Impala储存与分区
不多说,直接上干货!



hive的元数据存储在/user/hadoop/warehouse
Impala的内部表也在/user/hadoop/warehouse。
那两者怎么区分,看前面的第一列。
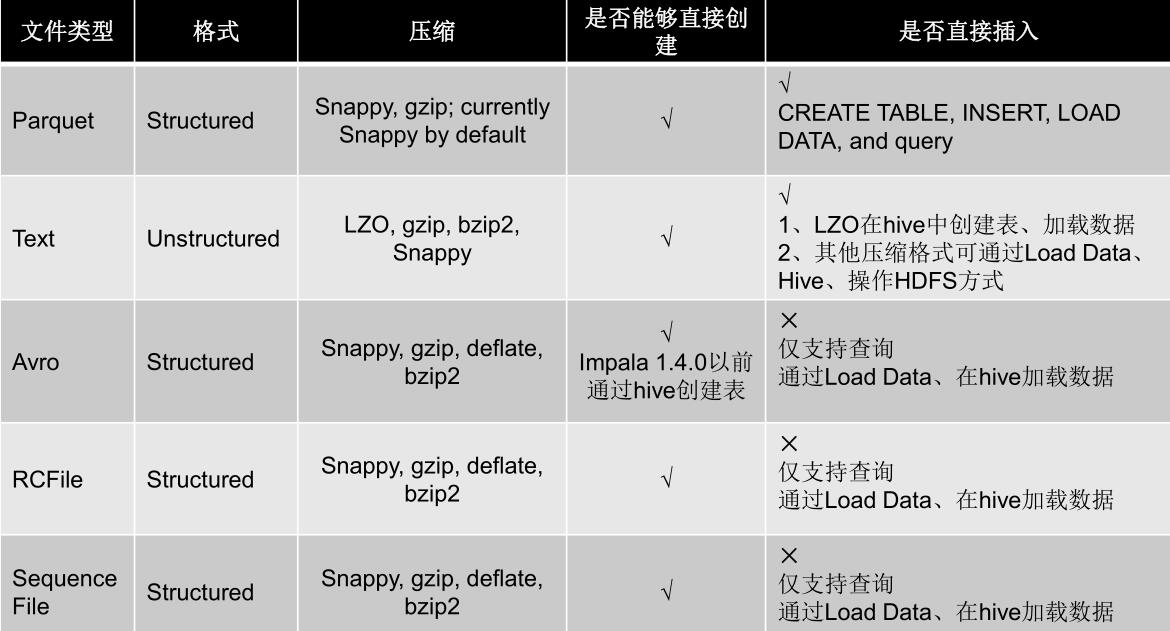
下面是Impala对文件的格式及压缩类型的支持

• 添加分区方式
– 1、partitioned by 创建表时,添加该字段指定分区列表
– 2、使用alter table 进行分区的添加和删除操作
create table t_person(id int, name string, age int) partitioned by (type string);
alter table t_person add partition (sex=‘man');
alter table t_person drop partition (sex=‘man');
alter table t_person drop partition (sex=‘man‘,type=‘boss’);
• 分区内添加数据
insert into t_person partition (type='boss') values (,’zhangsan’,),(,’lisi’,)
insert into t_person partition (type='coder') values(,wangwu’,),(,’zhaoliu’,),(,’tianqi’,)
• 查询指定分区数据
select id,name from t_person where type=‘coder
进行数据分区将会极大的提高数据查询的效率,尤其是对于当下大数据的运用,是一门不可或缺的知识。那数据怎么创建分区呢?数据怎样加载到分区
一、 Impala/Hive按State分区Accounts
(1)示例:accounts是非分区表

通过以上方式创建的话,数据就存放在accounts目录里面。那么,如果Loudacre大部分对customer表的分析是按state来完成的?比如:

这种情况下如果数据量很大,为了避免全表扫描的发生,我们可以去创建分区。如果不创建分区的话,它会默认所有查询不得不扫描目录的所有文件。创建分区按state将数据存储到不同的子目录,当按照“NY”的条件进行查询的时候,它只会扫描到子目录,下面我具体来看一下分区创建。
二、分区创建
(1)使用PARTITIONED BY来创建分区表

在这里注意state是被删除掉的,因为它作为分区字段,我们知道分区数据是不会出现在实际的文件当中的,所以state作为分区字段是不会出现在列当中的。换句话说,分区键就是一个虚列,它是不会存在列当中的。那么,如何去查看我们分区的列呢?它会出现在我们的结构当中吗?会的。
三、查看分区列
使用DESCRIBE显示分区列,它会出现在结构最后一列,它是一个虚列,并不是真实在数据中存在的列。

我们创建单个分区,但有时候会有嵌套分区,如何来处理呢?
四、创建嵌套分区:

创建好了分区,我们怎么加载数据到分区呢?有两种方式动态分区和静态分区。动态分区是指Impala/Hive在加载的时候自动添加新的分区,数据基于列值存储到正确的分区(子目录)。而静态分区需要我们通过ADD PARTITION提前去定义分区的名称,当加载数据的时候,指定存储数据到哪个分区。那么动态分区和静态分区各有什么特征呢?后续为大家接着分享。
Impala储存与分区的更多相关文章
- 【impala学习之二】impala 使用
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk8 CM5.4 一.Impala shell 1.进入impal ...
- Impala SQL 语言元素(翻译)[转载]
原 Impala SQL 语言元素(翻译) 本文来源于http://my.oschina.net/weiqingbin/blog/189413#OSC_h2_2 摘要 http://www.cloud ...
- 大数据时代快速SQL引擎-Impala
背景 随着大数据时代的到来,Hadoop在过去几年以接近统治性的方式包揽的ETL和数据分析查询的工作,大家也无意间的想往大数据方向靠拢,即使每天数据也就几十.几百M也要放到Hadoop上作分析,只会适 ...
- 转:大数据时代快速SQL引擎-Impala
本文来自:http://blog.csdn.net/yu616568/article/details/52431835 如有侵权 可立即删除 背景 随着大数据时代的到来,Hadoop在过去几年以接近统 ...
- Impala SQL 语言元素(翻译)
摘要: http://www.cloudera.com/content/cloudera-content/cloudera-docs/Impala/latest/Installing-and-Usin ...
- (3)SQL Server表分区
1.简介 当一个表数据量很大时候,很自然我们就会想到将表拆分成很多小表,在执行查询时候就到各个小表去查,最后汇总数据集返回给调用者加快查询速度.比如电商平台订单表,库存表,由于长年累月读写较多,积累数 ...
- Linux文件系统的实现
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! Linux文件管理从用户的层面介绍了Linux管理文件的方式.Linux有一个树状 ...
- (转)Linux文件系统的实现
作者:Vamei 出处:http://www.cnblogs.com/vamei 欢迎转载,也请保留这段声明.谢谢! Linux文件管理从用户的层面介绍了Linux管理文件的方式.Linux有一个树状 ...
- 2019/4/17 Linux学习
一.Linux的文件系统 其中/prov./srv./sys 文件为文件系统,技术不过硬不要去修改:二.关于Xshell.Xft1.服务器的端口可有65535个可设置,开的越多安全性越差:2.远程登录 ...
随机推荐
- 08:Challenge 1
总时间限制: 10000ms 单个测试点时间限制: 1000ms 内存限制: 262144kB 描述 给一个长为N的数列,有M次操作,每次操作是以下两种之一: (1)修改数列中的一个数 (2)求 ...
- 泪奔,配好了bioconductor环境
最近因为极度忙,没有写总结.今天补一下总结. 今天完成关静最后给的大project这个作业来说,结合自己的研究方向是个让我纠结一周多的事.好在找到了对应的研究内容. R的书目前还是很多的.R我一开始觉 ...
- UI Framework-1: Aura and Shell dependencies
Aura and Shell dependencies The diagram below shows the dependencies of Chrome, Ash (Aura shell), vi ...
- UI Framework-1: views
views Overview and background Windows provides very primitive tools for building user interfaces. Th ...
- WLAN STA/AP 并发
WLAN STA/AP 并发 Android 9 引入了可让设备同时在 STA 和 AP 模式下运行的功能.对于支持双频并发 (DBS) 的设备,此功能让一些新功能得以实现,例如在用户想要启用热点 ( ...
- Html Input disabled属性
input的disabled: <input type="text" name="name" placeholder="请输入名称" ...
- [洛谷P2045]方格取数加强版
题目大意:有一个n*n的矩阵,每个格子有一个非负整数,规定一个人从(1,1)开始,只能往右或下走,走到(n,n)为止,并把沿途的数取走,取走后数变为0.这个人共取n次,求取得的数的最大总和. 解题思路 ...
- websocket调试工具
http://www.blue-zero.com/WebSocket/ wss://yy.xxx.com/video/websocket/client.ws
- while循环合理运用-判断成绩脚本
在平时的工作生活中,难免不了去写一些交互性质的脚本,然而呢往往有些用户偏偏会输入不合规范的输入,为了避免就此退出脚本重新执行,这时候就可以用while去写一个死循环去针对用户的输出啊.哈哈~他输不对, ...
- 【转】 HtmlAgilityPack使用——XPath注意事项
[转] HtmlAgilityPack使用——XPath注意事项 在使用HtmlAgilityPack这个开源的类库进行网页内容解析的时候是非常的方便(使用方法见另一篇博客<HTML解析:基于X ...