LRU Cache & Bloom Filter

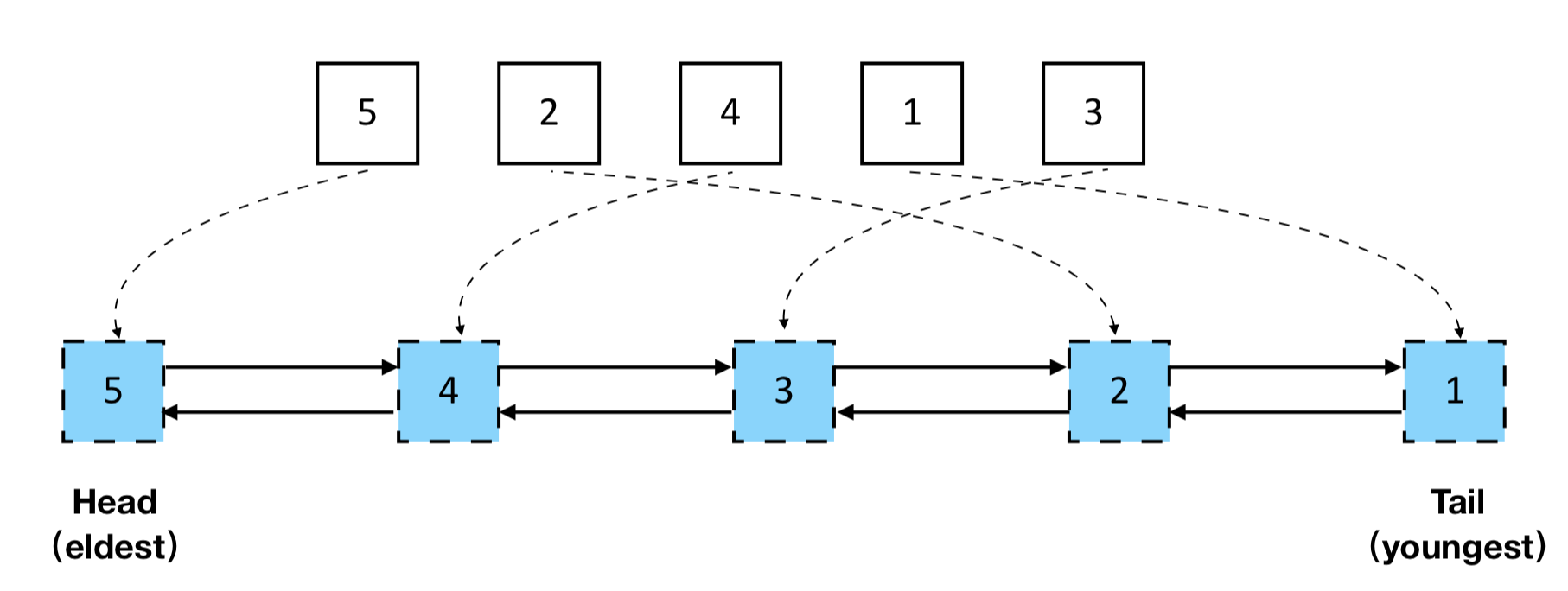
LFU Cache
也记录元素出现的频次,即使最近刚出现的,也未必就会挪到最前面。
缓存内始终按频次排序,如果超了缓存空间限制,还是新进的元素把原先频次最低的顶走。
1. LFU - least frequently used(最近最不常用⻚⾯置换算法,频次越高的放越前面)
2. LRU - least recently usd(最近最少使⽤页⾯置换算法)
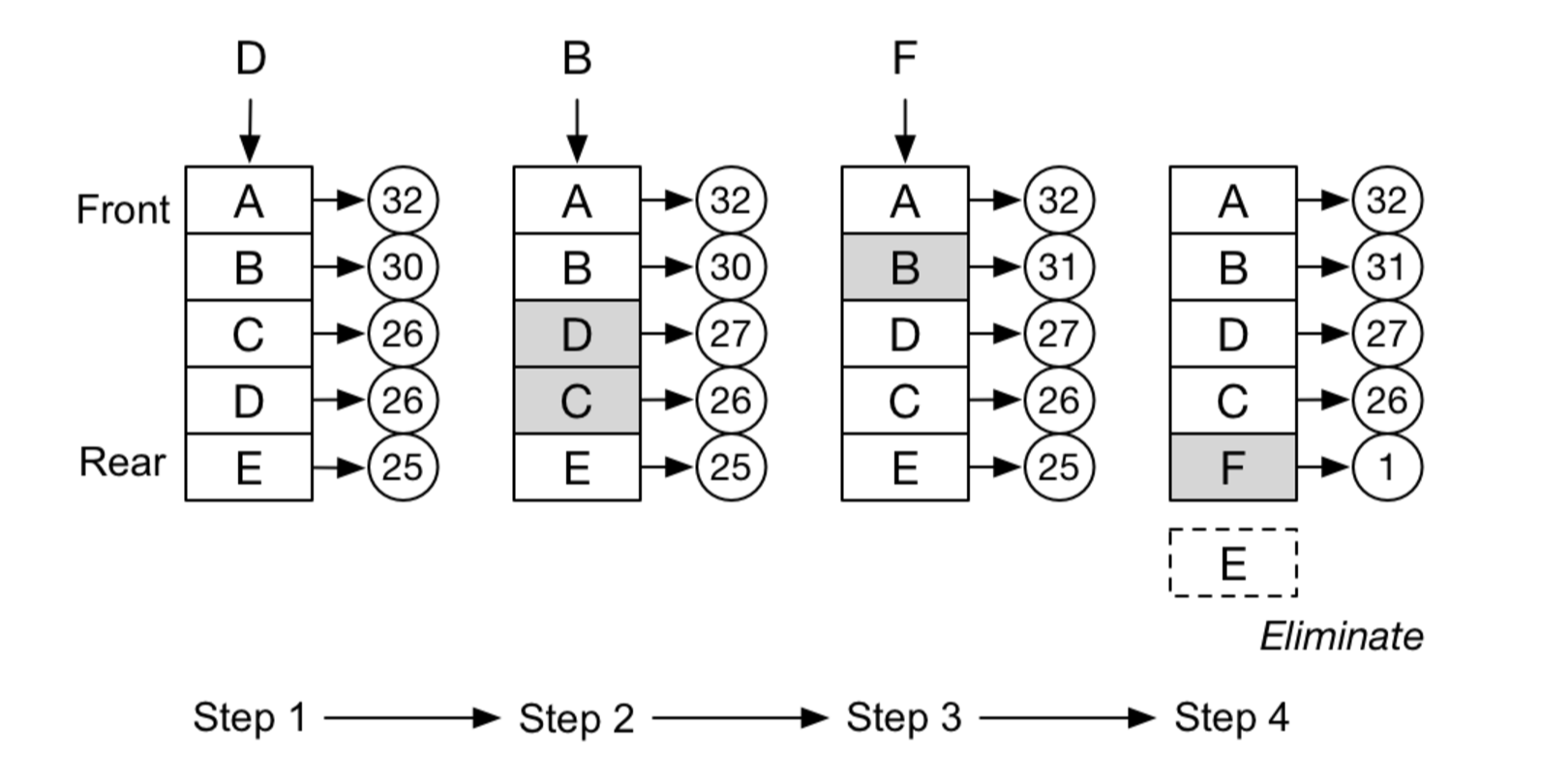
Leetcode 146. LRU缓存机制 https://leetcode-cn.com/problems/lru-cache/
运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。
进阶:
你是否可以在 O(1) 时间复杂度内完成这两种操作?
解:
考虑用 ordered dict 实现
1 import collections
2 class LRUCache:
3 def __init__(self, capacity: int):
4 self.dic = collections.OrderedDict()
5 self.remain = capacity
6
7 def get(self, key: int) -> int:
8 if key not in self.dic:
9 return -1
10 v = self.dic.pop(key)
11 self.dic[key] = v # 如果在key在dict中,就pop出来后再set成最新的key
12 return v
13
14 def put(self, key: int, value: int) -> None:
15 if key in self.dic:
16 self.dic.pop(key)
17 else:
18 if self.remain > 0:
19 self.remain -= 1
20 else: # 如果已经满了,就删除第一个key-value对(即最早put的键值对。令last=False即可)
21 self.dic.popitem(last=False)
22
23 self.dic[key] = value # put进去作为最新的键值对
24
25
26 # Your LRUCache object will be instantiated and called as such:
27 # obj = LRUCache(capacity)
28 # param_1 = obj.get(key)
29 # obj.put(key,value)
布隆过滤器 Bloom Filter
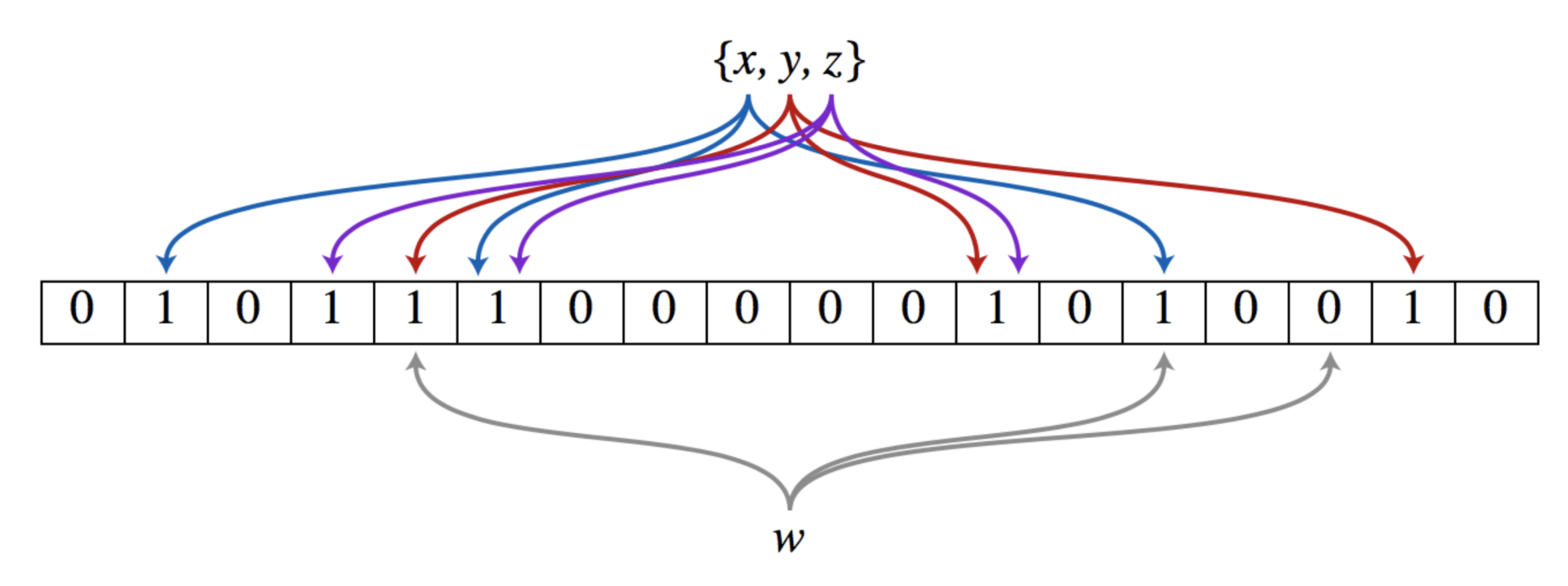
过滤器的作用:判断元素在还是不在。(如图查询 w 在不在集合中)
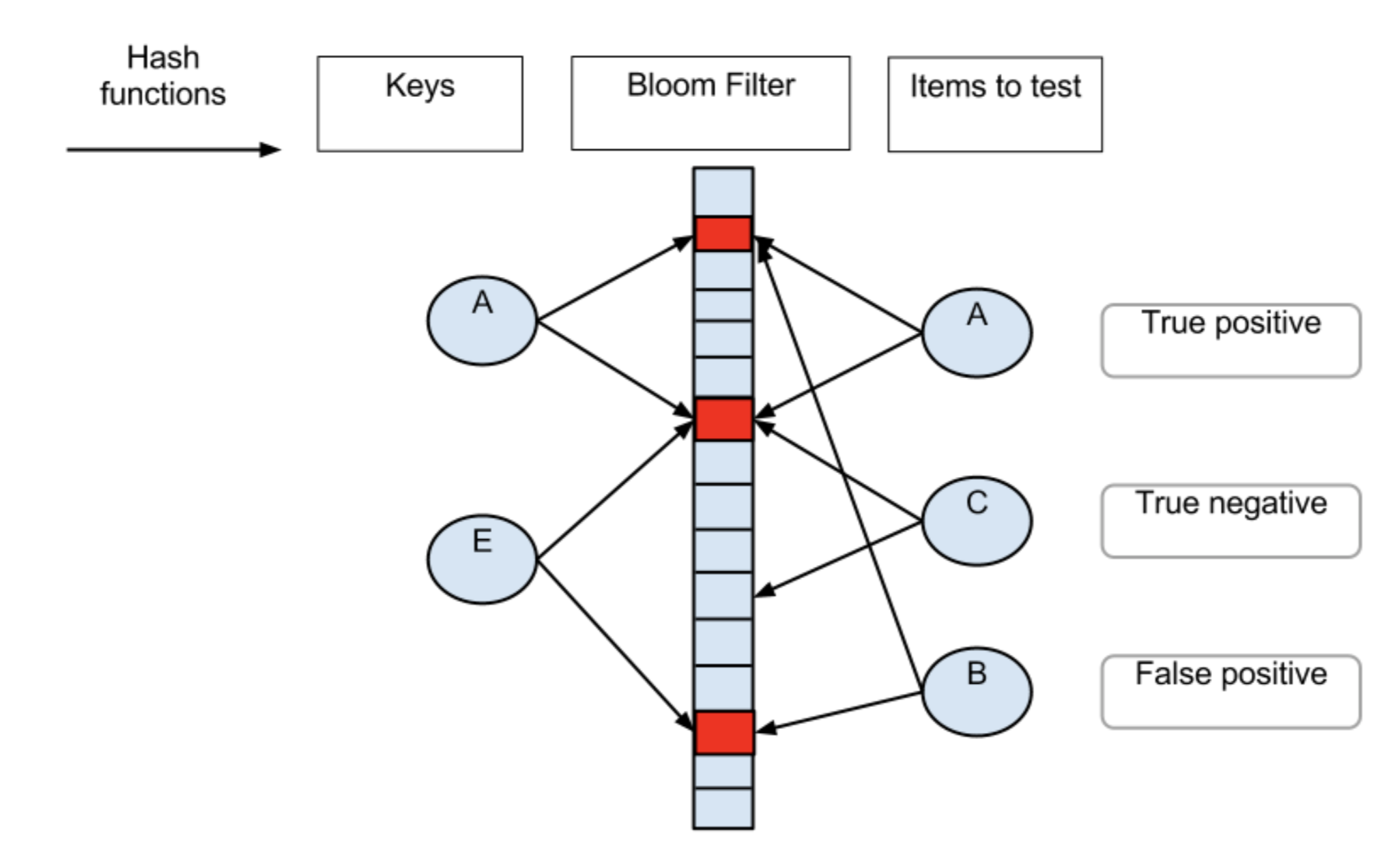
案例
1. ⽐特币网络
2. 分布式系统(Map-Reduce)
LRU Cache & Bloom Filter的更多相关文章
- 布隆过滤器(Bloom Filter)详解——基于多hash的概率查找思想
转自:http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- Bloom Filter 原理与应用
介绍 Bloom Filter是一种简单的节省空间的随机化的数据结构,支持用户查询的集合.一般我们使用STL的std::set, stdext::hash_set,std::set是用红黑树实现的,s ...
- 海量数据处理算法—Bloom Filter
海量数据处理算法—Bloom Filter 1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出.它可以用于检索一个元素是否在一个集合中. Bl ...
- [转载] 布隆过滤器(Bloom Filter)详解
转载自http://www.cnblogs.com/haippy/archive/2012/07/13/2590351.html 布隆过滤器[1](Bloom Filter)是由布隆(Burton ...
- 布隆过滤器(Bloom Filter)详解
直观的说,bloom算法类似一个hash set,用来判断某个元素(key)是否在某个集合中.和一般的hash set不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一 ...
- Java Bloom filter几种实现比较
英文原始出处: Bloom filter for Scala, the fastest for JVM 本文介绍的是用Scala实现的Bloom filter. 源代码在github上.依照性能测试结 ...
- 大数据处理算法--Bloom Filter布隆过滤
1. Bloom-Filter算法简介 Bloom-Filter,即布隆过滤器,1970年由Bloom中提出.它可以用于检索一个元素是否在一个集合中. Bloom Filter(BF)是一种空间效率很 ...
- 【转】海量数据处理算法-Bloom Filter
1. Bloom-Filter算法简介 Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合.它是一个判断元素是否存在于 ...
- 浅谈布隆过滤器Bloom Filter
先从一道面试题开始: 给A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL. 这个问题的本质在于判断一个元素是否在一个集合中.哈希表以O(1) ...
随机推荐
- 每天定时下载gfs资料shell脚本
在数值天气预报应用中,经常需要下载一些输入资料,美国ncep的gfs资料是常用的一种分析场资料.业务运行,需要每天定时从ncep网站上下载,所以写了一个Shell脚本实现这一功能.脚本内容如下: #! ...
- Azure Storage 系列(一)入门简介
一,引言 今天作为新的Azure 资源介绍的开篇,我们来学习一个新的服务,Azure Storage.众所周知,我们实际在开发过程中,会需要存储一些比如说日志,图片,等等,各种类型的数据.比如说存储图 ...
- Laravel chunk和chunkById的坑
Laravel chunk和chunkById的坑 公司中的项目在逐渐的向Laravel框架进行迁移.在编写定时任务脚本的时候,用到了chunk和chunkById的API,记录一下踩到的坑. 一.前 ...
- 在Spring中拦截器的使用
Filter Filter是Servlet容器实现的,并不是由Spring 实现的 下面是一个例子 import java.io.IOException; import javax.servlet.F ...
- gson 处理null
1.定义null处理类 class StringConverter : JsonSerializer<String?>, JsonDeserializer<String?> { ...
- Animator.SetFloat(string name,float value,float dampTime,float deltaTime)详解
一般来说,我们用到的是这个API: animator.SetFloat("Speed",2.0f); 但是这个还有一个重载的方法,叫做: Animator.SetFloat(str ...
- 【python开发】迈出第一步,这可能是我唯一一次的Python开发了
好久没写博了,今天就瞎唠唠吧 背景: 组内有个测试平台,是基于Python2+tornado 框架写的,之前自己维护了一套系统的UIweb自动化代码,现在需要集成进去.这很可能是自己唯一一次基于pyt ...
- php反序列化总结与学习
基础知识: 1.php类与对象 2.魔术函数 3.序列化方法 类与对象 <?php class test{ public $var = "hello world"; publ ...
- console线和RJ45
123 前言 一直以为console口和RJ45是同一种接口,but后来我发现我错了~ RJ45 先介绍一下RJ45吧 什么是RJ45? RJ45是一种接口 我们家用的网线的接口 其实就是RJ45 r ...
- Cassandra Vnodes在Cassandra 2.0-4.0中的演进
Vnodes简短历史 Vnodes又叫Virtual Nodes.是Cassandra在1.2版本里引入的功能,已经在生产环境中使用了近8年了.从2.0版本开始,因为默认配置里num_tokens一般 ...