【模式识别与机器学习】——PCA与Kernel PCA介绍与对比
PCA与Kernel PCA介绍与对比
1. 理论介绍
PCA:是常用的提取数据的手段,其功能为提取主成分(主要信息),摒弃冗余信息(次要信息),从而得到压缩后的数据,实现维度的下降。其设想通过投影矩阵将高维信息转换到另一个坐标系下,并通过平移将数据均值变为零。PCA认为,在变换过后的数据中,在某一维度上,数据分布的更分散,则认为对数据点分布情况的解释力就更强。故在PCA中,通过方差来衡量数据样本在各个方向上投影的分布情况,进而对有效的低维方向进行选择。
KernelPCA:是PCA的一个改进版,它将非线性可分的数据转换到一个适合对齐进行线性分类的新的低维子空间上,核PCA可以通过非线性映射将数据转换到一个高维空间中,在高维空间中使用PCA将其映射到另一个低维空间中,并通过线性分类器对样本进行划分。
核函数:通过两个向量点积来度量向量间相似度的函数。常用函数有:多项式核、双曲正切核、径向基和函数(RBF)(高斯核函数)等。
2. 技术实现
(1)在KernelPCA中,这个问题同样是求特征向量的问题,只不过目标矩阵是经过核变换之后的协方差矩阵;与前相同,这个问题解决的实质还是要求C矩阵的特征向量,但对C求特征向量的过程较为复杂,经过了几次矩阵变化,先求得与核变换有关的矩阵K 的特征向量a,再通过变换方程与a的点乘得到协方差矩阵的特征向量v。
(2)Kernel版的PCA思想是比较简单的,我们同样需要求出Covariance matrix C,但不同的是这一次我们要再目标空间中来求,而非原空间。
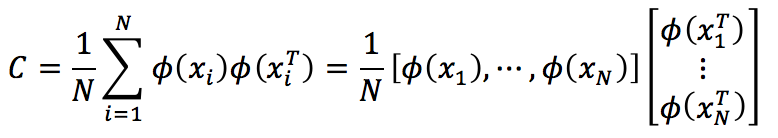
如果令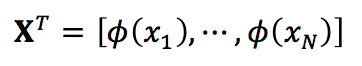
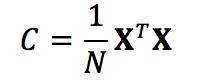
C和XTX具有相同的特征向量。但现在的问题是Φ是隐式的,我们并不知道。所以,我们需要设法借助核函数K来求解XTX。
因为核函数K是已知的,所以XXT是可以算得的。
(3)扼要总结如下:
Solve the following eigenvalue problem:

The projection of the test sample Φ(xj) on the i-th eigenvector can be computed by
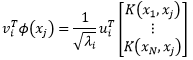
所得之vTi·Φ(xj)即为特征空间(Feature space)中沿着vi方向的坐标。
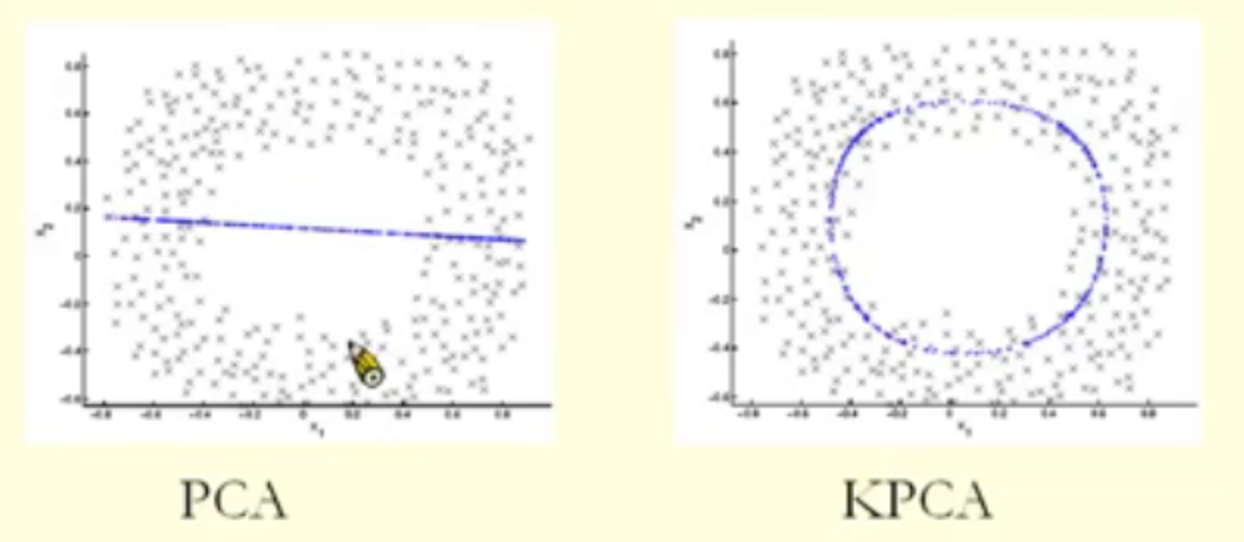
(4)最后我们给出的是一个KPCA的例子。其中左图是用传统PCA画出的投影。右图是在高维空间中找到投影点后又转换回原空间的效果。可见,加了核函数之后的PCA变得更加强大了。
具体推法:https://blog.csdn.net/zhangping1987/article/details/30492433
【模式识别与机器学习】——PCA与Kernel PCA介绍与对比的更多相关文章
- Probabilistic PCA、Kernel PCA以及t-SNE
Probabilistic PCA 在之前的文章PCA与LDA介绍中介绍了PCA的基本原理,这一部分主要在此基础上进行扩展,在PCA中引入概率的元素,具体思路是对每个数据$\vec{x}_i$,假设$ ...
- K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比
一.概述 在本篇文章中将对四种聚类算法(K-means,K-means++,ISODATA和Kernel K-means)进行详细介绍,并利用数据集来真实地反映这四种算法之间的区别. 首先需要明确 ...
- Kernel PCA 原理和演示
Kernel PCA 原理和演示 主成份(Principal Component Analysis)分析是降维(Dimension Reduction)的重要手段.每一个主成分都是数据在某一个方向上的 ...
- 四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
四大机器学习降维算法:PCA.LDA.LLE.Laplacian Eigenmaps 机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映 ...
- Kernel Methods (5) Kernel PCA
先看一眼PCA与KPCA的可视化区别: 在PCA算法是怎么跟协方差矩阵/特征值/特征向量勾搭起来的?里已经推导过PCA算法的小半部分原理. 本文假设你已经知道了PCA算法的基本原理和步骤. 从原始输入 ...
- 机器学习(4)——PCA与梯度上升法
主成分分析(Principal Component Analysis) 一个非监督的机器学习算法 主要用于数据的降维 通过降维,可以发现更便于人类理解的特征 其他应用:可视化.去噪 通过映射,我们可以 ...
- 机器学习笔记簿 降维篇 PCA 01
降维是机器学习中十分重要的部分,降维就是通过一个特定的映射(可以是线性的或非线性的)将高维数据转换为低维数据,从而达到一些特定的效果,所以降维算法最重要的就是找到这一个映射.主成分分析(Princip ...
- Robust De-noising by Kernel PCA
目录 引 主要内容 Takahashi T, Kurita T. Robust De-noising by Kernel PCA[C]. international conference on art ...
- Kernel PCA and De-Noisingin Feature Spaces
目录 引 主要内容 Kernel PCA and De-Noisingin Feature Spaces 引 kernel PCA通过\(k(x,y)\)隐式地将样本由输入空间映射到高维空间\(F\) ...
随机推荐
- wiremock技术入门
mock用于制作测试桩,是非常好用的自动化测试mock工具 一.下载 进入官网的下载地址: http://wiremock.org/docs/running-standalone/
- [Qt2D绘图]-02坐标系统&&抗锯齿渲染
本节的内容可以在帮助中通过Coordinate System关键字查看. 或者入门可以看<Qt Creator 快速入门>这本书.强烈推荐入门使用.下面的内容为本书的阅读笔记,喜欢的可以买 ...
- 从一次故障聊聊前端 UI 自动化测试
背景 事件的起因在于老板最近的两次"故障",一次去年的,一次最近.共同原因都是脚手架在发布平台发布打包时出错,导致线上应用白屏不可用. 最神奇的是,事后多次 Code Review ...
- css : 使用浮动实现左右各放一个元素时很容易犯的错误
比如说,有一个div,我想在左侧和右侧各方一个元素. 如果不想用flex,那就只能用浮动了. ... <div class="up clearfix"> <h6& ...
- SparkCore
一.概述 1,定义 RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象.代码中是一个抽象类,它代表一个不可变.可分区.里面的元素可 ...
- spring oauth2+JWT后端自动刷新access_token
这段时间在学习搭建基于spring boot的spring oauth2 和jwt整合. 说实话挺折腾的.使用jwt做用户鉴权,难点在于token的刷新和注销. 当然注销的难度更大,网上的一些方案也没 ...
- 利用Data vault对数据仓库建模
简介 国内关于Data Vault的信息很少,所以决定写点什么,纯粹都是自己在这个行业10多年的摸爬滚打.不过为了效率,尽量做到简短,直接上干货.对于各个细节大家有不同的理解欢迎来讨论. 数据仓库建模 ...
- 《数据可视化之美》高清PDF全彩版|百度网盘免费下载|Python数据可视化
<数据可视化之美>高清PDF全彩版|百度网盘免费下载|Python数据可视化 提取码:i0il 内容简介 <数据可视化之美>内容简介:可视化是数据描述的图形表示,旨在一目了然地 ...
- Jenkins部署jmx脚本
针对jenkins+jmeter做接口自动化,jmeter完成测试脚本录入和撰写,而jenkins负责持续集成和报告收集.那么从零实现jenkins可以从以下角度实现 首先需要安装jenkins ...
- JVM详解之:汇编角度理解本地变量的生命周期
目录 简介 本地变量的生命周期 举例说明 优化的原因 总结 简介 java方法中定义的变量,它的生命周期是什么样的呢?是不是一定要等到方法结束,这个创建的对象才会被回收呢? 带着这个问题我们来看一下今 ...