KNN与决策树
KNN:
就是计算特征之间的距离,某一个待预测的数据分别与已知的所有数据计算他们之间的特征距离,选出前N个距离最近的数据,这N个数据中哪一类的数据最多,就判定待测数据归属哪一类。
 假如N=3,图中待测圆就属于个数最多那个:三角类
假如N=3,图中待测圆就属于个数最多那个:三角类
总结:
1、KNN是分类数据最简单最有效的算法
2、缺点就是存储空间消耗大,计算耗时。
决策树:
信息增益:划分数据集之前之后信息发生的变化叫做信息增益。
信息公式:
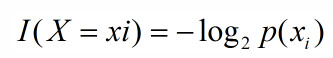
熵:信息的期望值(熵越高也就是数据混合数据越多,杂乱程度越大)
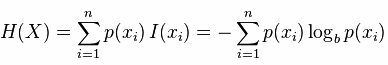
算法思想:选择最好信息增益最大的属性也就是熵最小的特征
注意:特征和特征值的区别,一个特征有几个特征值。比如:性别特征有男、女两个特征值。
算法过程:
1、先计算划分数据前的熵(主要是计算类的概率,然后求熵)
2、然后根据特征进行划分数据集,计算划分后的数据熵(根据特征的每一个特征值划分数据,可以计算每一个特征值的信息,最后可以计算特征的熵)
3、划分前的数据熵减去划分后的熵得到信息增益,选择使数据信息增益最大的那个特征,也就是最好的划分特征。
4、重复2、3(形成一棵树)最后将数据分类成功。(每一个叶子结点代表一个类)
总结:
1、速度快,容易理解,适合高纬度。
2、容易过拟合,由于训练数据中存在噪音数据,决策树的某些节点有噪音数据作为分割标准,导致决策树无法代表真实数据。
KNN与决策树的更多相关文章
- # 机器学习算法总结-第一天(KNN、决策树)
KNN算法总结 KNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别.(监督) k近邻算法(knn)是一种基本的分类与回归的算法,k-mea ...
- 2019-08-01【机器学习】有监督学习之分类 KNN,决策树,Nbayes算法实例 (人体运动状态信息评级)
样本: 使用的算法: 代码: import numpy as np import pandas as pd import datetime from sklearn.impute import Sim ...
- 编程英语之KNN算法
School of Computer Science The University of Adelaide Artificial Intelligence Assignment 2 Semes ...
- 【机器学习】k近邻算法(kNN)
一.写在前面 本系列是对之前机器学习笔记的一个总结,这里只针对最基础的经典机器学习算法,对其本身的要点进行笔记总结,具体到算法的详细过程可以参见其他参考资料和书籍,这里顺便推荐一下Machine Le ...
- Atiti attilax主要成果与解决方案与案例rsm版 v4
Atiti attilax主要成果与解决方案与案例rsm版 v4 版本历史记录1 1. ##----------主要成果与解决方案与 参与项目1 ###开发流程与培训系列1 #-----组织运营与文 ...
- Python学习路径和个人增值(整合版)
PS:内容来源于网络 一.简介 Python是一种面向对象.直译式计算机程序设计语言,由Guido van Rossum于1989年底发明.由于他简单.易学.免费开源.可移植性.可扩展 ...
- opencv3.1自带demo的介绍和运行操作。转载
opencv3.1自带demo的介绍和运行操作. 下列实验基本都试过,有些需要根据自己的电脑修改一些路径或者调试参数. 值得注意的是,控制台程序输入有时候要在图像所在的窗口输入相应的指令.我的电脑上安 ...
- R语言与分类算法的绩效评估(转)
关于分类算法我们之前也讨论过了KNN.决策树.naivebayes.SVM.ANN.logistic回归.关于这么多的分类算法,我们自然需要考虑谁的表现更加的优秀. 既然要对分类算法进行评价,那么我们 ...
- Adaboost总结
一.简介 Boosting 是一类算法的总称,这类算法的特点是通过训练若干弱分类器,然后将弱分类器组合成强分类器进行分类.为什么要这样做呢?因为弱分类器训练起来很容易,将弱分类器集成起来,往往可以得到 ...
随机推荐
- hive UDAF开发和运行全过程
介绍 hive的用户自定义聚合函数(UDAF)是一个很好的功能,集成了先进的数据处理.hive有两种UDAF:简单和通用.顾名思义,简单的UDAF,写的相当简单的,但因为使用Java反射导致性能损失, ...
- 一些DP杂题
1. [HNOI2001] 产品加工 一道简单的背包,然而我还是写了很久QAQ 时间范围是都小于5 显然考虑一维背包,dp[i]表示目前A消耗了i的最小B消耗 注意 if(b[i]) dp[j]=dp ...
- Jquery轻量级插件--操作URL
调用: > "?action=view§ion=info&id=123&debug&testy[]=true&testy[]=false ...
- 搜索引擎优化 TF_IDF之Java实现
实现之前,我们要事先说明一些问题: 我们用Redis对数据进行持久化,存两种形式的MAP: key值为term,value值为含有该term的urlkey值为url,value值为map,记录term ...
- 5. Jmeter常用快捷键
快捷键 功能 备注 Ctrl + C 复制 可复制组件 Ctrl + V 粘贴 可粘贴组件 Ctrl + Shift + C 复制粘贴当前组件到下一行 Ctrl + R 运行测试计划 Ctrl ...
- PAT_A1041#Be Unique
Source: PAT A1041 Be Unique (20 分) Description: Being unique is so important to people on Mars that ...
- 数据挖掘Aprior算法详解及c++源码
[算法大致描述] Aprior算法主要有两个操作,扫描数据库+统计.计算每一阶频繁项集都要扫描一次数据库并且统计出满足支持度的n阶项集. [算法主要步骤] 一.频繁一项集 算法开始第一步,通过扫描数据 ...
- vscode eslint插件对vue文件无效
vscode配置好了之后,只对.js文件提示 vue文件没有效果 改成如下配置就好了. "eslint.validate": [ "javascript", & ...
- UncategorizedSQLException异常处理办法
如题,先贴console org.springframework.jdbc.UncategorizedSQLException: StatementCallback; uncategorized SQ ...
- pytest-文件名类名方法名执行部分用例
pytest test_class_01.py 执行文件名 pytest -v -s test_class_01.py 执行文件名 pytest -v test_class_01.py::TestCl ...