Hawk 数据抓取工具 使用说明(二)
1. 调试模式和执行模式
1.1.调试模式
系统能够通过拖拽构造工作流。在编辑流的过程中,处于调试模式,为了保证快速地计算和显示当前结果(只显示前20个数据,可在调试的采样量中修改),此时,所有执行器都不会参与到工作流中,意味着数据库和数据表都不会被写入和更新。
(是否记得所有模块分为 生成,转换,过滤和执行四类?)
在调试时,从爬虫转换模块可能会请求web数据,为了提升性能,该模块对请求做了缓存。保证数据只需获取一次,如果想强制刷新数据,将从爬虫转换模块禁用,再启用,原始缓存数据就会被擦除。
 。
。
1.2执行模式
只有点击执行时,才会切换到执行模式。系统会切入到串行/并行模式,并行模式可以设置最大工作线程数,只有之前的工作线程完成工作,才会填入新的任务。
点击执行后,为了保证执行过程不受干扰,建议不要再修改各个模块的参数,此时刷新结果不可用。
当你想取消某一个任务,可以在任务管理视图的任务上,点右键选择取消任务即可。
2. 脚本系统
Hawk可以嵌入Python,以支持精细的控制,实现用图形界面难以操作的功能。Hawk使用IronPython作为解释器,其语法和Python3接近。
2.1 在工作流中使用脚本
我们用例子来讲解如何使用:
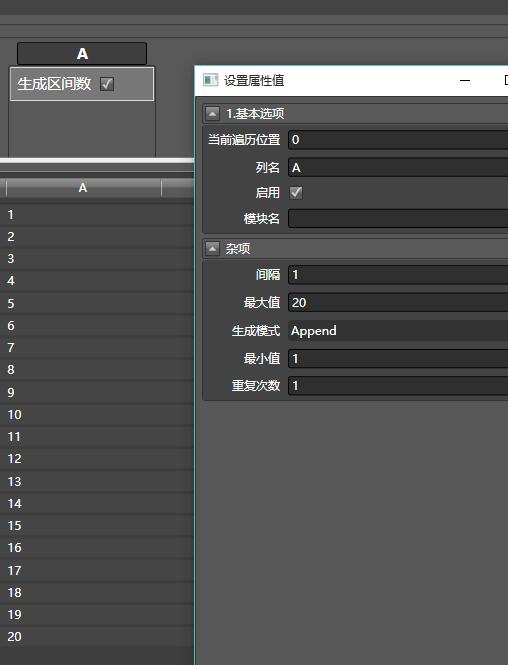
拖入生成区间数,添加一列,列名叫A,范围为1-20,间隔为1:
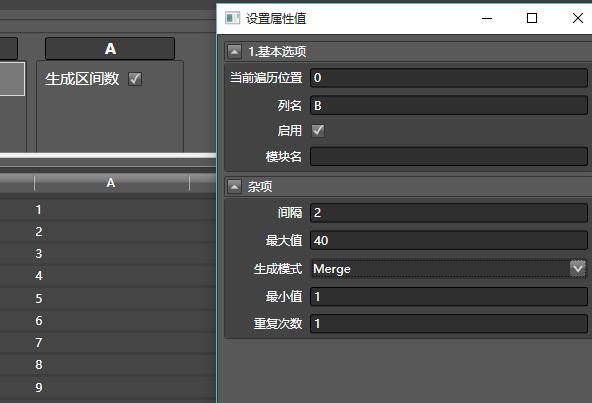
再拖入另外一个生成区间数,列名为B,范围1-40,间隔为2,注意生成模式为Merge。
此处介绍生成模式的区别:
- Merge:横向混合,形成另外独立的一列
- Append: 纵向添加,生成新的数据行,跟在后面
- Cross: 笛卡尔集,纵向组合,例如
(A,B) Cross (1,2,3) = A1,A2,A3,B1,B2,B3 - Mix:交叉混合:纵向组合,例如
(A,B,C) Mix (D,E,F)= A,D,B,E,C,F
基本上以上四种情况能足以应付绝大多数情形。
之后,将Python转换器拖入A列,设置如下:
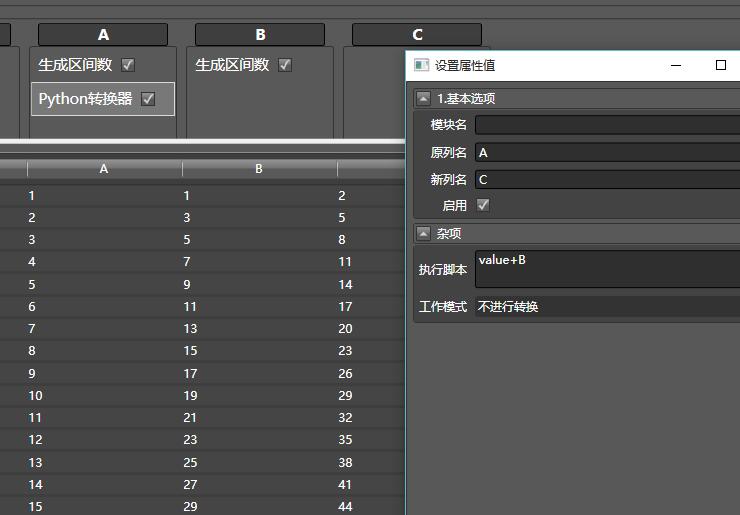
即可看到,多出了C列,且C=A+B。
脚本里,属性名可以直接作为变量使用,可以执行所有Python支持的操作。代码需要有返回值,但不需要return。拖入的列,除了可以用列名引用外,还可以使用value。当前的数据字典名称为data,因此上面的代码还可以写为:
data['A']+data['B']
值得注意的是,Python是强类型的语言,因此如果读入的是文本,上面的代码就会出错,应当改为:
int(A)+int(B)
2.2在加载任务时使用脚本
在定制抓取任务时,我们可以在界面上双击模块,修改工作流的参数,如采集不同城市的数据,之后再进行保存。
但这种做法比较麻烦,容易出错。因此,我们可以在工程文件的同一级目录放置Python脚本,在加载任务时,脚本会自动执行。
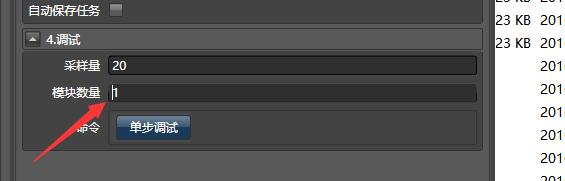
3.单步调试
已经编写的工作流,可能会因为某些外界环境的变化而出错,此时需要排除错误,我们可以使用单步调试:
还是上面A+B=C的例子:
在属性对话框,调试窗口里,填写模块数量为1,点击刷新结果,此时,系统会只执行第一步,显示A列。
点击单步调试,模块数量变为2,显示A和B列。
本质上,单步调试只是提取了工作流的一部分进行操作,你可以在单步调试中,拖入新的模块。模块会自动插入在工作流中间。
4.组合多个工作流
有时,不可能把所有的任务都在同一个工作流中实现。如果把工作流拆成不同的子流,那么就能方便重用和组合。
组合子模块的功能包含三类:子流-执行,子流-转换和子流-生成。为什么不包括子流-过滤?因为过滤操作通常比较简单,不需要子流实现。
- 子流-生成,作为生成器,一般在主流的开头位置。
- 子流-转换,可看成转换器,通常位于中间位置。
- 子流-执行:作为执行器,一般位于末尾。
值得指出,子流还可以调用其他的子流,形成树状的调用结构。
当加载一个任务时,该任务依赖的子任务也会自动加载。对子流的修改,也会传递到主流上。
(未完待续)
Hawk 数据抓取工具 使用说明(二)的更多相关文章
- 网页数据抓取工具,webscraper 最简单的数据抓取教程,人人都用得上
Web Scraper 是一款免费的,适用于普通用户(不需要专业 IT 技术的)的爬虫工具,可以方便的通过鼠标和简单配置获取你所想要数据.例如知乎回答列表.微博热门.微博评论.淘宝.天猫.亚马逊等电商 ...
- 汽车之家店铺商品详情数据抓取 DotnetSpider实战[二]
一.迟到的下期预告 自从上一篇文章发布到现在,大约差不多有3个月的样子,其实一直想把这个实战入门系列的教程写完,一个是为了支持DotnetSpider,二个是为了.Net 社区发展献出一份绵薄之力,这 ...
- Twitter数据抓取的方法(二)
Scraping Tweets Directly from Twitters Search Page – Part 2 Published January 11, 2015 In the previo ...
- [原创.数据可视化系列之十二]使用 nodejs通过async await建立同步数据抓取
做数据分析和可视化工作,最重要的一点就是数据抓取工作,之前使用Java和python都做过简单的数据抓取,感觉用的很不顺手. 后来用nodejs发现非常不错,通过js就可以进行数据抓取工作,类似jqu ...
- C# 微信 生活助手 空气质量 天气预报等 效果展示 数据抓取 (二)
此文主要是 中国天气网和中国环境监测总站的数据抓取 打算开放全部数据抓取源代码 已在服务器上 稳定运行半个月 webapi http://api.xuzhiheng.cn/ 常量 /// <su ...
- SNMP报文抓取与分析(二)
SNMP报文抓取与分析(二) SNMP报文抓取与分析(二) 1.SNMP报文表示简介 基本编码规则BER 标识域Tag表示 长度域length表示 2.SNMP报文详细分析(以一个get-respon ...
- 使用NodeJs,实现数据抓取
学习笔记 前言 近期做一个数据抓爬工具,最开始使用的是C#控制台应用,同时正则表达式去过滤数据,看着还行,可每次运行都依附于.net framework很是不爽,于是想整点其他的方法.本人还是比较喜欢 ...
- 数据抓取的艺术(一):Selenium+Phantomjs数据抓取环境配置
数据抓取的艺术(一):Selenium+Phantomjs数据抓取环境配置 2013-05-15 15:08:14 分类: Python/Ruby 数据抓取是一门艺术,和其他软件不同,世界上 ...
- python爬虫数据抓取方法汇总
概要:利用python进行web数据抓取方法和实现. 1.python进行网页数据抓取有两种方式:一种是直接依据url链接来拼接使用get方法得到内容,一种是构建post请求改变对应参数来获得web返 ...
随机推荐
- nginx android app 慢网络请求超时
最近遇到了android 在慢网络下面请求服务器报 java.net.SocketException: recvfrom failed: ECONNRESET (Connection reset by ...
- 【转贴】Python处理海量数据的实战研究
最近看了July的一些关于Java处理海量数据的问题研究,深有感触,链接:http://blog.csdn.net/v_july_v/article/details/6685962 感谢July ^_ ...
- Unity3d刚体Rigidbody与碰撞检测Collider
做了一个碰撞的小Demo,用一个球去撞击一堵墙,结果在球和墙都设置了刚体和碰撞体的情况下,球穿过了墙.移动球的位置,球有时能穿过墙,有时会被墙阻挡. 对于球穿过了墙,这个问题,在网上找了一下答案,基本 ...
- vue-cli 路由 实现类似tab切换效果(vue 2.0)
1,更改main.js 2,在App.vue中,写入两个跳转链接(router-link),分别跳转到"home""About" (home.About即分别是 ...
- Python之路【第二篇】python基础 之基本数据类型
运算符 1.算数运算: 2.比较运算: 3.赋值运算: 4.逻辑运算: 5.成员运算: name = "yehaoran " # in 判断ye是否在name里面 在的话返回ok ...
- Java学习【1】
一.Java 简介 Java是由Sun Microsystems公司于1995年5月推出的Java面向对象程序设计语言和Java平台的总称. 2005年6月,SUN公司公开Java SE 6.Java ...
- 移动端图片上传base64编码
$base64 = "/9j/4AAQSkZJRgABAQEAkACQAAD/4QCMRXhpZgAATU0AKgAAAAgABQESAAMAAAABAAEAAAEaAAUAAAABAAAA ...
- 使用Dotfuscator 进行.Net代码混淆 代码加密的方法
混淆代码能在一定程度上放置代码被盗用,保护我们的知识产权 1.打开vs2012,选择工具-〉Dotfuscator Software Services 2.选择你需要混淆的DLL 文件,可以多选择 3 ...
- IOS网络第七天WebView-01WebView和网页的交互1
******** #import "HMViewController.h" @interface HMViewController () <UIWebViewDelegate ...
- Eclipse搭建c环境(CDT)二
Eclipse 编辑c程序环境的搭建主要为其安装CDT插件即可 Eclipse搭建CDT步骤如下: 1.首先配置好java环境,为后续运行eclipse做准备 (略) 2.下载并安装eclipse(这 ...