Flink架构(二)- Flink中的数据传输
2. Flink中的数据传输
在一个运行的application中,它的tasks在持续交换数据。TaskManager负责做数据传输。TaskManager的网络组件首先从缓冲buffer中收集records,然后再发送。也就是说,records并不是一个接一个的发送,而是先放入缓冲,然后再以batch的形式发送。这个技术可以高效使用网络资源,并达到高吞吐。类似于网络或磁盘 I/O 协议中使用的缓冲技术。
这里需要注意的是:传输缓冲buffer中的记录,隐含表示的是,Flink的处理模型是基于微批处理的。
每个TaskManager有一组网络缓冲池(默认每个buffer是32KB),用于发送与接受数据。如发送端和接收端位于不同的TaskManager进程中,则它们需要通过操作系统的网络栈进行交流。流应用需要以管道的模式进行数据交换,也就是说,每对TaskManager会维持一个永久的TCP连接用于做数据交换。在shuffle连接模式下(多个sender与多个receiver),每个sender task需要向每个receiver task,此时TaskManager需要为每个receiver task都分配一个缓冲区。下图展示了此架构:
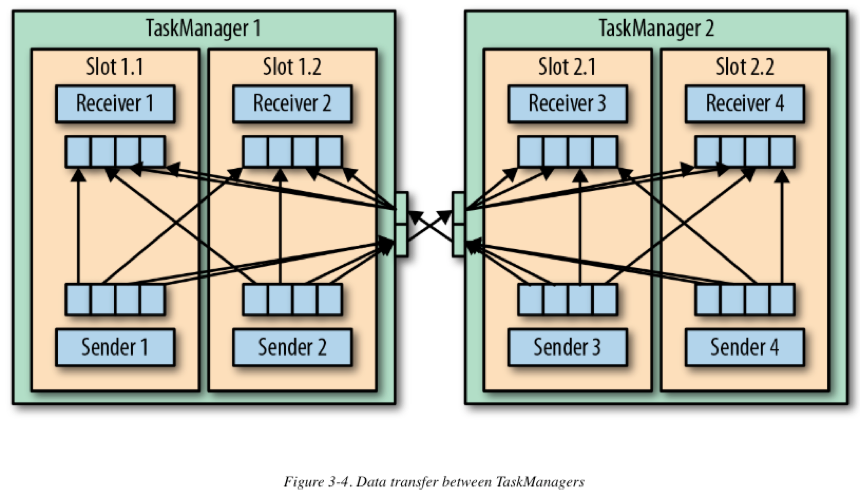
在上图中,有四个sender 任务,对于每个sender,都需要有至少四个network buffer用于向每个receiver发送数据。每个receiver都需要有至少四个buffer用于接收数据。TaskManager之间的buffer以多路复用的方式使用同一网络连接。为了提供平滑的数据管道型的数据交换,一个TaskManager必须能提供足够的缓冲,以服务所有并行的出入连接。对于shuffle或broadcast 连接,每个发送任务和每个接受任务之间都需要一个buffer。Flink的默认网络缓冲配置足够适用与小型与中型的集群任务。对于大型的集群任务,需要对此配置进行调优。
若sender与receiver任务都运行在同一个TaskManager进程,则sender任务会将发送的条目做序列化,并存入一个字节缓冲。然后将缓冲放入一个队列,直到队列被填满。Receiver任务从队列中获取缓冲,并反序列化输入的条目。所以,在同一个TaskManager内,任务之间的数据传输并不经过网络交互。
Flink采用了不同的技术用于减少tasks之间的沟通成本。在接下来的部分中,我们会讨论基于积分的(credit-based )流控制与任务链(task chaining)。
基于积分的(Credit-Based )流控制
通过网络发送单独的条目是一个并不高效的方式,并且会造成大量负载。使用缓冲技术可以更好的使用网络连接的带宽。在流处理场景中,缓冲的一个缺点是:它增加了延时,因为records需要先放入缓冲,而不是被立即传输。
Flink实现了一个credit-based 流控制机制,工作方式为:一个接收任务会授权给一个发送任务一些积分(credit),用于控制预留的缓冲区个数。当一个sender接收到了积分通知,它向会receiver发送 buffers(最多不超过被授权的数量)以及它的backlog大小(已经充满了并等待被发送的buffer数量)。Receiver使用预留的buffer处理接收到的数据,并使用sender的backlog大小作为下一次授权的积分数,提供给所有与它连接的senders。
Credit-based 流控制减少了延时,因为senders可以在receiver有足够的资源接受数据时,尽快向它发送数据。它在Flink中是一个重要的部分,助力Flink达到高吞吐与低延时。
任务链(task chaining)
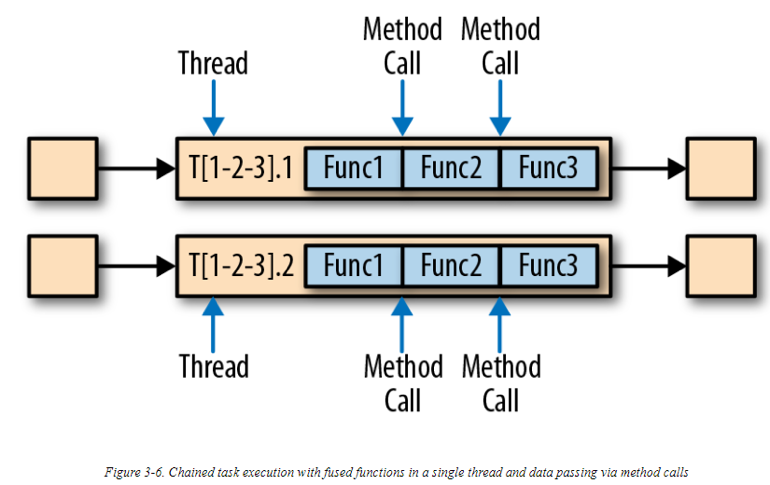
Flink另一个优化技术称为任务链,用于(在某些情况下)减少本地通信的过载。为了满足任务链的条件,至少两个以上的operator必须配置为同一并行度,并且使用本地向前的(local forwad)方式连接。下图的operator管道即满足这些条件。它包含3个operators,全部被配置为并行度为2,并且以local-forward的方式连接:

下图描述了管道是如何以任务链的方式执行的。Operators的函数被融合成单个任务,并由一个单独的线程执行。一个function产生的records,通过使用一个简单的方法调用,被递交给下一个function。所以,这里在方法之间的records传递中,基本没有序列化以及通信消耗。
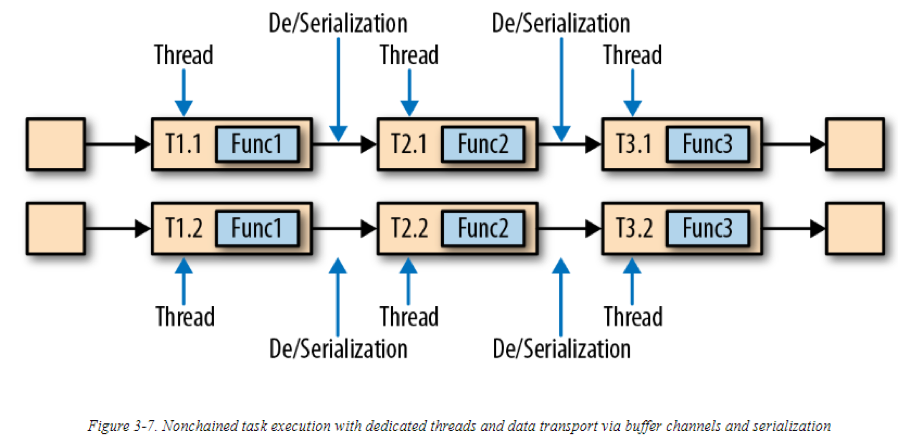
任务链可以极大减少本地task之间的通信成本,但是有时候在执行一个管道时,不使用任务链也是合理的。例如,将一个包含多个链式任务的长管道断开,或是将一个链分成两个任务,并将较为消耗资源的function调度到另一个slot上。这些都是合理的。下图描绘了同样一个执行的管道,但未使用任务链。所有function由一个单独的task,在它自身的线程中运行。
任务链默认是开启的。在“控制任务链”一节,我们会介绍如何为某个任务关闭任务链化,以及如何控制单个operator的链行为。
References:
Vasiliki Kalavri, Fabian Hueske. Stream Processing With Apache Flink. 2019
Flink架构(二)- Flink中的数据传输的更多相关文章
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Flink架构、原理与部署测试(转)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Flink架构,源码及debug
序 工作中用Flink做批量和流式处理有段时间了,感觉只看Flink文档是对Flink ProgramRuntime的细节描述不是很多, 程序员还是看代码最简单和有效.所以想写点东西,记录一下,如果能 ...
- 3、flink架构,资源和资源组
一.flink架构 1.1.集群模型和角色 如上图所示:当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager.由 Client 提交任务给 JobMa ...
- flink架构介绍
前言 flink作为基于流的大数据计算引擎,可以说在大数据领域的红人,下面对flink-1.7的架构进行逻辑上的分析并和spark做了一些关键点的对比. 架构 如图1,flink架构分为3个部分,cl ...
- Flink架构分析之Standalone模式启动流程
概述 FLIP6 对Flink架构进行了改进,引入了Dispatcher组件集成了所有任务共享的一些组件:SubmittedJobGraphStore,LibraryCacheManager等,为了保 ...
- Apache Flink vs Apache Spark——感觉二者是互相抄袭啊 看谁的好就抄过来 Flink支持在runtime中的有环数据流,这样表示机器学习算法更有效而且更有效率
Apache Flink是什么 Flink是一款新的大数据处理引擎,目标是统一不同来源的数据处理.这个目标看起来和Spark和类似.没错,Flink也在尝试解决 Spark在解决的问题.这两套系统都在 ...
- Flink架构和调度
1.Flink架构 Flink系统的架构与Spark类似,是一个基于Master-Slave风格的架构,如下图所示: Flink集群启动时,会启动一个JobManager进程.至少一个TaskMana ...
随机推荐
- xctf进阶-unserialize3反序列化
一道反序列化题: 打开后给出了一个php类,我们可以控制code值: `unserialize()` 会检查是否存在一个 `__wakeup()` 方法.如果存在,则会先调用 `__wakeup` 方 ...
- IO流学习之字符流(三)
IO流之字符流缓冲区: 概念: 流中的缓冲区:是先把程序需要操作的数据保存在内存中,然后我们的程序读写数据的时候,不直接和持久设备之间交互,而改成和内存中的数据进行交互. 缓冲区:它就是临时存储数据, ...
- docker下载镜像太慢的解决方案
参考链接:https://blog.csdn.net/weixin_43569697/article/details/89279225 docker下载镜像卡死或太慢找了网上很多方法,使用镜像中国也是 ...
- vue自学入门-7(vue style scope)
vue自学入门-1(Windows下搭建vue环境) vue自学入门-2(vue创建项目) vue自学入门-3(vue第一个例子) vue自学入门-4(vue slot) vue自学入门-5(vuex ...
- Git和TortoiseGit
1.简介 Git是一个开源的分布式版本控制系统,用于敏捷高效的处理任何或大或小的项目.它采用了分布式版本库的方式,不必服务器端软件支持. 2.Git和Svn的区别 1.Git 是分布式的,SVN 不是 ...
- C# GZip Compress DeCompress
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- SYZOJP186 你猜猜是不是DP 二分+hash解法
SYZOJP186 你猜猜是不是DP题解 题目传送门 现在给两个仅包含小写字母的字符串a,b ,求a 与b的最长公共连续子串的长度. 对于20%的数据,a,b长度 ∈ [1, 200] 对于50%的数 ...
- Spark学习之路 (二)Spark2.3 HA集群的分布式安装[转]
下载Spark安装包 从官网下载 http://spark.apache.org/downloads.html 从微软的镜像站下载 http://mirrors.hust.edu.cn/apache/ ...
- 854. Floyd求最短路(模板)
给定一个n个点m条边的有向图,图中可能存在重边和自环,边权可能为负数. 再给定k个询问,每个询问包含两个整数x和y,表示查询从点x到点y的最短距离,如果路径不存在,则输出“impossible”. 数 ...
- SVN之TortoiseSVN使用02
TortoiseSVN常用操作和安装eclipse的svn插件 一.关于TortoiseSVN的介绍 1. 安装TortoiseSVN图像化操作软件,便于操作SVN! 如图有两种版本的,一个是32位, ...