kubernetes中有状态应用的优雅缩容
将有状态的应用程序部署到Kubernetes是棘手的。 StatefulSet使它变得容易得多,但是它们仍然不能解决所有问题。最大的挑战之一是如何缩小StatefulSet而不将数据留在断开连接的PersistentVolume成为孤立对象上。在这篇博客中,我将描述该问题和两种可能的解决方案。
通过StatefulSet创建的每个Pod都有自己的PersistentVolumeClaim(PVC)和PersistentVolume(PV)。当按一个副本按比例缩小StatefulSet的大小时,其Pod之一将终止,但关联的PersistentVolumeClaim和绑定到其的PersistentVolume保持不变。在随后扩大规模时,它们会重新连接到Pod。
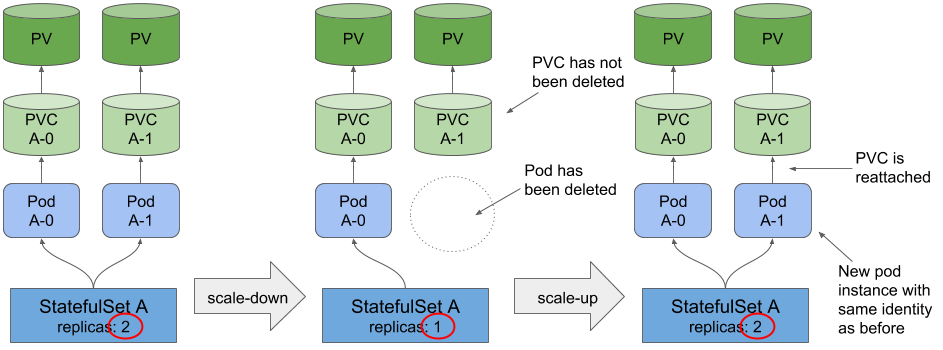 Scaling a StatefulSet
Scaling a StatefulSet
现在,想象一下使用StatefulSet部署一个有状态的应用程序,其数据在其pod中进行分区。每个实例仅保存和处理一部分数据。当您缩小有状态应用的规模时,其中一个实例将终止,其数据应重新分配到其余的Pod。如果您不重新分配数据,则在再次进行扩展之前,它仍然不可访问。
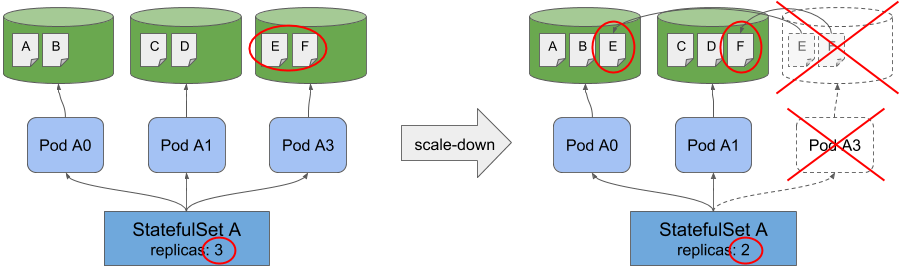 Redistributing data on scale-down
Redistributing data on scale-down
在正常关机期间重新分发数据
您可能会想:“既然Kubernetes支持Pod正常关闭的机制,那么Pod是否可以在关闭过程中简单地将其数据重新分配给其他实例呢?”事实上,它不能。为什么不这样做有两个原因:
- Pod(或更确切地说,其容器)可能会收到除缩容以外的其他原因的终止信号。容器中运行的应用程序不知道为什么终止该程序,因此不知道是否要清空数据。
- 即使该应用程序可以区分是缩容还是由于其他原因而终止,它也需要保证即使经过数小时或数天也可以完成关闭程序。 Kubernetes不提供该保证。如果应用程序进程在关闭过程中死掉,它将不会重新启动,因此也就没有机会完全分发数据。
因此,相信在正常关闭期间Pod能够重新分发(或以其他方式处理其所有数据)并不是一个好主意,并且会导致系统非常脆弱。
使用 tear-down 容器?
如果您不是Kubernetes的新手,那么你很可能知道什么是初始化容器。它们在容器的主要容器之前运行,并且必须在主要容器启动之前全部完成。
如果我们有tear-down容器(类似于init容器),但是在Pod的主容器终止后又会运行,该怎么办?他们可以在我们的有状态Pod中执行数据重新分发吗?
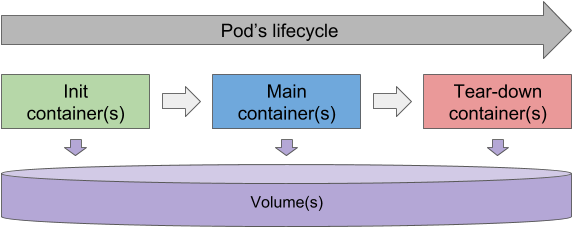
假设tear-down容器能够确定Pod是否由于缩容而终止。并假设Kubernetes(更具体地说是Kubelet)将确保tear-down容器成功完成(通过在每次返回非零退出代码时重新启动它)。如果这两个假设都成立,我们将拥有一种机制,可确保有状态的容器始终能够按比例缩小规模重新分配其数据。
但是?
可悲的是,当tear-down容器本身发生瞬态错误,并且一次或多次重新启动容器最终使它成功完成时,像上述的tear-down容器机制将只处理那些情况。但是,在tear-down过程中托管Pod的集群节点死掉的那些不幸时刻又如何呢?显然,该过程无法完成,因此无法访问数据。
现在很明显,我们不应该在Pod关闭时执行数据重新分配。相反,我们应该创建一个新的Pod(可能安排在一个完全不同的集群节点上)以执行重新分发过程。
这为我们带来了以下解决方案:
缩小StatefulSet时,必须创建一个新的容器并将其绑定到孤立的PersistentVolumeClaim。我们称其为“drain pod”,因为它的工作是将数据重新分发到其他地方(或以其他方式处理)。Pod必须有权访问孤立的数据,并且可以使用它做任何想做的事情。由于每个应用程序的重新分发程序差异很大,因此新的容器应该是完全可配置的-用户应该能够在drain Pod内运行他们想要的任何容器。
StatefulSet Drain Controller
由于StatefulSet控制器当前尚不提供此功能,因此我们可以实现一个额外的控制器,其唯一目的是处理StatefulSet缩容。我最近实现了这种控制器的概念验证。您可以在GitHub上找到源代码:
luksa/statefulset-scaledown-controllergithub.com
下面我们解释一下它是如何工作的。
在将控制器部署到Kubernetes集群后,您只需在StatefulSet清单中添加注释,即可将drain容器模板添加到任何StatefulSet中。这是一个例子:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: datastore
annotations:
statefulsets.kubernetes.io/drainer-pod-template: |
{
"metadata": {
"labels": {
"app": "datastore-drainer"
}
},
"spec": {
"containers": [
{
"name": "drainer",
"image": "my-drain-container",
"volumeMounts": [
{
"name": "data",
"mountPath": "/var/data"
}
]
}
]
}
}
spec:
...
该模板与StatefulSet中的主要Pod模板没有太大区别,只不过它是通过注释定义的。您可以像平常一样部署和扩展StatefulSet。
当控制器检测到按比例缩小了StatefulSet时,它将根据指定的模板创建新的drain容器,并确保将其绑定到PersistentVolumeClaim,该PersistentVolumeClaim先前已绑定至因按比例缩小而删除的有状态容器。
Drain容器获得与已删除的有状态容器相同的身份(即名称和主机名)。这样做有两个原因:
- 一些有状态的应用程序需要稳定的身份-这也可能在数据重新分发过程中适用。
- 如果在执行drain过程时再次扩容StatefulSet,则这将阻止StatefulSet控制器创建重复的容器并将其附加到同一PVC。
如果drain pod或其主机节点崩溃,则drain pod将重新安排到另一个节点上,在该节点上可以重试/恢复其操作。Drain pod完成后, Pod和PVC将被删除。备份StatefulSet时,将创建一个新的PVC。
示例
首先部署drain控制器:
$ kubectl apply -f https://raw.githubusercontent.com/luksa/statefulset-drain-controller/master/artifacts/cluster-scoped.yaml
接着部署示例StatefulSet:
$ kubectl apply -f https://raw.githubusercontent.com/luksa/statefulset-drain-controller/master/example/statefulset.yaml
这将运行三个有状态的Pod。将StatefulSet缩小为两个时,您会看到其中一个Pod开始终止。然后,删除Pod后,drain控制器将立即创建一个具有相同名称的新drain Pod:
$ kubectl scale statefulset datastore --replicas 2
statefulset.apps/datastore scaled
$ kubectl get po
NAME READY STATUS RESTARTS AGE
datastore-0 1/1 Running 0 3m
datastore-1 1/1 Running 0 2m
datastore-2 1/1 Terminating 0 49s
$ kubectl get po
NAME READY STATUS RESTARTS AGE
datastore-0 1/1 Running 0 3m
datastore-1 1/1 Running 0 3m
datastore-2 1/1 Running 0 5s <-- the drain pod
当drain pod 完成其工作时,控制器将其删除并删除PVC:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
datastore-0 1/1 Running 0 3m
datastore-1 1/1 Running 0 3m
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ...
data-datastore-0 Bound pvc-57224b8f-... 1Mi ...
data-datastore-1 Bound pvc-5acaf078-... 1Mi ...
控制器的另一个好处是它可以释放PersistentVolume,因为它不再受PersistentVolumeClaim约束。如果您的集群在云环境中运行,则可以降低存储成本。
总结
请记住,这仅是概念验证。要成为StatefulSet缩容问题的正确解决方案,需要进行大量工作和测试。理想情况下,Kubernetes StatefulSet控制器本身将支持这样的运行drain容器,而不是需要一个与原始控制器竞争的附加控制器(当您缩容并立即再次扩容时)。
通过将此功能直接集成到Kubernetes中,可以在StatefulSet规范中用常规字段替换注释,因此它将具有模板,volumeClaimTemplates和rainePodTemplate,与使用注释相比,一切都变得更好了。
kubernetes中有状态应用的优雅缩容的更多相关文章
- Kubernetes 笔记 11 Pod 扩容与缩容 双十一前后的忙碌
本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫. Hi,大家好, ...
- kubernetes常用命令:缩容扩容回滚
查看版本 kubectl version 查看节点 kubectl get nodes 部署app 说明: 提供deployment名称和app镜像地址(docker镜像地址) kubectl run ...
- 从零入门 Serverless | Serverless Kubernetes 应用部署及扩缩容
作者 | 邓青琳(轻零) 阿里云技术专家 导读:本文分为三个部分,首先给大家演示 Serverless Kubernetes 集群的创建和业务应用的部署,其次介绍 Serverless Kuberne ...
- kubernetes命令式容器应用编排/部署应用/探查应用详情/部署service对象/扩缩容/修改删除对象
部署Pod应用 创建delpoyment控制器对象 [root@master ~]# kubectl run myapp --image=ikubernetes/myapp:v1 --port=80 ...
- Airbnb的动态kubernetes集群扩缩容
Airbnb的动态kubernetes集群扩缩容 本文介绍了Airbnb的集群扩缩容的演化历史,以及当前是如何通过Cluster Autoscaler 实现自定义扩展器的.最重要的经验就是Airbnb ...
- Kubernetes 笔记 012 Pod 的自动扩容与缩容
本文首发于我的公众号 Linux云计算网络(id: cloud_dev),专注于干货分享,号内有 10T 书籍和视频资源,后台回复「1024」即可领取,欢迎大家关注,二维码文末可以扫. Hi,大家好, ...
- Docker Kubernetes 容器扩容与缩容
Docker Kubernetes 容器扩容与缩容 环境: 系统:Centos 7.4 x64 Docker版本:18.09.0 Kubernetes版本:v1.8 管理节点:192.168.1.79 ...
- Kubernetes 监控:Prometheus Adpater =》自定义指标扩缩容
使用 Kubernetes 进行容器编排的主要优点之一是,它可以非常轻松地对我们的应用程序进行水平扩展.Pod 水平自动缩放(HPA)可以根据 CPU 和内存使用量来扩展应用,前面讲解的 HPA 章节 ...
- Kubernetes有状态应用管理——PetSet
目录贴:Kubernetes学习系列 1.介绍 在Kubernetes中,大多数的Pod管理都是基于无状态.一次性的理念.例如Replication Controller,它只是简单的保证可提供服务的 ...
随机推荐
- animejs 动画库
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 创新全球算力生态价值,SPC算力生态强势来袭!
当前,区块链技术已经到了一个新的时代,即3.0时代.在区块链3.0时代,区块链技术迎来了数字经济革命,各行各业也在积极寻找与区块链能够融合的切入点.而随着区块链的愈加成熟,区块链技术也愈加被更多的人应 ...
- RxHttp - 轻量级、可扩展、易使用、完美兼容MVVM、MVC架构的网络封装类库
前言 RxHttp是基于RxJava2+Retrofit 2.9.0+OkHttp 4.9.0实现的轻量级,完美兼容MVVM架构的网络请求封装类库,小巧精致,简单易用,轻轻松松搞定网络请求. GitH ...
- Java中的CPU占用高和内存占用高的问题排查
下面通过模拟实例分析排查Java应用程序CPU和内存占用过高的过程.如果是Java面试,这2个问题在面试过程中出现的概率很高,所以我打算在这里好好总结一下. 1.Java CPU过高的问题排查 举个例 ...
- WPF 解决内置谷歌浏览器(Cef.ChromiumWebBrowser)在触摸屏无法进行滚动的问题
1.问题描述: 最近在WPF的项目中,需要在控件中嵌套可以浏览特定网页的内容,所以使用了 Cef.ChromiumWebBrowser来解决问题.在执行项目的过程中,主要碰到的问题有: 1.1 当把项 ...
- Nearby Service新特性:Wi-Fi分享
PART 1: Wi-Fi分享功能介绍 朋友来家里做客.顾客到店里用餐-当他们想要给自己的手机链接Wi-Fi时,总免不了询问Wi-Fi名称和密码..这种问密码和给密码的过程十分麻烦,常常还会有听错或者 ...
- Java并发之ThreadPoolExecutor源码解析(二)
ThreadPoolExecutor ThreadPoolExecutor是ExecutorService的一种实现,可以用若干已经池化的线程执行被提交的任务.使用线程池可以帮助我们限定和整合程序资源 ...
- js实现element中可清空的输入框(2)
接着上一篇的:js实现element中可清空的输入框(1)继续优化,感兴趣的可以去看看哟,直通车链接:https://www.cnblogs.com/qcq0703/p/14450001.html 实 ...
- JavaWeb之servlet管理机制
一.什么是Servlet 简单的说,浏览器发出请求到tocat服务器,服务器就会初始化一个servlet实例(servlet采取生命托管的方式实现单例,不存在时才会创建实例),servlet示例会启动 ...
- 后端程序员之路 21、一个cgi的c++封装
在"3.fastcgi.fastcgi++"中,我们了解了cgi,也尝试了fastcgi++,这里,再记录一种对fastcgi的封装. 1.cgi接口层 request_t ...