Redis高可用——副本机制
为实现Redis服务的高可用,Redis官方为我们提供了副本机制(或称主从复制)和哨兵机制。副本机制使得当Master服务器宕机后,我们可以将其中一台Slave切换为新的Master服务器。哨兵机制则实现了自动发现Master服务器宕机,并自动进行主从切换。本文主要介绍副本机制(Replication),包括副本机制的概念、用法及其底层实现。下一篇文章我们再介绍哨兵机制。
从技术实现角度来看,Redis通过主从复制的方式来实现副本机制,所以下面介绍技术实现时,我们采用“主从复制”这个词。
概念
高可用的作用是为了解决服务器宕机带来的服务不可用问题。对于Redis缓存服务器而言,解决方法就是在多台计算机上存储缓存数据,即:副本机制。当客户端往缓存服务器(通常称为Master服务器)写数据时,其他缓存服务器(通常称为Slave服务器)自动同步,如下图所示:
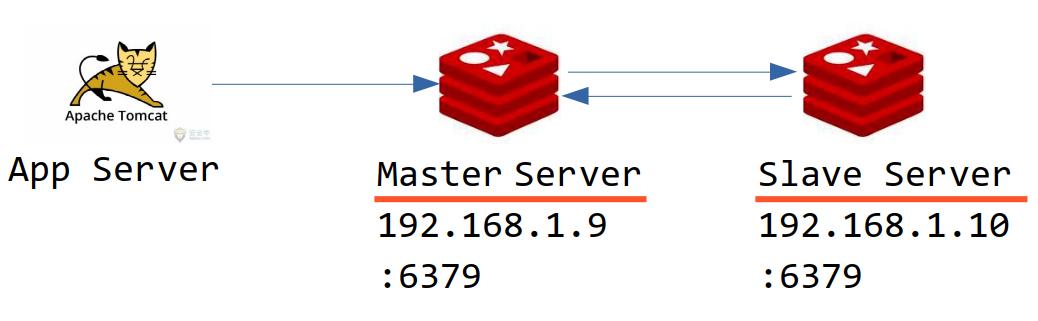
上图是最简单的主从集群结构,只有一个Master节点和一个Slave节点。复杂一点的话,我们也可以配置多个Slave节点。
配置
Redis的主从复制集群配置非常简单,Master节点只需要改两个地方的配置,Slave节点只需要改一个配置项即可。这里,我们以上图的最简单的主从结构为例,具体修改如下:
Master节点的配置文件改动
修改之前:
bind 127.0.0.1
protected-mode yes
修改之后:
# bind 127.0.0.1
protected-mode no
即:去掉保护模式,并且将绑定的IP地址注释掉。
- Slave节点的配置文件改动
添加一行:
# replicaof <masterip> <masterport>
replicaof 192.168.1.9 6379
即:此Slave服务器待同步的Master服务器的IP地址为192.168.1.9,端口号为6379(见上图)。接下来我们来学习一下,Redis底层是如何实现主从复制的。
同步方式
具体讲解代码实现之前,先来了解一下两种主从同步方式。
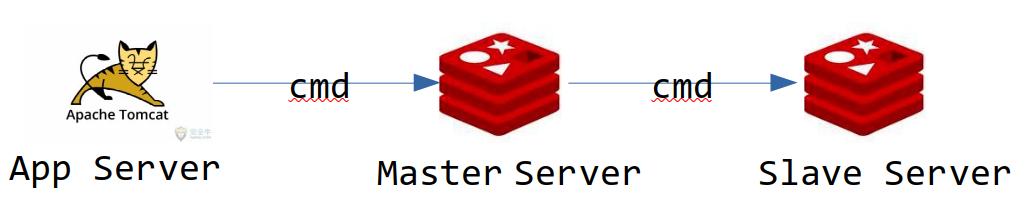
完全同步(Full Sync):所有缓存数据同步到
Slave机器。如下图所示,Master机器从rdb文件(Redis的持久化文件)中读取字节流发送到Slave机器,知道发完为止。Slave机器根据发送过来的数据执行命令。
部分同步(Partial Sync):客户端每发送一条Redis命令到Master,Master执行这条命令后,会转发到Slave机器。如下图所示,Slave接收到命令后,和Master一样,会执行一遍命令流程,从而达到同步命令。这种方式每次都是同步命令,所以称为部分同步,也可以理解为增量式的同步。
起点
上一篇文章我们介绍了事件机制,我们已经看到,系统启动时,会注册一个时间事件,其回调函数为serverCron,这个函数默认每秒执行10次。这个函数中会调用——replicationCron()函数——这就是主从复制的起点了:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
run_with_period(1000) replicationCron();
}
从这里开始,主从同步的会依次经历主从握手、完全同步以及部分同步三个阶段,下面我们分三个部分具体阐述。
主从握手
我们知道TCP传输数据前会执行三次握手来建立连接,Redis的主从服务器之间也会执行一段握手操作,目的是执行基本的验证逻辑,并配置必要的同步参数。这个握手过程涉及的数据传递如下图所示(代码具体实现参见replication.c的syncWithMaster()函数):

上图左侧所示为握手过程中Slave服务器状态变化,右侧为握手过程的消息传输。可以看到,主从复制的过程是由Slave发起的,涉及五个来回,十条消息,可分以下三个阶段:
PING-PONG阶段:这一阶段类似于打电话开头密码认证阶段:
Slave发送密码到master进行认证。如果没有配置master密码的话,则会跳过这一步。可能有人会问,认证阶段有什么意义?如果``master服务器配置了访问需要密码,而Slave服务器因为没有配置master`的密码而跳过认证阶段,则会导致后续命令会执行失败——返回没有验证错误,具体如下:int processCommand(client *c) {
if (server.requirepass && !c->authenticated && c->cmd->proc != authCommand)
{
flagTransaction(c);
addReply(c,shared.noautherr);
return C_OK;
}
}
参数配置阶段:最后三条以
replconf开头的命令,用于告诉master服务器主从同步相关的参数——IP地址、端口以及支持的服务。
经过以上握手步骤之后,Slave服务器进入主从复制阶段。Slave服务器首先尝试进行部分同步,即发送psync命令到Master服务器,如上图红线所示。如果Master服务器不支持或认为不满足部分同步的条件,则告诉Slave服务器需要执行完全同步。所以,接下来我们也是先阐述部分同步,再阐述完全同步。
部分同步
刚才已经说了,部分同步下,Master服务器在执行命令的同时,会将命令广播到Slave服务器,如下所示:
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
processInputBufferAndReplicate(c);
}
void processInputBufferAndReplicate(client *c) {
if (!(c->flags & CLIENT_MASTER)) {
processInputBuffer(c);
} else {
size_t prev_offset = c->reploff;
processInputBuffer(c);
size_t applied = c->reploff - prev_offset;
if (applied) {
replicationFeedSlavesFromMasterStream(server.slaves,
c->pending_querybuf, applied);
sdsrange(c->pending_querybuf,applied,-1);
}
}
}
void replicationFeedSlavesFromMasterStream(list *slaves, char *buf, size_t buflen) {
listNode *ln;
listIter li;
if (server.repl_backlog) feedReplicationBacklog(buf,buflen);
listRewind(slaves,&li);
while((ln = listNext(&li))) {
client *slave = ln->value;
/* Don't feed slaves that are still waiting for BGSAVE to start */
if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) continue;
addReplyString(slave,buf,buflen);
}
}
readQueryFromClient()这个函数我们应该很熟悉了,上一篇文章中我们知道,这就是和客户端建立连接后,在客户端socket上注册的回调函数。此函数会调用processInputBufferAndReplicate,进而调用replicationFeedSlavesFromMasterStream,这就是向Slave服务器推送命令字节流的函数了。通过代码可以看到,该函数会遍历所有的Slave服务器,并逐个向Slave服务器发送命令字节流。
那么,接下来的疑问便是server.slaves数组是怎么得到的?这就是上一节最后说到的psync命令要做的事了,psync命令的处理函数syncCommand有如下逻辑:
/* SYNC and PSYNC command implemenation. */
void syncCommand(client *c) {
if (!strcasecmp(c->argv[0]->ptr,"psync")) {
if (masterTryPartialResynchronization(c) == C_OK) {
server.stat_sync_partial_ok++;
return; /* No full resync needed, return. */
}
}
}
int masterTryPartialResynchronization(client *c) {
c->flags |= CLIENT_SLAVE;
c->replstate = SLAVE_STATE_ONLINE;
c->repl_ack_time = server.unixtime;
c->repl_put_online_on_ack = 0;
listAddNodeTail(server.slaves,c);
}
上述两个函数均是截取我们关心的部分,应该不用做过多解释了。
完全同步
执行完全同步判断条件
有了部分同步就能实现主从同步了吗?显然不能,部分同步之前,Master服务器上执行的命令需要同步到Slave服务器,这就是完全同步发挥作用的地方了。讲解完全同步的实现之前,我们来看看Redis是怎么判断是否需要完全同步的?下面是判断是否需要完全同步所需的三组状态数据:
replid和reploff:第一个参数replid是Master服务器的id,第二个参数reploff为当前Slave服务器复制的偏移量。Slave服务器发起部分同步时,一般会带上这两个参数,即:psync replid reploff。replid2和second_replid_offset: 这两个变量用于主从切换的情形。主从切换的时候,Slave服务器会变成Master服务器,这两个变量分别用于该Slave服务器同步的Master服务器的id和同步的偏移量。repl_backlog、repl_back_off和repl_backlog_histlen:Master服务器的后台缓冲区、后台缓冲区偏移及长度。
下面代码就是Master服务器判断是否需要完全同步的逻辑:
int masterTryPartialResynchronization(client *c) {
if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) !=
C_OK) goto need_full_resync;
if (strcasecmp(master_replid, server.replid) &&
(strcasecmp(master_replid, server.replid2) ||
psync_offset > server.second_replid_offset))
{
goto need_full_resync;
}
if (!server.repl_backlog ||
psync_offset < server.repl_backlog_off ||
psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen))
{
goto need_full_resync;
}
}
- 第一个判断表示无法解析
psync命令的参数reploff时,需要进行完全同步。原因:如果没有这个参数,我们就无法知道此前Slave服务器同步的是不是本Master服务器同步的; - 第二个判断,分为两个子判断:
Slave服务器发送过来的replid和当前Master服务器的replid不一致,并且Slave服务器发送过来的replid和当前Master服务器的replid2不一致,需要进行完全同步;Slave服务器发送过来的replid和当前Master服务器的replid不一致,并且Slave服务器请求的同步速度快于Master服务器;
- 第三个判断表示
Master服务器是否有后台日志缓冲区,如果没有,则需要进行完全同步;如果有,则继续判断待同步的偏移是否在后台日志缓冲区的范围内,如果不在后台日志缓冲区的范围内,则需要进行完全同步。换句话说,只有Master服务器有后台日志缓冲区,并且Slave服务器发过来的同步偏移量在后台日志缓冲区记录的范围之内,才能进行部分同步。
完全同步代码实现
完全同步的实现是比较简单,下面来看看Master服务器和Slave服务器所需要执行的逻辑。
Master服务器端:加载并读取RDB文件,写入Slave客户端的套接字,具体实现逻辑如下(提取主要部分):
void sendBulkToSlave(aeEventLoop *el, int fd, void *privdata, int mask) {
if (slave->replpreamble) {
nwritten = write(fd,slave->replpreamble,sdslen(slave->replpreamble));
}
buflen = read(slave->repldbfd,buf,PROTO_IOBUF_LEN);
nwritten = write(fd,buf,buflen);
slave->repldboff += nwritten;
if (slave->repldboff == slave->repldbsize) {
close(slave->repldbfd);
slave->repldbfd = -1;
aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE);
putSlaveOnline(slave);
}
}
上面代码最后一段逻辑表明:完全同步完成后,Slave服务器成为部分同步的客户端被加入到Master服务器的server.slaves中。结合前面对部分同步的分析,此后Slave就开始了部分同步的过程,通过增量式来实现主从同步。
Slave服务器端:读取来自服务器发过来的RDB字节流,保存到本地的RDB文件。字节流读取完毕后,清空Slave服务器上的所有数据,然后重新加载RDB文件,从而实现主从完全同步。具体实现逻辑如下(提取主要部分):
void readSyncBulkPayload(aeEventLoop *el, int fd, void *privdata, int mask) {
if (server.repl_transfer_size == -1) {
syncReadLine(fd,buf,1024,server.repl_syncio_timeout*1000);
server.repl_transfer_size = strtol(buf+1,NULL,10);
serverLog(LL_NOTICE,
"MASTER <-> REPLICA sync: receiving %lld bytes from master",
(long long) server.repl_transfer_size);
return;
}
left = server.repl_transfer_size - server.repl_transfer_read;
readlen = (left < (signed)sizeof(buf)) ? left : (signed)sizeof(buf);
nread = read(fd,buf,readlen);
write(server.repl_transfer_fd,buf,nread);
/* Check if the transfer is now complete */
if (server.repl_transfer_read == server.repl_transfer_size)
eof_reached = 1;
if (eof_reached) {
rename(server.repl_transfer_tmpfile,server.rdb_filename);
emptyDb(
-1,
server.repl_slave_lazy_flush ? EMPTYDB_ASYNC : EMPTYDB_NO_FLAGS,
replicationEmptyDbCallback);
rdbLoad(server.rdb_filename,&rsi);
}
}
需要指出的是,Slave服务器读取到RDB字节流后,先写入一个临时文件中server.repl_transfer_tmpfile中,等同步完成后,将临时文件重命名为正式的RDB文件server.rdb_filename。
Redis高可用——副本机制的更多相关文章
- Redis高可用详解:持久化技术及方案选择
文章摘自:https://www.cnblogs.com/kismetv/p/9137897.html 前言 在上一篇文章中,介绍了Redis的内存模型,从这篇文章开始,将依次介绍Redis高可用相关 ...
- Redis高可用详解:持久化技术及方案选择 (推荐)--转载自编程迷思博客www.cnblogs.com/kismetv/p/8654978.html
一.Redis高可用概述 在介绍Redis高可用之前,先说明一下在Redis的语境中高可用的含义. 我们知道,在web服务器中,高可用是指服务器可以正常访问的时间,衡量的标准是在多长时间内可以提供正常 ...
- Redis 高可用篇:你管这叫主从架构数据同步原理?
在<Redis 核心篇:唯快不破的秘密>中,「码哥」揭秘了 Redis 五大数据类型底层的数据结构.IO 模型.线程模型.渐进式 rehash 掌握了 Redis 快的本质原因. 接着,在 ...
- Keepalived+Redis高可用部署(第二版)
更新 20150625 脚本由5个减少为4个,sh脚本指令做了精简. 修改了另外3个脚本,在日志里增加了日期显示. 新增redis数据类型,持久化,主从同步简介. 新增hiredis简介. 新增c语言 ...
- Redis 高可用集群
Redis 高可用集群 Redis 的集群主从模型是一种高可用的集群架构.本章主要内容有:高可用集群的搭建,Jedis连接集群,新增集群节点,删除集群节点,其他配置补充说明. 高可用集群搭建 集群(c ...
- sentinel监控redis高可用集群(一)
一.首先配置redis的主从同步集群. 1.主库的配置文件不用修改,从库的配置文件只需增加一行,说明主库的IP端口.如果需要验证的,也要加多一行,认证密码. slaveof 192.168.20.26 ...
- 如何构建 Redis 高可用架构?
温国兵 民工哥技术之路 今天 1 .题记 Redis 是一个开源的使用 ANSI C 语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value 数据库,并提供多种语言的 API. 如今,互 ...
- Redis高可用集群-哨兵模式(Redis-Sentinel)搭建配置教程【Windows环境】
No cross,no crown . 不经历风雨,怎么见彩虹. Redis哨兵模式,用现在流行的话可以说就是一个"哨兵机器人",给"哨兵机器人"进行相应的配置 ...
- Redis高可用
redis高可用只要在于三个方面 主从复制 哨兵机制 集群机制 主从复制 主从复制作用: 1.数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式.2.故障恢复:当主节点出现问题时,可 ...
随机推荐
- 2020牛客暑假多校训练营 第二场 G Greater and Greater bitset
LINK:Greater and Greater 确实没能想到做法. 考虑利用bitset解决问题. 做法是:逐位判断每一位是否合法 第一位 就是 bitset上所有大于\(b_1\)的位置 置为1. ...
- github 错误
Push failed: Unable to access 'https://github.com/infoo/Neo4j.git/': The requested URL returned erro ...
- 对Word2Vec的理解
1. word embedding 在NLP领域,首先要把文字或者语言转化为计算机能处理的形式.一般来说计算机只能处理数值型的数据,所以,在NLP的开始,有一个很重要的工作,就是将文字转化为数字,把这 ...
- Python画各种 3D 图形Matplotlib库
回顾 2D 作图 用赛贝尔曲线作 2d 图.此图是用基于 Matplotlib 的 Path 通过赛贝尔曲线实现的,有对赛贝尔曲线感兴趣的朋友们可以去学习学习,在 matplotlib 中,figur ...
- 使用QT实现一个简单的登陆对话框(纯代码实现C++)
使用QT实现一个简单的登陆对话框(纯代码实现C++) 效果展示 使用的QT控件 控件 描述 QLable 标签 QLineEdit 行文本框 QPushButton 按扭 QHBoxLayout 水平 ...
- VMware启动CentOS出错,提示"该虚拟机似乎正在使用中"
今天在使用VMware启动CentOS时,出现如下图1错误提示: 当点击“确定”按钮时,出现如下图2错误提示: 无奈,只能点击图1 中的“取消”按钮,进行问题的跟踪.分析.经过核实,发现上述问题是由于 ...
- 如何有效防止sql注入
SQL注入攻击是黑客对数据库进行攻击常用的手段之一,随着B/S模式应用开发的发展,使用这种模式编写应用程序的程序员也越来越多.但是由于程序员的水平及经验参差不齐,相当大一部分程序员在编写代码的时候,没 ...
- java方法与方法的重载
一 方法 1.方法的概述 在java中,方法就是用来完成解决某件事情或实现某个功能的办法. 方法实现的过程中,会包含很多条语句用于完成某些有意义的功能——通常是处理文本, 控制输入或计算数值.我们可以 ...
- 03 Arduino-模拟输出与PWM的操作方法
在arduino开发板上面,标注为PWM的管脚的可以被当作数模转换管脚使用 01 模拟输出 analogWrite(pin, value) pin: 选定的引脚号码 value:取值范围 0-25 ...
- 图论算法(三) 最短路SPFA算法
我可能要退役了…… 退役之前,写一篇和我一样悲惨的算法:SPFA 最短路算法(二)SPFA算法 Part 1:SPFA算法是什么 其实呢,SPFA算法只是在天朝大陆OIers的称呼,它的正统名字叫做: ...