CUDA学习(三)之使用GPU进行两个数组相加
传入两个数组,在GPU中将两个数组对应索引位置相加
#include "cuda_runtime.h"
#include "device_launch_parameters.h" #include <iomanip>
#include <iostream>
#include <stdio.h> using namespace std; //检测GPU
bool CheckCUDA(void){
int count = ;
int i = ; cudaGetDeviceCount(&count);
if (count == ) {
printf("找不到支持CUDA的设备!\n");
return false;
}
cudaDeviceProp prop;
for (i = ; i < count; i++) {
if (cudaGetDeviceProperties(&prop, i) == cudaSuccess) {
if (prop.major >= ) {
break;
}
}
}
if (i == count) {
printf("找不到支持CUDA的设备!\n");
return false;
}
cudaGetDeviceProperties(&prop, );
printf("GPU is: %s\n", prop.name);
cudaSetDevice();
printf("CUDA initialized success.\n");
return true;
}//使用一维数组相加
__global__ void addForOneDim(double *a, double *b, double *c, int N); //初始化一维数组
void InitOneDimArray(double *a, double b, int N); int main(){
//检测GPU
if (!CheckCUDA()){
cout << "No CUDA device.";
return ;
} //****数组相加************************************************************************************************************************
cout << "****************************************数组相加*********************************************************************" << endl;
int N = ; //定义数组大小
double *h_a_one, *h_b_one, *h_c_one; //声明在CPU上使用的指针
double *d_a_one, *d_b_one, *d_c_one; //声明在GPU上使用的指针
//为数组分配大小
h_a_one = new double[N];
h_b_one = new double[N];
h_c_one = new double[N]; cudaMalloc((void **)&d_a_one, sizeof(double)*N); //在GPU上分配内存空间
cudaMalloc((void **)&d_b_one, sizeof(double)*N);
cudaMalloc((void **)&d_c_one, sizeof(double)*N);
//为数组初始化
InitOneDimArray(h_a_one, 1.1, N);
InitOneDimArray(h_b_one, 2.2, N); //使用GPU中分配的指针指向CPU中的数组
cudaMemcpy(d_a_one, h_a_one, sizeof(double)*N, cudaMemcpyHostToDevice);
cudaMemcpy(d_b_one, h_b_one, sizeof(double)*N, cudaMemcpyHostToDevice); //调用核函数,使用1个线程块N个线程
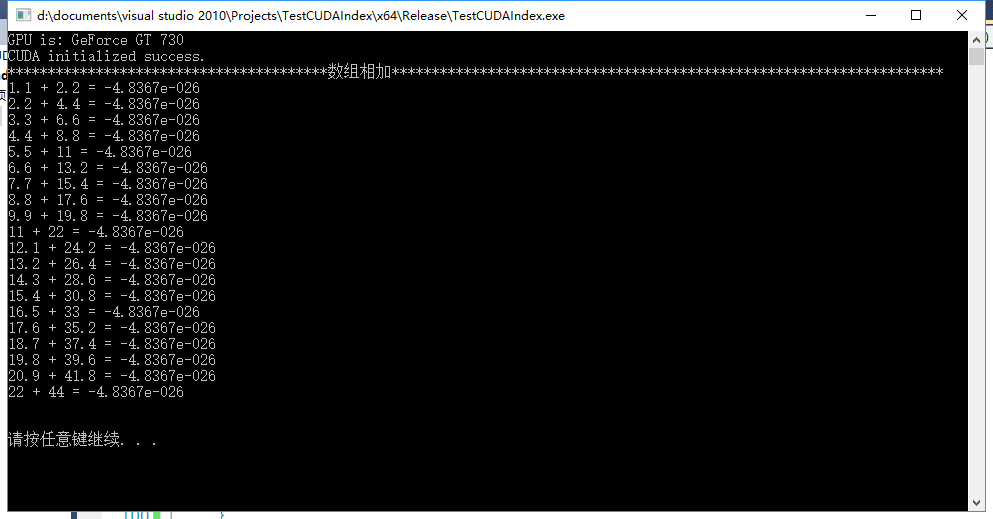
//addForOneDim<<<1, N>>>(h_a_one, h_b_one, d_c_one, N); //不能使用h_a_one和h_b_one,只能使用GPU上定义的指针,不然结果如图一所示
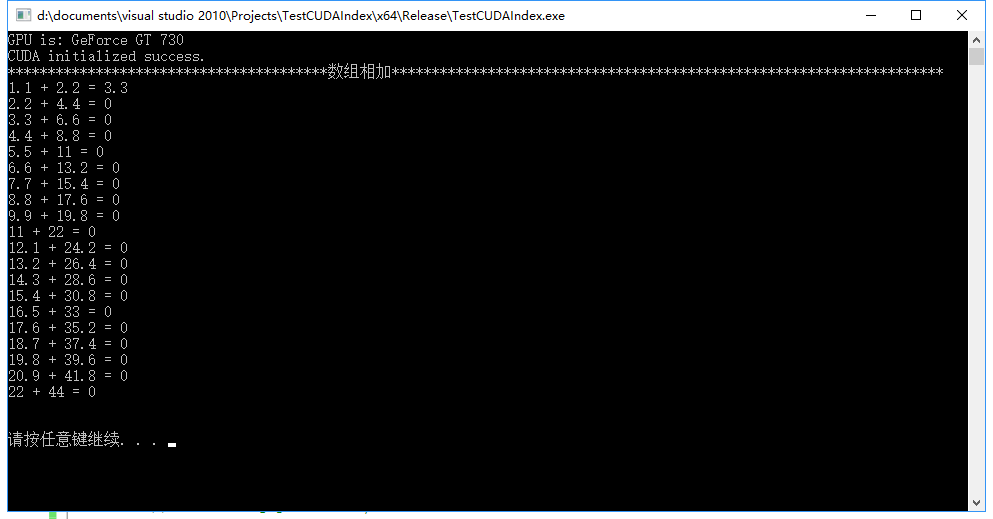
addForOneDim<<<, N>>>(d_a_one, d_b_one, d_c_one, N); //结果如图二所示
//调用核函数,使用N个线程块,每个线程块中包含1个线程
//addForOneDim<<<N, >>>(d_a_one, d_b_one, d_c_one, N); //结果如图三所示
//将GPU上计算好的结果返回到CPU上定义好的变量
cudaMemcpy(h_c_one, d_c_one, sizeof(double)*N, cudaMemcpyDeviceToHost); //打印结果
for (int i = ; i < N; i++){
cout << h_a_one[i] << " + " << h_b_one[i] << " = " << h_c_one[i] << endl;
} cout << endl << endl;
system("pause");
return ;
}
//使用一维数组相加
__global__ void addForOneDim(double *a, double *b, double *c, int N){
int tid = threadIdx.x; //线程索引,启用1个线程块,每个线程块N个线程
if (tid < N){
c[tid] = a[tid] + b[tid];
}
} //初始化一维数组
void InitOneDimArray(double *a, double b, int N){
for (int i = ; i < N; i++){
a[i] = (i+) * b;
//cout << a[i] << endl;
}
}
图一 (该图是错误的)
图二 (该图是正确的)

图三 (该图是错误的)当在调用核函数时,
addForOneDim<<<N, >>>(d_a_one, d_b_one, d_c_one, N);
使用的索引是
int tid = threadIdx.x; //对应的是一个线程块中每个线程id
正确的索引是
int tid = blockIdx.x; //对应的是每个线程块id
CUDA学习(三)之使用GPU进行两个数组相加的更多相关文章
- PHP两个数组相加
在PHP中,当两个数组相加时,会把第二个数组的取值添加到第一个数组上,同时覆盖掉下标相同的值: <?php $a = array("a" => "apple& ...
- PHP基础--两个数组相加
在PHP中,当两个数组相加时,会把第二个数组的取值添加到第一个数组上,同时覆盖掉下标相同的值: <?php $a = array("a" => "apple& ...
- PHP将两个数组相加
$arr_a=[1=>1,2=>2,3=>3];$arr_b=[1=>'a',4=>4];print_r($arr_a+$arr_b);返回结果:Array ( [1] ...
- OpenCL入门:(二:用GPU计算两个数组和)
本文编写一个计算两个数组和的程序,用CPU和GPU分别运算,计算运算时间,并且校验最后的运算结果.文中代码偏多,原理建议阅读下面文章,文中介绍了OpenCL相关名词概念. http://opencl. ...
- CUDA学习(三)之使用GPU进行两个数相加
在CPU上定义两个数并赋值,然后使用GPU核函数将两个数相加并返回到CPU,在CPU上显示 #include "cuda_runtime.h" #include "dev ...
- cuda学习3-共享内存和同步
为什么要使用共享内存呢,因为共享内存的访问速度快.这是首先要明确的,下面详细研究. cuda程序中的内存使用分为主机内存(host memory) 和 设备内存(device memory),我们在这 ...
- CUDA学习,第一个kernel函数及代码讲解
前一篇CUDA学习,我们已经完成了编程环境的配置,现在我们继续深入去了解CUDA编程.本博文分为三个部分,第一部分给出一个代码示例,第二部分对代码进行讲解,第三部分根据这个例子介绍如何部署和发起一个k ...
- CUDA学习笔记3:CUFFT(CUDA提供了封装好的CUFFT库)的使用例子
一.FFT介绍 傅里叶变换是数字信号处理领域一个很重要的数学变换,它用来实现将信号从时域到频域的变换,在物理学.数论.组合数学.信号处理.概率.统计.密码学.声学.光学等领域有广泛的应用.离散傅里叶变 ...
- CUDA学习之二:shared_memory使用,矩阵相乘
CUDA中使用shared_memory可以加速运算,在矩阵乘法中是一个体现. 矩阵C = A * B,正常运算时我们运用 C[i,j] = A[i,:] * B[:,j] 可以计算出结果.但是在CP ...
随机推荐
- SpringJDBC的使用(转载)
转载自 https://www.yiibai.com/spring/maven-spring-jdbc-example.html 工具: eclipse4.7.2及mysql-8.0.13 项目最 ...
- IDEA启动报错Internal error. Please report to http://jb.gg/ide/critical-startup-errors java.lang.NoClassDefFoundError: org/eclipse/xtext/xbase/lib/Exceptions
报错内容: IDEA 启动报错 Internal error. Please report to http://jb.gg/ide/critical-startup-errors 报错图为: 我尝试找 ...
- Linux中du、df显示不一致问题
Linux中du.df显示不一致问题 最近在做关于Q博士的项目的时候,用到了docker进行部署,对于后端服务可能会经常变动,于是将docker容器的jar包与宿主机目录下的jar包进行绑定,之后每次 ...
- 使用SqlDependency实时监听SQL server数据库变化并执行事件
sql server设置:ALTER DATABASE <DatabaseName> SET ENABLE_BROKER;语句让相应的数据库启用监听服务,以便支持SqlDependency ...
- Helm, 在Kubernetes中部署应用的利器
一.背景 Kubernetes(k8s)是一个基于容器技术的分布式架构领先方案.它在Docker技术的基础上,为容器化的应用提供部署运行.资源调度.服务发现和动态伸缩等一系列完整功能,提高了大规模容器 ...
- postman传递当前时间戳
有时我们在请求接口时,需要带上当前时间戳这种动态参数,那么postman能不能自动的填充上呢. 1请求动态参数(例如时间戳) 直接在参数值写 {{$timestamp}} 如下: 我们也可以使用pos ...
- cogs 1829. [Tyvj 1728]普通平衡树 权值线段树
1829. [Tyvj 1728]普通平衡树 ★★★ 输入文件:phs.in 输出文件:phs.out 简单对比时间限制:1 s 内存限制:1000 MB [题目描述] 您需要写一种数 ...
- scala基本语法
scala基本语法scala函数1 def定义方法2 方法的返回值类型可以省略3 方法体重最后一行计算结果可以返回 return 如果省略方法类型4 方法参数 要指定类型5 如果方法体可以一步搞定 方 ...
- 幽灵java进程引起的: FATAL ERROR in native method
FATAL ERROR in native method: JDWP No transports initialized, jvmtiError=AGENT_ERROR_TRANSPORT_INIT( ...
- 常用crud
增:@Insert("insert into t_user (`last_name`, `sex`) values(#{lastName}, #{sex})") 删:@Del ...