录] [BJDCTF2020]EasySearch
前面的突破点考察swp泄露以及md5截断认证,最后一步考察ssi注入 进入题目是一个登陆页面什么提示都没有,工具扫了一下发现swp泄露,得到登录验证页面的源码: <?php ob_start() ...
- Java8 Strean api
Stream 遍历数据集的高级迭代器.使用StreamApi让代码: 声明式:更简洁,更易读: 可复合:更灵活: 可并行:性能更好: 使用流 流的使用一般包括三件事: 一个数据源(如集合)来执行一个查 ...
- JVM学习第三天(JVM的执行子系统)之类加载机制
好几天没有学习了,前几天因为导出的事情,一直在忙,今天继续学习, 其实今天我也遇到了一个问题,如果有会的兄弟可以评论留给我谢谢; 问题:fastJSON中JSONObject.parseObject做 ...
- javascript面试题(一)
1. var bar = null; console.log(typeof bar === 'object'); //logs true! 尽管 typeof bar === "object ...
- leetcode刷题-51N皇后
题目 n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击. 给定一个整数 n,返回所有不同的 n 皇后问题的解决方案. 每一种解法包含一个明确的 n 皇后问 ...
- Django 仿ajax传递数据(Django十)
之前用form表单传递数据,没有遇到任何问题 具体见:https://blog.csdn.net/qq_38175040/article/details/104867747 然后现在我想用ajax传递 ...
- oracle数据处理之sql*loader(二)
目录 SQL*Loader对不同文件及格式的处理方法 2.1 Excel文件 一般的Excel文件最大行数不超过65536行,说明数据处理量并不大,处理Excel的方式是将其另存为CSV格式文件,然后 ...
- Git | Git入门,成为项目管理大师(一)
大家好,周一我们迎来了一个新的专题--git. 写这个专题的初衷有两点,第一点是觉得好像很少有公众号提到git相关的技术,可能是觉得太基础了看不上.但实际上git非常重要,在我们实际的开发工作当中使用 ...