kafka集群搭建文档
kafka集群搭建文档
一. 下载解压
从官网下载Kafka,下载地址http://kafka.apache.org/downloads.html
注意这里最好下载scala2.10版本的kafka,因为scala2.10版本的兼容性比较好和2.11版本差别太大

通过命令 tar –zxvf kafka_2.10-0.9.0.1.tgz解压
二.配置启动
配置config/server.properties
配置broker.id从0开始,后面其他节点配置1,2,3,4等等

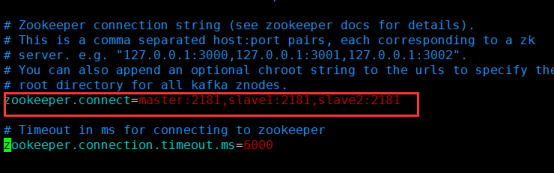
事先启动zookeeper集群,这里配置zookeeper集群的地址
zookeeper.connect=master:2181,slave1:2181,slave2:2181
将集群分发到其他机器,比如
scp -r kafka_2.10-0.9.0.1 root@slave1:/opt/sxt/soft/
scp -r kafka_2.10-0.9.0.1 root@slave2:/opt/sxt/soft/
这里注意修改broker.id


修改完配置以后在每个节点启动kafka
bin/kafka-server-start.sh config/server.properties
三.测试
新建一个topic
./bin/kafka-topics.sh -zookeeper master:2181,slave1:2181,slave2:2181 -topic test -replication-factor 2 -partitions 5 –create
查看当前的topic
./bin/kafka-topics.sh -zookeeper master:2181,slave1:2181,slave2:2181 -list

在一个节点创建一个provider
./bin/kafka-console-producer.sh --broker-list master:9092,slave1:9092,slave2:9092 --topic test
在另外一个节点创建一个consumer
./bin/kafka-console-consumer.sh --zookeeper master:2181,slave1:2181,slave2:2181 --from-beginning -topic test
在provider输入信息,在consumer能接收到信息


kafka集群搭建文档的更多相关文章
- kafka集群部署文档(转载)
原文链接:http://www.cnblogs.com/luotianshuai/p/5206662.html Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候 ...
- Hadoop集群搭建文档
环境: Win7系统装虚拟机虚拟机VMware-workstation-full-9.0.0-812388.exe Linux系统Ubuntu12.0.4 JDK j ...
- Ambari HDP集群搭建文档
一.配置主机和节点机器之间SSH无密登录 多台外网服务器配置时,需要在/etc/hosts中把本机的IP地址设置为内网IP地址 http://2d67df38.wiz02.com/share/s/0J ...
- Kafka【第一篇】Kafka集群搭建
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- Zookeeper + Kafka 集群搭建
第一步:准备 1. 操作系统 CentOS-7-x86_64-Everything-1511 2. 安装包 kafka_2.12-0.10.2.0.tgz zookeeper-3.4.9.tar.gz ...
- 【转】kafka集群搭建
转:http://www.cnblogs.com/luotianshuai/p/5206662.html Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否 ...
- redis多机集群部署文档
redis多机集群部署文档(centos6.2) (要让集群正常工作至少需要3个主节点,在这里我们要创建6个redis节点,其中三个为主节点,三个为从节点,对应的redis节点的ip和端口对应关系如下 ...
- zookeeper与Kafka集群搭建及python代码测试
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- kafka集群搭建和使用Java写kafka生产者消费者
1 kafka集群搭建 1.zookeeper集群 搭建在110, 111,112 2.kafka使用3个节点110, 111,112 修改配置文件config/server.properties ...
随机推荐
- 16-Ubuntu-文件和目录命令-切换目录-cd
cd(change directory),其功能为更改当前的工作目录. 注意:Linux所有的目录和文件名都是大小写敏感的. 命令 含义 cd 切换到当前用户的主目录(/home/用户目录) ...
- 树形结构_红黑树:平衡2X 哈夫曼树:最优2X
红黑树:平衡2X 哈夫曼树:最优2X 红黑树 :TreeSet.TreeMap 哈夫曼树 1. 将w1.w2.…,wn看成是有n 棵树的森林(每棵树仅有一个结点): 2. 在森林中选出根结点的权值最小 ...
- 添加ASP.NET AJAX控件工具集到VS2010的方法
在VS2010中Ajax控件只有5个,其实还有很多支持AJAX特定功能的服务器控件,微软是将这些控件当作开放源代码项目.所以没有集成到VS2010中.这些AJAX控件被称为ASP.NET AJAX控件 ...
- smb中继攻击
一.NTLM hash 和 Net-NTLM hash 1.客户端向服务器发送一个请求,请求中包含明文的登录用户名.服务器会提前保存登录用户名和对应的密码 hash 2.服务器接收到请求后,生成一个 ...
- 数据库MySQL--联合查询
应用场景:当要查询的结果来自多个表,且多个表没有直接的连接关系,但查询的信息一致时 语法: 查询语句1 union(all) 查询语句2 union(all) ..... 注:多条查询语句的查询列数要 ...
- Docker的镜像 导出导入
查看当前已经安装的镜像 vagrant@vagrant:~$ sudo docker images REPOSITORY TAG IMAGE ID CREATED SIZE mysql 5.7.22 ...
- 微服务配置中心实战:Spring + MyBatis + Druid + Nacos
在结合场景谈服务发现和配置中我们讲述了 Nacos 配置中心的三个典型的应用场景,包括如何在 Spring Boot 中使用 Nacos 配置中心将数据库连接信息管控起来,而在“原生”的 Spring ...
- excel导入、下载功能
1.excel导入.下载功能 2.首先,我们是居于maven项目进行开发引入poi,如果不是那就手动下载相应的jar包引入项目就可以了 <!-- poi --> <dependenc ...
- hibernate_04_hibernate多对多的关系映射
1.实体类的多对多的关系映射 一个用户可以有多个角色 User.java public class User { private Long user_id; private String user_c ...
- (2)python tkinter-按钮.标签.文本框、输入框
按钮 无功能按钮 Button的text属性显示按钮上的文本 tkinter.Button(form, text='hello button').pack() 无论怎么变幻窗体大小,永远都在窗体的最上 ...