Scrapy使用RabbitMQ做任务队列
前言
一个月没更博客了,这个月也搞了不少东西,但是公司对保密性要求挺高,很多东西都没有办法写出来
想来想去,还是写一篇最近写Scrapy中遇到的跳转问题
如果你的业务需求是遇到301/302/303跳转的请求时继续请求网址,直到获取到最终的真实数据为止,那么这篇文章将会非常适合你
正文
队列选型
我们在使用SCRAPY中通常会使用分布式来提高爬取效率,所以需要一个任务队列来进行任务的下发,通常,该队列还承担着爬取的结果进行收集交由某几个Worker进行入库的作用
如果使用Redis作为任务队列,推荐使用 scrapy-redis 教程很多,这里不多说
这里着重介绍使用 RabbitMQ 作为任务队列,RabbitMQ的好处有很多,但是还是建议跟着业务走.
使用RabbitMQ作为任务队列
使用RabbitMQ作为任务队列的轮子很少,基本都已停止更新(17年),这里推荐一个国人的修改版,最近才开始发布,但是经本人实测已经可以正常使用
项目地址(GitHub)scrapy-rabbitmq-scheduler
因是国人写的,所以README文件写的通俗易懂.
安装
pip install scrapy-rabbitmq-scheduler
集成至Scrapy
在settings.py最后加入
# 指定项目的调度器
SCHEDULER = "scrapy_rabbitmq_scheduler.scheduler.SaaS"
# 指定rabbitmq的连接DSN
# amqp_url="amqp://username:password@ip:port/"
RABBITMQ_CONNECTION_PARAMETERS = 'amqp://admin:pwd@x.x.x.x:5672/'
# 指定重试的http状态码(重新加回队列重试)
# 如果结果的状态码位该list其中一个则会重试
# SCHEDULER_REQUEUE_ON_STATUS = [500]
# 指定下载器中间件, 确认任务是否成功
DOWNLOADER_MIDDLEWARES = {
'scrapy_rabbitmq_scheduler.middleware.RabbitMQMiddleware': 999
}
# 指定item处理方式, item会加入到rabbitmq中
ITEM_PIPELINES = {
'scrapy_rabbitmq_scheduler.pipelines.RabbitmqPipeline': 300,
}
爬虫编写
这里与Scrapy原来的方式稍有不同
构造发送请求/接收RabbitMQ数据的方法名为 _make_request
我们必须重构该方法才可正常运行使用爬虫
该方法起到每次从队列中拿取数据后的解析数据并进行请求的作用
通常我们存放在队列中的一个数据为一个JSON/msgpack格式,里面包含了要请求的URl/该条数据所属ID等多个信息
必须要注意的是如果遇到跳转或你在setting中设置了返回状态码为xxx重新爬取,那么Scrapy会将需要重新爬取的url存放至你的队列中,此时队列中有两种格式的数据
- 上游生产者发送的符合你的通信协议的数据(JSON/msgpack)
- Scrapy自己加入的需要重新爬取的数据
所以我们要对这两种数据加以区分
爬虫示例
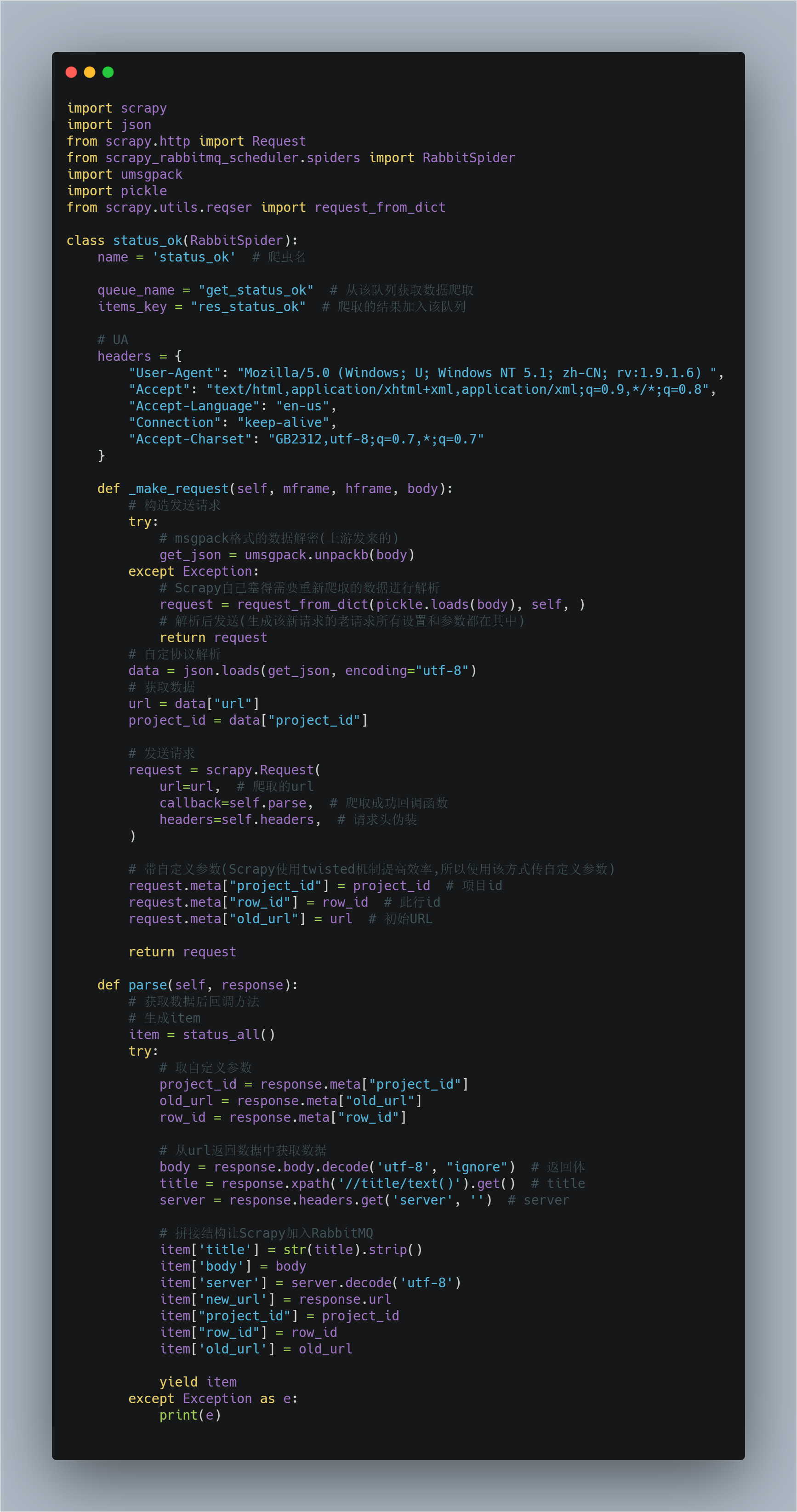
item是对返回数据序列化的,item
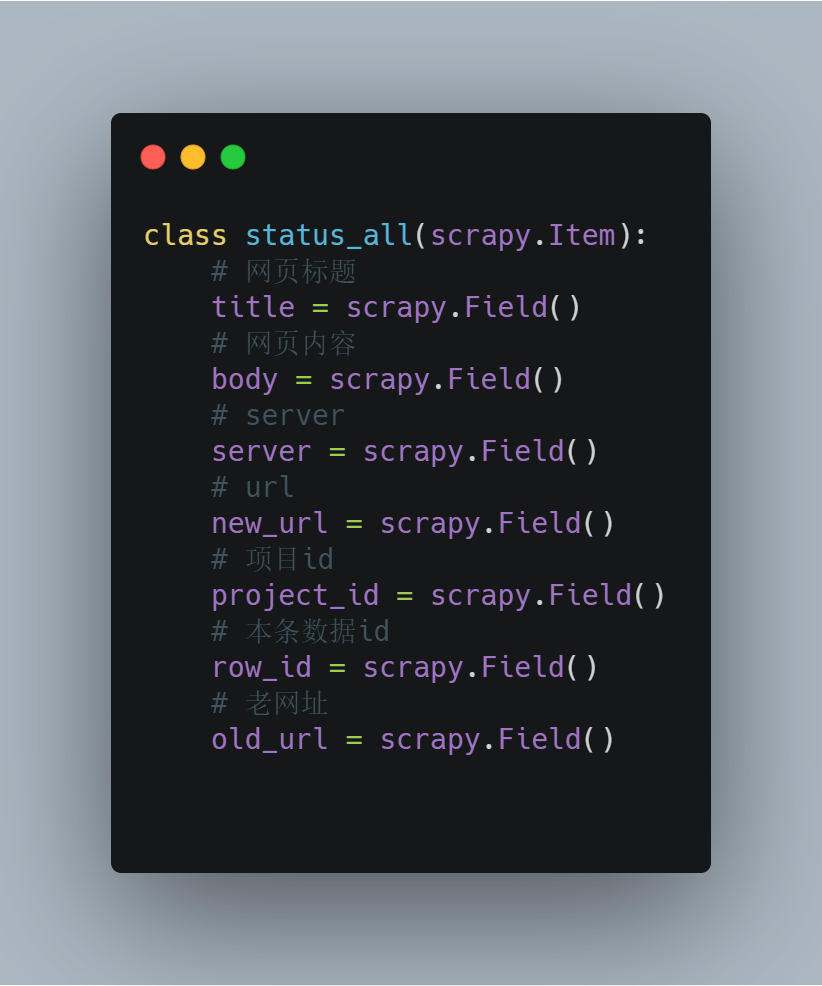
运行爬虫后,scrapy获取到的数据会转JSON传送至res_status_ok中(你自定义的)
添加个Work在队列另一端接收入库或其他操作即可
需要注意的点
Scrapy自己插入数据到分发队列
当时被这个问题卡了一小时,网上是没有解决方法的,他生成的数据也是不能使用常规方法进行解码的,这常常令人一头雾水
通道设置
该组件默认RabbitMQ持久化为True,因此请注意建立通道的时候将设置对齐否则会出现因为设置错误导致无法连接的问题
Scrapy使用RabbitMQ做任务队列的更多相关文章
- RabbitMQ之任务队列【译】
在第一个教程里面,我们写了一个程序从一个有名字的队列中发送和接收消息,在这里我们将要创建一个分发耗时任务给多个worker的任务队列. 任务队列核心思想就是避免执行一个资源密集型的任务,而程序要等待其 ...
- 使用IOCP完成端口队列做任务队列
使用IOCP完成端口队列做任务队列 与其自己费力设计异步任务队列,不如使用WINDOWS内核级的IOCP完成端口队列做任务队列. 1)引用单元 uses windows; 2)定义完成端口句柄 var ...
- springboot + rabbitmq 做智能家居,我也没想到会这么简单
本文收录在个人博客:www.chengxy-nds.top,共享技术资源,共同进步 前一段有幸参与到一个智能家居项目的开发,由于之前都没有过这方面的开发经验,所以对智能硬件的开发模式和技术栈都颇为好奇 ...
- (9)分布式下的爬虫Scrapy应该如何做-关于ajax抓取的处理(一)
转载请注明出处:http://www.cnblogs.com/codefish/p/4993809.html 最近在群里频繁的被问到ajax和js的处理问题,我们都知道,现在很多的页面都是用动态加载的 ...
- (8)分布式下的爬虫Scrapy应该如何做-图片下载(源码放送)
转载主注明出处:http://www.cnblogs.com/codefish/p/4968260.html 在爬虫中,我们遇到比较多需求就是文件下载以及图片下载,在其它的语言或者框架中,我们可能 ...
- 集成RabbitMQ做秒杀
由于秒杀的并发量太大,所以仅仅使用缓存是不够的,还需要用到RabbitMQ. 这里推荐一款用于分库分表的中间件:mycat 解决超卖的问题(看第五章节): 秒杀接口优化: 实操: 然后把下载好的文件上 ...
- (4)分布式下的爬虫Scrapy应该如何做-规则自动爬取及命令行下传参
本次探讨的主题是规则爬取的实现及命令行下的自定义参数的传递,规则下的爬虫在我看来才是真正意义上的爬虫. 我们选从逻辑上来看,这种爬虫是如何工作的: 我们给定一个起点的url link ,进入页面之后提 ...
- (3)分布式下的爬虫Scrapy应该如何做-递归爬取方式,数据输出方式以及数据库链接
放假这段时间好好的思考了一下关于Scrapy的一些常用操作,主要解决了三个问题: 1.如何连续爬取 2.数据输出方式 3.数据库链接 一,如何连续爬取: 思考:要达到连续爬取,逻辑上无非从以下的方向着 ...
- (2)分布式下的爬虫Scrapy应该如何做-关于对Scrapy的反思和核心对象的介绍
本篇主要介绍对于一个爬虫框架的思考和,核心部件的介绍,以及常规的思考方法: 一,猜想 我们说的爬虫,一般至少要包含几个基本要素: 1.请求发送对象(sender,对于request的封装,防止被封) ...
随机推荐
- 题解-[WC2011]最大XOR和路径
[WC2011]最大XOR和路径 给一个 \(n\) 个点 \(m\) 条边(权值为 \(d_i\))的无向有权图,可能有重边和子环.可以多次经过一条边,求 \(1\to n\) 的路径的最大边权异或 ...
- Java集合源码分析(八)——WeakHashMap
简介 WeakHashMap 继承于AbstractMap,实现了Map接口. 和HashMap一样,WeakHashMap 也是一个散列表,它存储的内容也是键值对(key-value)映射,而且键和 ...
- 终于不再对transition和animation,傻傻分不清楚了 --vue中使用transition和animation
以前写页面注重在功能上,对于transition和animation是只闻其声,不见其人,对于页面动画效果心理一直痒痒的.最近做活动页面,要求页面比较酷炫,终于有机会认真了解了. transition ...
- 实验:非GTID 一主多从变级联架构
- vscode 编辑python文件
1 安装python 自动姿势 Chinese # 换成中文 path Autocomplete 路径自动补全 Vetur vue文件补全 配置文件 首选项-设置 应用程序 在 seyying.jso ...
- 百度网站统计和CNZZ网站统计对比
一,前言 百度统计和cnzz统计是目前市面上比较流行的两种web统计工具,接下来将对两个统计工具做初步的体验测评 百度网站统计相关介绍:全球最大的中文网站流量分析平台,帮助企业收集网站访问数据,提供流 ...
- HBase数据导入导出工具
hbase中自带一些数据导入.导出工具 1. ImportTsv直接导入 1.1 hbase中建表 create 'testtable4','cf1','cf2' 1.2 准备数据文件data.txt ...
- YT Downloader视频下载器
简介 YT Downloader视频下载器是一款非常知名的视频下载器,支持下载YouTube,Facebook,Dailymotion,Vimeo,Metacafe等数百个视频网站的视频 截图介绍 小 ...
- js上 十六、数组-2
十六.数组-2 #4.3万能法:splice(): #4.3.1.删除功能 语法:arr.splice(index,num); //num表示删除的长度 功能:从下标index位置开始,删除n ...
- 工具-Redis-使用(99.6.2)
@ 目录 1.启动 2.数据结构 3.String命令 4.其他常用命令 5.Hash命令 6.List命令 7.Set命令 8.Zset命令 关于作者 1.启动 redis-server 交互 re ...