CUDA学习(三)之使用GPU进行两个数组相加
传入两个数组,在GPU中将两个数组对应索引位置相加
#include "cuda_runtime.h"
#include "device_launch_parameters.h" #include <iomanip>
#include <iostream>
#include <stdio.h> using namespace std; //检测GPU
bool CheckCUDA(void){
int count = ;
int i = ; cudaGetDeviceCount(&count);
if (count == ) {
printf("找不到支持CUDA的设备!\n");
return false;
}
cudaDeviceProp prop;
for (i = ; i < count; i++) {
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= ) {
break;
}
}
}
if (i == count) {
printf("找不到支持CUDA的设备!\n");
return false;
}
cudaGetDeviceProperties(&prop, );
printf("GPU is: %s\n", prop.name);
cudaSetDevice();
printf("CUDA initialized success.\n");
return true;
}//使用一维数组相加
__global__ void addForOneDim(double *a, double *b, double *c, int N); //初始化一维数组
void InitOneDimArray(double *a, double b, int N); int main(){
//检测GPU
if (!CheckCUDA()){
cout << "No CUDA device.";
return ;
} //****数组相加************************************************************************************************************************
cout << "****************************************数组相加*********************************************************************" << endl;
int N = ; //定义数组大小
double *h_a_one, *h_b_one, *h_c_one; //声明在CPU上使用的指针
double *d_a_one, *d_b_one, *d_c_one; //声明在GPU上使用的指针
//为数组分配大小
h_a_one = new double[N];
h_b_one = new double[N];
h_c_one = new double[N]; cudaMalloc((void **)&d_a_one, sizeof(double)*N); //在GPU上分配内存空间
cudaMalloc((void **)&d_b_one, sizeof(double)*N);
cudaMalloc((void **)&d_c_one, sizeof(double)*N);
//为数组初始化
InitOneDimArray(h_a_one, 1.1, N);
InitOneDimArray(h_b_one, 2.2, N); //使用GPU中分配的指针指向CPU中的数组
cudaMemcpy(d_a_one, h_a_one, sizeof(double)*N, cudaMemcpyHostToDevice);
cudaMemcpy(d_b_one, h_b_one, sizeof(double)*N, cudaMemcpyHostToDevice); //调用核函数,使用1个线程块N个线程
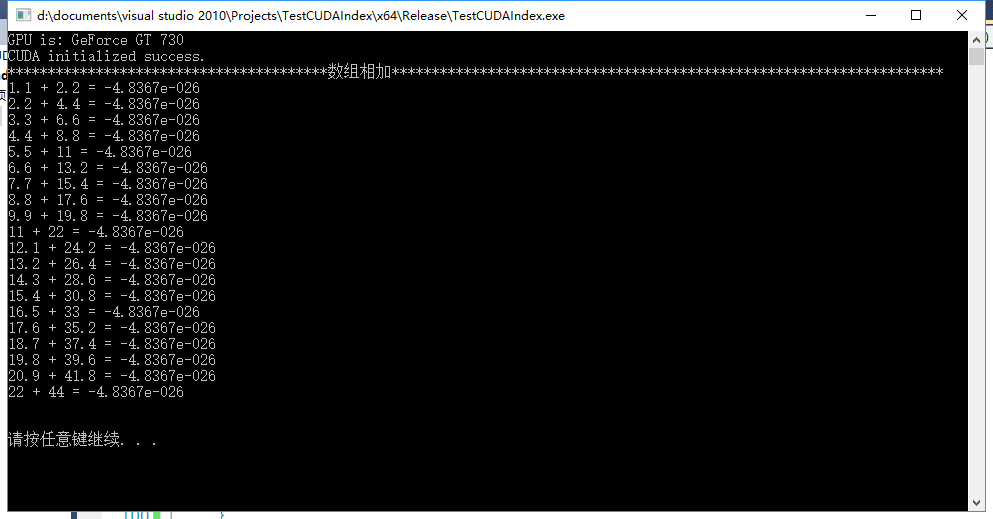
//addForOneDim<<<1, N>>>(h_a_one, h_b_one, d_c_one, N); //不能使用h_a_one和h_b_one,只能使用GPU上定义的指针,不然结果如图一所示
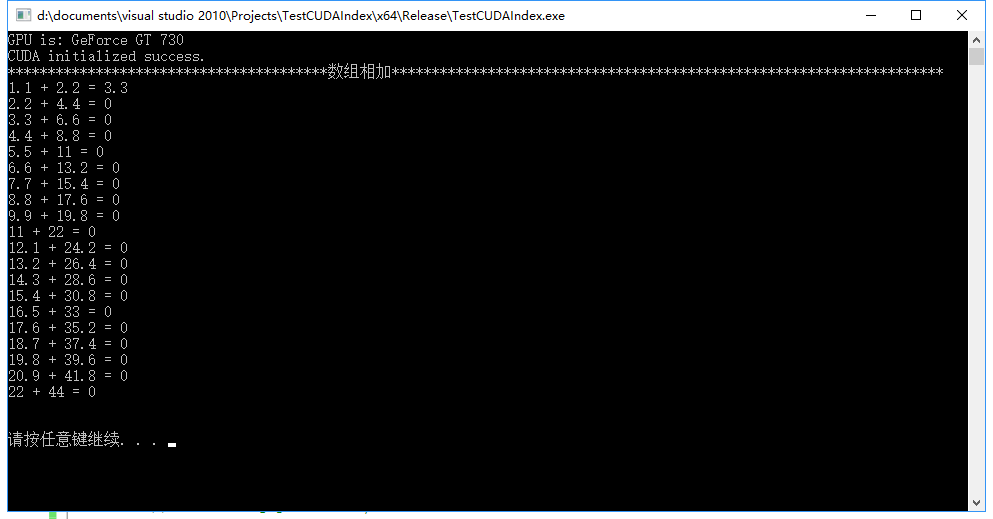
addForOneDim<<<, N>>>(d_a_one, d_b_one, d_c_one, N); //结果如图二所示
//调用核函数,使用N个线程块,每个线程块中包含1个线程
//addForOneDim<<<N, >>>(d_a_one, d_b_one, d_c_one, N); //结果如图三所示
//将GPU上计算好的结果返回到CPU上定义好的变量
cudaMemcpy(h_c_one, d_c_one, sizeof(double)*N, cudaMemcpyDeviceToHost); //打印结果
for (int i = ; i < N; i++){
cout << h_a_one[i] << " + " << h_b_one[i] << " = " << h_c_one[i] << endl;
} cout << endl << endl;
system("pause");
return ;
}
//使用一维数组相加
__global__ void addForOneDim(double *a, double *b, double *c, int N){
int tid = threadIdx.x; //线程索引,启用1个线程块,每个线程块N个线程
if (tid < N){
c[tid] = a[tid] + b[tid];
}
} //初始化一维数组
void InitOneDimArray(double *a, double b, int N){
for (int i = ; i < N; i++){
a[i] = (i+) * b;
//cout << a[i] << endl;
}
}
图一 (该图是错误的)
图二 (该图是正确的)

图三 (该图是错误的)当在调用核函数时,
addForOneDim<<<N, >>>(d_a_one, d_b_one, d_c_one, N);
使用的索引是
int tid = threadIdx.x; //对应的是一个线程块中每个线程id
正确的索引是
int tid = blockIdx.x; //对应的是每个线程块id
CUDA学习(三)之使用GPU进行两个数组相加的更多相关文章
- PHP两个数组相加
在PHP中,当两个数组相加时,会把第二个数组的取值添加到第一个数组上,同时覆盖掉下标相同的值: <?php $a = array("a" => "apple& ...
- PHP基础--两个数组相加
在PHP中,当两个数组相加时,会把第二个数组的取值添加到第一个数组上,同时覆盖掉下标相同的值: <?php $a = array("a" => "apple& ...
- PHP将两个数组相加
$arr_a=[1=>1,2=>2,3=>3];$arr_b=[1=>'a',4=>4];print_r($arr_a+$arr_b);返回结果:Array ( [1] ...
- OpenCL入门:(二:用GPU计算两个数组和)
本文编写一个计算两个数组和的程序,用CPU和GPU分别运算,计算运算时间,并且校验最后的运算结果.文中代码偏多,原理建议阅读下面文章,文中介绍了OpenCL相关名词概念. http://opencl. ...
- CUDA学习(三)之使用GPU进行两个数相加
在CPU上定义两个数并赋值,然后使用GPU核函数将两个数相加并返回到CPU,在CPU上显示 #include "cuda_runtime.h" #include "dev ...
- cuda学习3-共享内存和同步
为什么要使用共享内存呢,因为共享内存的访问速度快.这是首先要明确的,下面详细研究. cuda程序中的内存使用分为主机内存(host memory) 和 设备内存(device memory),我们在这 ...
- CUDA学习,第一个kernel函数及代码讲解
前一篇CUDA学习,我们已经完成了编程环境的配置,现在我们继续深入去了解CUDA编程.本博文分为三个部分,第一部分给出一个代码示例,第二部分对代码进行讲解,第三部分根据这个例子介绍如何部署和发起一个k ...
- CUDA学习笔记3:CUFFT(CUDA提供了封装好的CUFFT库)的使用例子
一.FFT介绍 傅里叶变换是数字信号处理领域一个很重要的数学变换,它用来实现将信号从时域到频域的变换,在物理学.数论.组合数学.信号处理.概率.统计.密码学.声学.光学等领域有广泛的应用.离散傅里叶变 ...
- CUDA学习之二:shared_memory使用,矩阵相乘
CUDA中使用shared_memory可以加速运算,在矩阵乘法中是一个体现. 矩阵C = A * B,正常运算时我们运用 C[i,j] = A[i,:] * B[:,j] 可以计算出结果.但是在CP ...
随机推荐
- eclipse中SSM(maven)项目搭建全过程+实现用户登录功能
项目创建之前确保eclipse中已经配置好了jdk,tomcat,maven如果没有配置下面有配置教程的链接 eclipse中配置jdk的教程url:http://www.cnblogs.com/ ...
- appium启动app(ios)
Appium启动APP至少需要7个参数 'platformVersion','deviceName'.'udid'.'bundleId'.'platformName'.'automationNam ...
- 浅谈Java中接口与抽象类的异同
浅谈Java中接口与抽象类的异同 抽象类和接口这两个概念困扰了我许久,在我看来,接口与抽象类真的十分相似.期间也曾找过许许多多的资料,参考了各路大神的见解,也只能是简简单单地在语法上懂得两者的区别.硬 ...
- [UWP]XAML中的响应式布局技术
响应式布局的概念是一个页面适配多个终端及不同分辨率.在针对特定屏幕宽度优化应用 UI 时,我们将此称为创建响应式设计.WPF设计之初响应式设计的概念并不流行,那时候大部分网页设计师都按着宽度960像素 ...
- Go指针,如此轻松掌握,希望有收获
开篇语 依稀记得大学必修课,C语言中的指针,简直是噩梦,指来指去,有没有晕乎乎的感觉,我在想是不是也因为如此,所以Java语言的开发者C才比C语言的多,Java正因为解决了C的痛点,所以今天才能变成语 ...
- 再也不怕和老外交流了!我用python实现一个微信聊天翻译助手!
前言 在前面的一篇文章如何用python“优雅的”调用有道翻译中咱们清楚的写过如何一层一层的解开有道翻译的面纱,并且笔者说过那只是脑洞的开始.现在笔者又回来了.当你遇到一些外国小哥哥小姐姐很心动.想结 ...
- 你真的看懂Android事件分发了吗?
引子 Android事件分发其实是老生常谈了,但是说实话,我觉得很多人都只是懂其大概,模棱两可.本文的目的就是再次从源码层次梳理一下,重点放在ViewGroup的dispatchTouchEvent方 ...
- 【转】7本免费的Java电子书和教程
本文由 ImportNew - 唐小娟 翻译自 Javapapers.如需转载本文,请先参见文章末尾处的转载要求. 1. Thinking in Java (Third Edition) 本书的作者是 ...
- TensorFlow——Graph的基本操作
1.创建图 在tensorflow中,一个程序默认是建立一个图的,除了系统自动建立图以外,我们还可以手动建立图,并做一些其他的操作. 下面我们使用tf.Graph函数建立图,使用tf.get_defa ...
- java开源工作流引擎jflow的流程应用类型分类讲解
关键字: 驰骋工作流程快速开发平台 工作流程管理系统 工作流引擎 asp.net工作流引擎 java工作流引擎. 开发者表单 拖拽式表单 工作流系统CCBPM节点访问规则接收人规则 适配数据库: o ...