将CSV的数据发送到kafka(java版)
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
为什么将CSV的数据发到kafka
- flink做流式计算时,选用kafka消息作为数据源是常用手段,因此在学习和开发flink过程中,也会将数据集文件中的记录发送到kafka,来模拟不间断数据;
- 整个流程如下:
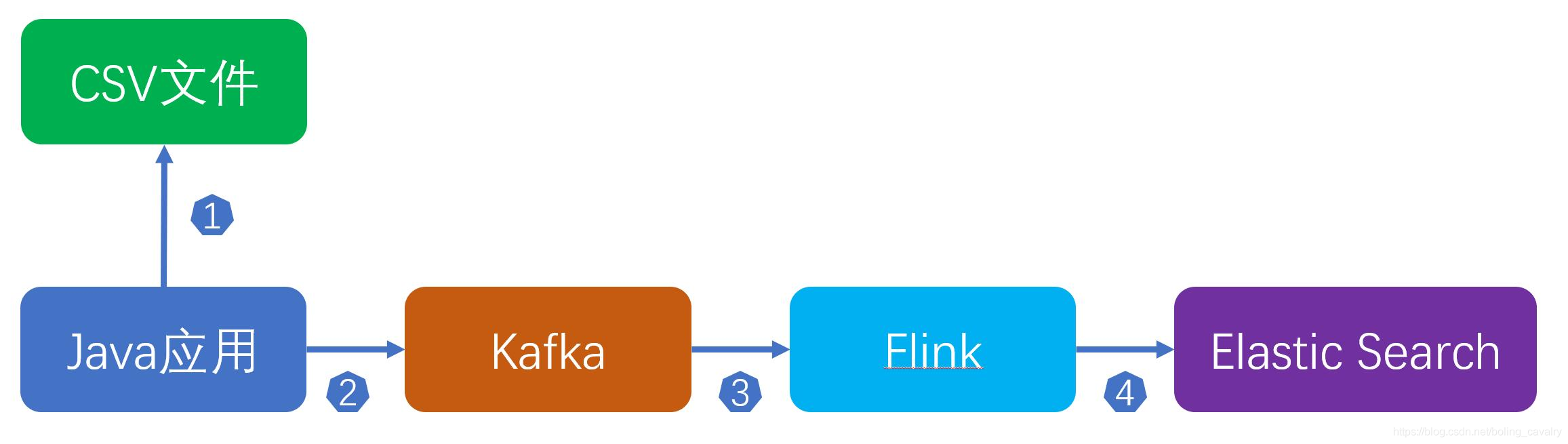
- 您可能会觉得这样做多此一举:flink直接读取CSV不就行了吗?这样做的原因如下:
- 首先,这是学习和开发时的做法,数据集是CSV文件,而生产环境的实时数据却是kafka数据源;
- 其次,Java应用中可以加入一些特殊逻辑,例如数据处理,汇总统计(用来和flink结果对比验证);
- 另外,如果两条记录实际的间隔时间如果是1分钟,那么Java应用在发送消息时也可以间隔一分钟再发送,这个逻辑在flink社区的demo中有具体的实现,此demo也是将数据集发送到kafka,再由flink消费kafka,地址是:https://github.com/ververica/sql-training
如何将CSV的数据发送到kafka
前面的图可以看出,读取CSV再发送消息到kafka的操作是Java应用所为,因此今天的主要工作就是开发这个Java应用,并验证;
版本信息
- JDK:1.8.0_181
- 开发工具:IntelliJ IDEA 2019.2.1 (Ultimate Edition)
- 开发环境:Win10
- Zookeeper:3.4.13
- Kafka:2.4.0(scala:2.12)
关于数据集
- 本次实战用到的数据集是CSV文件,里面是一百零四万条淘宝用户行为数据,该数据来源是阿里云天池公开数据集,我对此数据做了少量调整;
- 此CSV文件可以在CSDN下载,地址:https://download.csdn.net/download/boling_cavalry/12381698
- 也可以在我的Github下载,地址:https://raw.githubusercontent.com/zq2599/blog_demos/master/files/UserBehavior.7z
- 该CSV文件的内容,一共有六列,每列的含义如下表:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
| 时间字符串 | 根据时间戳字段生成的时间字符串 |
- 关于该数据集的详情,请参考《准备数据集用于flink学习》
Java应用简介
编码前,先把具体内容列出来,然后再挨个实现:
- 从CSV读取记录的工具类:UserBehaviorCsvFileReader
- 每条记录对应的Bean类:UserBehavior
- Java对象序列化成JSON的序列化类:JsonSerializer
- 向kafka发送消息的工具类:KafkaProducer
- 应用类,程序入口:SendMessageApplication
上述五个类即可完成Java应用的工作,接下来开始编码吧;
直接下载源码
- 如果您不想写代码,您可以直接从GitHub下载这个工程的源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
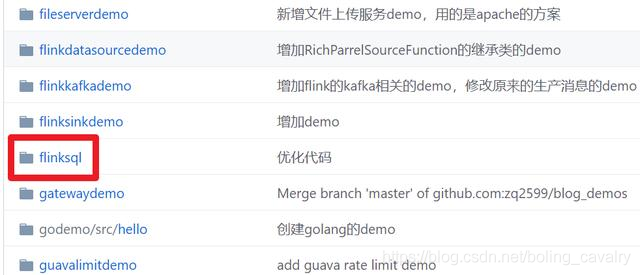
- 这个git项目中有多个文件夹,本章源码在flinksql这个文件夹下,如下图红框所示:
编码
- 创建maven工程,pom.xml如下,比较重要的jackson和javacsv的依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bolingcavalry</groupId>
<artifactId>flinksql</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<flink.version>1.10.0</flink.version>
<kafka.version>2.2.0</kafka.version>
<java.version>1.8</java.version>
<scala.binary.version>2.11</scala.binary.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.10.1</version>
</dependency>
<!-- Logging dependencies -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.7</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>net.sourceforge.javacsv</groupId>
<artifactId>javacsv</artifactId>
<version>2.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Java Compiler -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
</configuration>
</plugin>
<!-- Shade plugin to include all dependencies -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
</excludes>
</artifactSet>
<filters>
<filter>
<!-- Do not copy the signatures in the META-INF folder.
Otherwise, this might cause SecurityExceptions when using the JAR. -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 从CSV读取记录的工具类:UserBehaviorCsvFileReader,后面在主程序中会用到java8的Steam API来处理集合,所以UserBehaviorCsvFileReader实现了Supplier接口:
public class UserBehaviorCsvFileReader implements Supplier<UserBehavior> {
private final String filePath;
private CsvReader csvReader;
public UserBehaviorCsvFileReader(String filePath) throws IOException {
this.filePath = filePath;
try {
csvReader = new CsvReader(filePath);
csvReader.readHeaders();
} catch (IOException e) {
throw new IOException("Error reading TaxiRecords from file: " + filePath, e);
}
}
@Override
public UserBehavior get() {
UserBehavior userBehavior = null;
try{
if(csvReader.readRecord()) {
csvReader.getRawRecord();
userBehavior = new UserBehavior(
Long.valueOf(csvReader.get(0)),
Long.valueOf(csvReader.get(1)),
Long.valueOf(csvReader.get(2)),
csvReader.get(3),
new Date(Long.valueOf(csvReader.get(4))*1000L));
}
} catch (IOException e) {
throw new NoSuchElementException("IOException from " + filePath);
}
if (null==userBehavior) {
throw new NoSuchElementException("All records read from " + filePath);
}
return userBehavior;
}
}
- 每条记录对应的Bean类:UserBehavior,和CSV记录格式保持一致即可,表示时间的ts字段,使用了JsonFormat注解,在序列化的时候以此来控制格式:
public class UserBehavior {
@JsonFormat
private long user_id;
@JsonFormat
private long item_id;
@JsonFormat
private long category_id;
@JsonFormat
private String behavior;
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd'T'HH:mm:ss'Z'")
private Date ts;
public UserBehavior() {
}
public UserBehavior(long user_id, long item_id, long category_id, String behavior, Date ts) {
this.user_id = user_id;
this.item_id = item_id;
this.category_id = category_id;
this.behavior = behavior;
this.ts = ts;
}
}
- Java对象序列化成JSON的序列化类:JsonSerializer
public class JsonSerializer<T> {
private final ObjectMapper jsonMapper = new ObjectMapper();
public String toJSONString(T r) {
try {
return jsonMapper.writeValueAsString(r);
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("Could not serialize record: " + r, e);
}
}
public byte[] toJSONBytes(T r) {
try {
return jsonMapper.writeValueAsBytes(r);
} catch (JsonProcessingException e) {
throw new IllegalArgumentException("Could not serialize record: " + r, e);
}
}
}
- 向kafka发送消息的工具类:KafkaProducer:
public class KafkaProducer implements Consumer<UserBehavior> {
private final String topic;
private final org.apache.kafka.clients.producer.KafkaProducer<byte[], byte[]> producer;
private final JsonSerializer<UserBehavior> serializer;
public KafkaProducer(String kafkaTopic, String kafkaBrokers) {
this.topic = kafkaTopic;
this.producer = new org.apache.kafka.clients.producer.KafkaProducer<>(createKafkaProperties(kafkaBrokers));
this.serializer = new JsonSerializer<>();
}
@Override
public void accept(UserBehavior record) {
// 将对象序列化成byte数组
byte[] data = serializer.toJSONBytes(record);
// 封装
ProducerRecord<byte[], byte[]> kafkaRecord = new ProducerRecord<>(topic, data);
// 发送
producer.send(kafkaRecord);
// 通过sleep控制消息的速度,请依据自身kafka配置以及flink服务器配置来调整
try {
Thread.sleep(500);
}catch(InterruptedException e){
e.printStackTrace();
}
}
/**
* kafka配置
* @param brokers The brokers to connect to.
* @return A Kafka producer configuration.
*/
private static Properties createKafkaProperties(String brokers) {
Properties kafkaProps = new Properties();
kafkaProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
kafkaProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getCanonicalName());
kafkaProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, ByteArraySerializer.class.getCanonicalName());
return kafkaProps;
}
}
- 最后是应用类SendMessageApplication,CSV文件路径、kafka的topic和borker地址都在此设置,另外借助java8的Stream API,只需少量代码即可完成所有工作:
public class SendMessageApplication {
public static void main(String[] args) throws Exception {
// 文件地址
String filePath = "D:\\temp\\202005\\02\\UserBehavior.csv";
// kafka topic
String topic = "user_behavior";
// kafka borker地址
String broker = "192.168.50.43:9092";
Stream.generate(new UserBehaviorCsvFileReader(filePath))
.sequential()
.forEachOrdered(new KafkaProducer(topic, broker));
}
}
验证
- 请确保kafka已经就绪,并且名为user_behavior的topic已经创建;
- 请将CSV文件准备好;
- 确认SendMessageApplication.java中的文件地址、kafka topic、kafka broker三个参数准确无误;
- 运行SendMessageApplication.java;
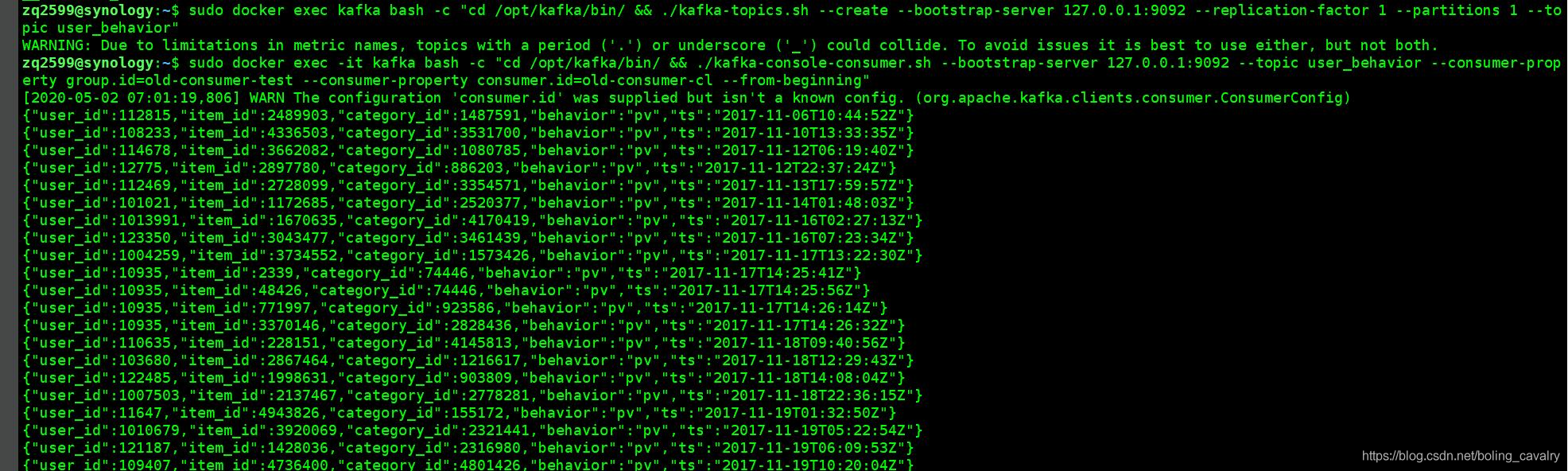
- 开启一个 控制台消息kafka消息,参考命令如下:
./kafka-console-consumer.sh \
--bootstrap-server 127.0.0.1:9092 \
--topic user_behavior \
--consumer-property group.id=old-consumer-test \
--consumer-property consumer.id=old-consumer-cl \
--from-beginning
- 正常情况下可以立即见到消息,如下图:
至此,通过Java应用模拟用户行为消息流的操作就完成了,接下来的flink实战就用这个作为数据源;
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
将CSV的数据发送到kafka(java版)的更多相关文章
- flume将数据发送到kafka、hdfs、hive、http、netcat等模式的使用总结
1.source为http模式,sink为logger模式,将数据在控制台打印出来. conf配置文件如下: # Name the components on this agent a1.source ...
- 基于GDAL库,读取.grd文件(以海洋地形数据为例)Java版
技术背景 海洋地形数据主要是通过美国全球地形起伏数据(GMT)获得,数据格式为grd(GSBG)二进制数据,打开软件通过是Surfer软件,surfer软件可进行数据的编辑处理,以及进一步的可视化表达 ...
- [Kafka] - Kafka Java Producer代码实现
根据业务需要可以使用Kafka提供的Java Producer API进行产生数据,并将产生的数据发送到Kafka对应Topic的对应分区中,入口类为:Producer Kafka的Producer ...
- Oracle Berkeley DB Java 版
Oracle Berkeley DB Java 版是一个开源的.可嵌入的事务存储引擎,是完全用 Java 编写的.它充分利用 Java 环境来简化开发和部署.Oracle Berkeley DB Ja ...
- Java版分布式ID生成器技术介绍
分布式全局ID生成器作为分布式架构中重要的组成部分,在高并发场景下承载着分担数据库写瓶颈的压力. 之前实现过PHP+Swoole版,性能和稳定性在生产环境下运行良好.这次使用Java进行重写,目前测试 ...
- java 两个csv文件数据去重
1.pom.xml配置 <dependency> <groupId>commons-io</groupId> <artifactId>commons-i ...
- 大数据学习day31------spark11-------1. Redis的安装和启动,2 redis客户端 3.Redis的数据类型 4. kafka(安装和常用命令)5.kafka java客户端
1. Redis Redis是目前一个非常优秀的key-value存储系统(内存的NoSQL数据库).和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list ...
- java读取目录下所有csv文件数据,存入三维数组并返回
package dwzx.com.get; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; ...
- JAVA版Kafka代码及配置解释
伟大的程序员版权所有,转载请注明:http://www.lenggirl.com/bigdata/java-kafka.html.html 一.JAVA代码 kafka是吞吐量巨大的一个消息系统,它是 ...
随机推荐
- ls: 显示目下的内容及相关属性信息
ls: 显示目下的内容及相关属性信息 [功能说明] ls 命令可以理解为英文单词 "list" 的缩写,其功能是列出目录的内容及其内容属性信息(list directory con ...
- linux的bootmem内存管理
内核刚开始启动的时候如果一步到位写一个很完善的内存管理系统是相当麻烦的.所以linux先建立了一个非常简单的临时内存管理系统bootmem,有了这个bootmem就可以做简单的内存分配/释放操作,在b ...
- 晋城6397.7539(薇)xiaojie:晋城哪里有xiaomei
晋城哪里有小姐服务大保健[微信:6397.7539倩儿小妹[晋城叫小姐服务√o服务微信:6397.7539倩儿小妹[晋城叫小姐服务][十微信:6397.7539倩儿小妹][晋城叫小姐包夜服务][十微信 ...
- localhost与127.0.0.1与0.0.0.0
localhost localhost其实是域名,一般系统默认将localhost指向127.0.0.1,但是localhost并不等于127.0.0.1,localhost指向的IP地址是可以配置的 ...
- shell脚本算术运算
自增自减操作 用let命令可以实现自增自减的命令,不需要$符号: #!/bin/bash set -e n=100 let n++ echo $n 还可以实现自增自减指定的值: #!/bin/bash ...
- pytest文档44-allure.dynamic动态生成用例标题
前言 pytest 结合 allure 描述用例的时候我们一般使用 @allure.title 和 @allure.description 描述测试用例的标题和详情. 在用例里面也可以动态更新标题和详 ...
- 面试官:如何写出让 CPU 跑得更快的代码?
前言 代码都是由 CPU 跑起来的,我们代码写的好与坏就决定了 CPU 的执行效率,特别是在编写计算密集型的程序,更要注重 CPU 的执行效率,否则将会大大影响系统性能. CPU 内部嵌入了 CPU ...
- monolog封装
做一下基本关于Monolog的基本介绍: Monolog是基于PHP的日志类库. 介绍就到这,言归正传 安装 安装最新版本:(composer 还没安装的~:https://www.phpcompos ...
- 【认知服务 Azure Cognitive Service】使用认知服务的密钥无法访问语音服务[ErrorCode=AuthenticationFailure] (2020-08时的遇见的问题,2020-09月已解决)
问题情形 根据微软认知服务的文档介绍,创建认知服务(Cognitive Service)后,可以调用微软的影像(计算机视觉,人脸),语言(LUIS, 文本分析,文本翻译),语音(文本转语音,语音转文本 ...
- 国产化即时通信系统开发 -- 实现GGTalk的登录界面(Linux、Ubuntu、UOS、中标麒麟)
距离2013年开源GGTalk以来,7年已经过去了,GGTalk现在有了完整的PC版.安卓版.iOS版(即将发布),以及Xamarin版本. 然而,时代一直在变化,在今天,有个趋势越来越明显,那就是政 ...