Hadoop高可用
一、原因
- NameNode是HDFS的黑心配置HDFS有事hadoop的核心组件 NameNode 在Hadoop及群众至关重要
- NameNode的宕机导致集群的不可用
二、解决方案
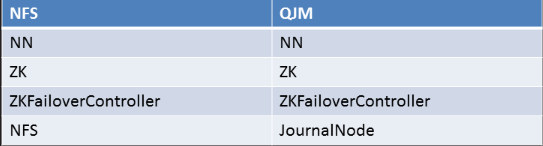
其中 NN表示两台 NameNode ZK表示 zookeeper(保持事务的一致性)
两种 1. HDFS with nfs 2. HDFS with QJM
方案对比
(一)都能实现热备
(二)都是一个Active NN一个 Stabdby NN
(三)都是用zookeeper和zkfc来实践自动失效恢复(事务一致)
(四)失效切换都试用Fencin配置的方法来Active NN
(五)NFS数据共享变更方案把数据存储在共享存储里,我们还需要考虑NFS的高可用
(六)QJM不需要共享存储 但需要让内个DN都知道两个NN的位置 并把块信息和心跳包发送给Active和Standby这两个NN
三、选择QJM
QJM不需要共享存储,客户端访问NameNode1后,数据存储完成,DataNode会返还给NameNode1数据存储位置,这时就会生成fsimage文件,那么把返还的数据信息给NameNode2一份 。fsedit数据变更日志 NameNode1 把数据变成日志记录在 JNS 上(相当于MySQL的中继日志) NameNode2读取JNS的数据(JNS可以做成高可用)
(一)解决NameNode单点故障问题
(二)Hadoop给出的HDFS的高可应用HA方案 HDFS通常有两个NameNode组成 一个处于Active另一个处于Standby状态 ACtive NameNode对外提供服务 比如处理来自客户端的PRC请求 而 Standby NameNode 则不对外提供服务 仅同步 Active NameNode的状态 以便能够在失败时能够进行切换
(三)高可用图

系统规划图

(四)安装
(1)配置 hosts 文件并且传给所有的机器
(2)给nn02配置公钥、私钥(如果是添加的nn02那么可以直接吧nn01的/root/.ssh/下的文件直接复制过去)
(3)安装zookeeper集群
(4)配置Hadoop文件
1.core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name> #文件系统
<value>hdfs://hadoop</value> #因为是NameNode有两台所以这里引用一个组的名字把这两台放在组中 这个组的名字不能全是数字
</property>
<property>
<name>hadoop.tmp.dir</name> #数据文件的存放目录
<value>/var/hadoop</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> #声明zookeeper
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>hadoop.proxyuser.nfsuser.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.nfsuser.hosts</name>
<value>*</value>
</property>
</configuration>
2.hadoop-env.sh
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre" #大约在25行,声明Java的安装路径 export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop" #大约在33行,生命Hadoop的安装路径
3.hdfs-site.xml
<property>
<name>dfs.nameservices</name> #声明组 core-site.xml 在这个文件中写的什么下面就要填什么
<value>hadoop</value>
</property>
<property>
<name>dfs.ha.namenodes.hadoop</name> #声明组中的角色名字
<value>nn1,nn2</value>
<property>
<name>dfs.namenode.rpc-address.hadoop.nn1</name> #组中nn1的机器是哪个 (rpc-address这两个心跳关系)
<value>nn01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop.nn2</name> #组中nn2的机器是哪个
<value>nn02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop.nn1</name> #声明NameNode nn1的机器
<value>nn01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop.nn2</name> #声明NameNode nn2的机器
<value>nn02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name> #声明journalnode的节点(数据更变日志)
<value>qjournal://node1:8485;node2:8485;node3:8485/nsd1905</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name> #声明journalnode的数据存放目录
<value>/var/hadoop/journal</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.nsd1905</name> #声明高可用的软件
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name> #声明ssh
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name> #声明ssh的存放目录
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name> #自动切换
<value>true</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/exclude</value>
</property>
4.mapred-site.xml
<property>
<name>mapreduce.framework.name</name> #声明管理方式
<value>yarn</value>
</property>
5.slaves (声明DateNode的节点)
node1
node2
node3
6.yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name> #打开ha高可用
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name> #声明rm的角色
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name> #打开resourcemanage 高可用的软件
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name> #yarn的数据存储的一个类
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name> #声明zookeeper地址
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name> #声明 id 组的名称
<value>yarn-ha</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name> #声明 rm1 对应的机器
<value>nn01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name> #声明 rm2 对应的机器
<value>nn02</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(五)启动服务
(1)验证zookeeper是否正常
(2)同步配置到所有机器
(3)初始化zookeeper集群(在NameNode1上操作)
/usr/local/hadoop/bin/hdfs zkfc -formatZK
(4)启动journalnode服务(node1 2 3 上操作)
/usr/local/hadoop/sbin/hadoop-daemon.sh start journalnode
(5)NameNode1初始化
/usr/local/hadoop//bin/hdfs namenode -format
(6)同步配置到 NameNode2上(因为初始化之后生成文件的id是唯一的所以只需要把文件直接 上传给NameNode2就行)
rsync -aSH nn01:/var/hadoop/ /var/hadoop/
(7)初始化JNS(NameNode1上操作)
/usr/local/hadoop/bin/hdfs namenode -initializeSharedEdits
(8)停止journalnode服务(在node 1 2 3 上操作)
/usr/local/hadoop/sbin/hadoop-daemon.sh stop journalnode
(9)启动集群(在NameNode1上操作)
/usr/local/hadoop/sbin/start-all.sh
(10)启动热备resourcemanager
/usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
(六)验证服务
(1)查看集群状态(可以看到一个是active一个是standby)
/usr/local/hadoop/bin/hdfs haadmin -getServiceState nn1
/usr/local/hadoop/bin/hdfs haadmin -getServiceState nn2
/usr/local/hadoop/bin/yarn rmadmin -getServiceState rm1
/usr/local/hadoop/bin/yarn rmadmin -getServiceState rm2
(2)查看节点是否加入
/usr/local/hadoop/bin/hdfs dfsadmin -report
(3)访问集群
/usr/local/hadoop/bin/hadoop fs -ls /
/usr/local/hadoop/bin/hadoop fs -mkdir /aa
/usr/local/hadoop/bin/hadoop fs -ls /
(4)验证高可用,关闭 active namenode (关闭之后再次查看状态会报错)
/usr/local/hadoop/sbin/hadoop-daemon.sh stop namenode
/usr/local/hadoop/sbin/yarn-daemon.sh stop resourcemanager
(5)恢复节点(回复完在查看)
/usr/local/hadoop/sbin/hadoop-daemon.sh start namenode
/usr/local/hadoop/sbin/yarn-daemon.sh start resourcemanager
Hadoop高可用的更多相关文章
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- HADOOP高可用机制
HADOOP高可用机制 HA运作机制 什么是HA HADOOP如何实现HA HDFS-HA详解 HA集群搭建 目标: 掌握分布式系统中HA机制的思想 掌握HADOOP内置HA的运作机制 掌握HADOO ...
- Hadoop 高可用(HA)的自动容灾配置
参考链接 Hadoop 完全分布式安装 ZooKeeper 集群的安装部署 0. 说明 在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高 ...
- zookeeper简易配置及hadoop高可用安装
zookeeper介绍 是一个分布式服务的协调服务,集群半数以上可用(一般配置为奇数台), 快速选举机制:当集群中leader挂掉,所有小弟会投票选举出新的leader. ...
- 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 二.集群规划 三.前置条件 四.集群配置 五.启动集群 六.查看集群 七.集群的二次启动 一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS ...
- Hadoop 学习之路(八)—— 基于ZooKeeper搭建Hadoop高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- hadoop高可用安装和原理详解
本篇主要从hdfs的namenode和resourcemanager的高可用进行安装和原理的阐述. 一.HA安装 1.基本环境准备 1.1.1.centos7虚拟机安装,详情见VMware安装Cent ...
- 六十一.常用组件 、 Kafka集群 、 Hadoop高可用
1.Zookeeper安装搭建Zookeeper集群并查看各服务器的角色停止Leader并查看各服务器的角色 1.1 安装Zookeeper1)编辑/etc/hosts ,所有集群主机可以相互 pin ...
- Hadoop高可用平台搭建
文章概览: 1.机器规划和预配置 2.软件安装 3.集群文件配置 4.启动集群 5.HA验证 6.注意事项 7.小结 机器规划和预配置 主机/进程 NN DN RM NM ZK(QP) ZKFC ...
随机推荐
- JQuery实现tab页
用ul 和 div 配合实现tab 页 1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="U ...
- Emgu.CV怎么加载Bitmap
EmguCV 在4.0.1版本之后没办法用Bitmap创建Image了. 我给大家说下 EmguCV怎么加载Bitmap 下边是 EmguCV 官方文档写的,意思是从4.0.1以后的版本不能直接Bit ...
- Power Designer建模之餐饮在线点评系统——业务处理模型
餐饮在线点评系统除查看会员促销活动.查看站内消息等简单业务流程外,相对复杂的业务流程包括管理员注册餐厅,发布餐厅信息,餐厅信息主要包括特色菜.促销活动.团购活动和优惠券信息. 餐厅信息发布后,用户可以 ...
- 《穷查理年鉴》习惯 & 工作 & 自省 & 自律 (关于自己)
习惯 001.在那充满古老年鉴的年代里,扔掉你的恶行,不管它们曾经给你带来多大的好处. 002.许多关于预言的争论都可以简化为:当你说是时,就有人说浊;当你认为不是时,一定有人说是. 003.坏习惯和 ...
- DE2资源集锦
1.The School of Electrical and Computer Engineering (ECE) at the Georgia Institute of Technology:htt ...
- linux的bootmem内存管理
内核刚开始启动的时候如果一步到位写一个很完善的内存管理系统是相当麻烦的.所以linux先建立了一个非常简单的临时内存管理系统bootmem,有了这个bootmem就可以做简单的内存分配/释放操作,在b ...
- 多测师讲解python _类(原始版)_高级讲师肖sir
# Python中的类: '''定义一个类:class +名称=类 在类当中定义:def +名称=实例方法(self)与类平齐def +名称=普通函数定义一个函数:def +名称=函数在函数中:函数( ...
- vue打包之后在本地运行,express搭建服务器,nginx 本地服务器运行
一.使用http-server 1.安装http-server npm install -g http-server 2.通过命令进入到dist文件夹 3.运行http-server 以上在浏览器输入 ...
- ansible2.4安装和体验
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- 从Linux源码看Socket(TCP)的listen及连接队列
从Linux源码看Socket(TCP)的listen及连接队列 前言 笔者一直觉得如果能知道从应用到框架再到操作系统的每一处代码,是一件Exciting的事情. 今天笔者就来从Linux源码的角度看 ...