全文检索以及Lucene的应用
全文检索
一.什么是全文检索?
就是在检索数据,数据的分类:
在计算机当中,比如说存在磁盘的文本文档,HTML页面,Word文档等等......
1.结构化数据
格式固定,长度固定,数据类型固定等等,我们称之为结构化数据,比如说数据库中的数据
2.非结构化数据
word文档,HTML文件,pdf文档,文本文档等等,格式不固定,长度不固定,数据类型不固定,成为非结构化数据
3.半结构化数据
二.数据的查询
1.结构化数据查询
结构化数据查询语言:SQL语句 select * from user where userid=1
2.非结构化数据的查询
非结构化数据查询有一些难度,比如我们在一个文本文件当中找到spring关键字
1.目测 一个一个查找文件....
2.使用程序将文件读取到内存当中,然后匹配字符串spring,这种方式被称为顺序扫描
3.将我们非结构化数据转换为结构化数据
例如Spring.txt文件中,英文文件每一个单词都是以空格进行区分,那么我们可以采用空格进行分割
然后将分割结果保存到数据库,这样就形成了一张表,我们在列上创建索引,加快查询速度,根据单词和文档
的对应关系找到文档列表,这样的过程我们称之为全文检索
三.全文检索概念
创建索引,然后查询索引的过程我们称之为全文检索,索引一次创建可以多次使用,这样就不用了每一次都进行文件数据查分,比较快
四.全文检索应用场景
1.搜索引擎
百度,360,谷歌等等
2.站内搜索
论坛搜索忒自,微博搜索热点,新闻网站搜索新闻
3.电商搜索
淘宝,京东
有搜索的地方都可以用到全文检索
Lucene
lucene的下载地址:http://lucene.apache.org/
什么是Lucene?
Lucene是apache下的一个开放源代码的全文检索引擎工具包。
提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能。
Lucene实现全文检索的流程:

1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:
确定原始内容即要搜索的内容>采集文档 >创建文档>分析文档>索引文档
2、红色表示搜索过程,从索引库中搜索内容,搜索过程包括:
用户通过搜索界面>创建查询>执行搜索,从索引库搜索>渲染搜索结果
Lucene的实现
第一步:导入依赖
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>7.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>7.4.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
第二步:创建索引
实现步骤:
第一步:创建一个java工程,并导入jar包。
第二步:创建一个indexwriter对象。
1)指定索引库的存放位置Directory对象
2)指定一个IndexWriterConfig对象。
第二步:创建document对象。
第三步:创建field对象,将field添加到document对象中。
第四步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库。
第五步:关闭IndexWriter对象。
//创建索引
@Test
public void createIndex() throws Exception { //指定索引库存放的路径,这个文件夹自己创建
//D:\temp\index
Directory directory = FSDirectory.open(new File("D:\\temp\\index").toPath());
//索引库还可以存放到内存中
//Directory directory = new RAMDirectory();
//创建indexwriterCofig对象
IndexWriterConfig config = new IndexWriterConfig();
//创建indexwriter对象
IndexWriter indexWriter = new IndexWriter(directory, config);
//原始文档的路径
File dir = new File("D:\\temp\\searchsource");
for (File f : dir.listFiles()) {
//文件名
String fileName = f.getName();
//文件内容
String fileContent = FileUtils.readFileToString(f);
//文件路径
String filePath = f.getPath();
//文件的大小
long fileSize = FileUtils.sizeOf(f);
//创建文件名域
//第一个参数:域的名称
//第二个参数:域的内容
//第三个参数:是否存储
Field fileNameField = new TextField("filename", fileName, Field.Store.YES);
//文件内容域
Field fileContentField = new TextField("content", fileContent, Field.Store.YES);
//文件路径域(不分析、不索引、只存储)
Field filePathField = new TextField("path", filePath, Field.Store.YES);
//文件大小域
Field fileSizeField = new TextField("size", fileSize + "", Field.Store.YES); //创建document对象
Document document = new Document();
document.add(fileNameField);
document.add(fileContentField);
document.add(filePathField);
document.add(fileSizeField);
//创建索引,并写入索引库
indexWriter.addDocument(document);
}
//关闭indexwriter
indexWriter.close();
}
创建成功之后可以使用Luke工具查看索引文件


第三步:查询索引
实现步骤:
第一步:创建一个Directory对象,也就是索引库存放的位置。
第二步:创建一个indexReader对象,需要指定Directory对象。
第三步:创建一个indexsearcher对象,需要指定IndexReader对象
第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
第五步:执行查询。
第六步:返回查询结果。遍历查询结果并输出。
第七步:关闭IndexReader对象
//查询索引库
@Test
public void searchIndex() throws Exception {
//指定索引库存放的路径
//D:\temp\index
Directory directory = FSDirectory.open(new File("D:\\temp\\index").toPath());
//创建indexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//创建indexsearcher对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//创建查询
Query query = new TermQuery(new Term("filename", "apache"));
//执行查询
//第一个参数是查询对象,第二个参数是查询结果返回的最大值
TopDocs topDocs = indexSearcher.search(query, 10);
//查询结果的总条数
System.out.println("查询结果的总条数:"+ topDocs.totalHits);
//遍历查询结果
//topDocs.scoreDocs存储了document对象的id
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
//scoreDoc.doc属性就是document对象的id
//根据document的id找到document对象
Document document = indexSearcher.doc(scoreDoc.doc);
System.out.println(document.get("filename"));
//System.out.println(document.get("content"));
System.out.println(document.get("path"));
System.out.println(document.get("size"));
System.out.println("-------------------------");
}
//关闭indexreader对象
indexReader.close();
}
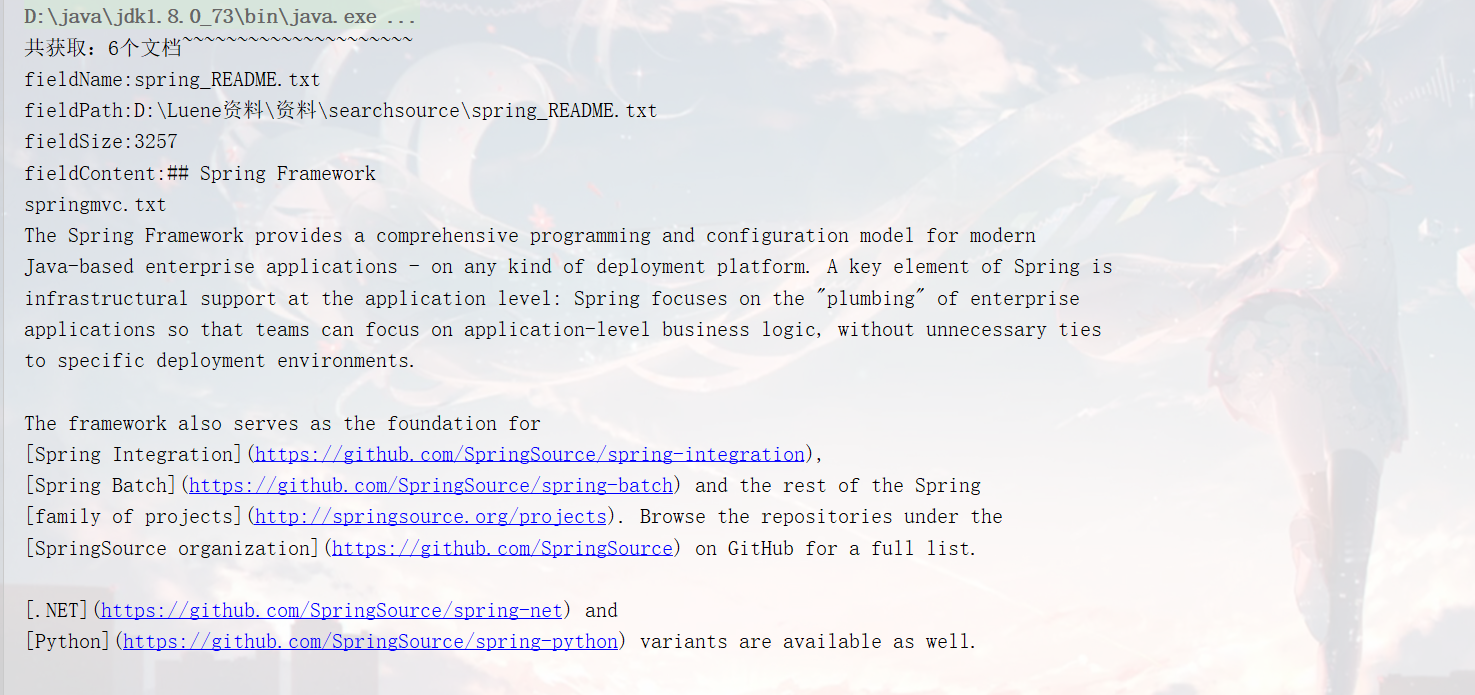
结果:
全文检索以及Lucene的应用的更多相关文章
- JAVAEE——Lucene基础:什么是全文检索、Lucene实现全文检索的流程、配置开发环境、索引库创建与管理
1. 学习计划 第一天:Lucene的基础知识 1.案例分析:什么是全文检索,如何实现全文检索 2.Lucene实现全文检索的流程 a) 创建索引 b) 查询索引 3.配置开发环境 4.创建索引库 5 ...
- 全文检索(Lucene&Solr)
全文检索(Lucene&Solr) 1)什么是全文检索?为什么需要全文检索? 结构化数据(mysql等)方便查询,而非结构化数据(如多篇文章)是难以查询到自己需要的,所以要使用全文检索. 全文 ...
- 全文检索框架---Lucene
一.什么是全文检索 1.数据分类 我们生活中的数据总体分为两种:结构化数据和非结构化数据. 结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等. 非结构化数据:指不定长或无固定格式 ...
- 【手把手教你全文检索】Lucene索引的【增、删、改、查】
前言 搞检索的,应该多少都会了解Lucene一些,它开源而且简单上手,官方API足够编写些小DEMO.并且根据倒排索引,实现快速检索.本文就简单的实现增量添加索引,删除索引,通过关键字查询,以及更新索 ...
- Lucene 01 - 初步认识全文检索和Lucene
目录 1 搜索简介 1.1 搜索实现方案 1.2 数据查询方法 1.2.1 顺序扫描法 1.2.2 倒排索引法(反向索引) 1.3 搜索技术应用场景 2 Lucene简介 2.1 Lucene是什么 ...
- 大型运输行业实战_day15_1_全文检索之Lucene
1.引入 全文检索简介: 非结构化数据又一种叫法叫全文数据.从全文数据(文本)中进行检索就叫全文检索. 2.数据库搜索的弊端 案例 : select * from product whe ...
- 全文检索技术---Lucene
1 Lucene介绍 1.1 什么是Lucene Lucene是apache下的一个开源的全文检索引擎工具包.它为软件开发人员提供一个简单易用的工具包(类库),以方便的在目标系统中实现 ...
- .NET 6全文检索引擎Lucene.NET 4.8简单封装
前言 因为最近在做一个检索数据的工具.最开始用的Mysql8自带的全文检索功能.但是发现这货数据量超过百万之后,检索速度直线下降. 于是想到Lucene.net.花了一晚上时间做了简单的封装.可以直接 ...
- 全文检索 java Lucene
索引文件:[D:\luceneDemo\data\TXT小说\陛下是妻迷.txt] 大小:[1185.0 KB] 索引文件:[D:\luceneDemo\data\TXT小说\随身空间重生在七十年代. ...
随机推荐
- AMD R5 2400G插帧教程
最近买的小主机带的是AMD R5 2400G显卡,支持AMD的插帧技术,Sandeepin肯定要体验一把效果. BlueskyFRC 按照网上的教程配置,似乎2400G显卡驱动里没有AMD Fluid ...
- COCOAPI for windows error!
refer this https://github.com/philferriere/cocoapi However, you may encounter a bug where you cannot ...
- css的字体单位
在css中的字体单位主要以px.em.rem为主.其中px也就是像素,是一种字体长度,它的长度是相对于显示器的品目分辨率而言的.一般情况下在浏览器中默认字体的大小是16px.其中em是相对字体.em的 ...
- 每天一道Java题[8]
以下题目及解答属于个人见解,欢迎大家也分享和补充一下解答的内容,互相促进,共同进步! 题目 RESTful WebService与SOAP WebService有什么异同? 解答 SOAP是一个协议, ...
- TS 原理详细解读(5)语法2-语法解析
在上一节介绍了语法树的结构,本节则介绍如何解析标记组成语法树. 对应的源码位于 src/compiler/parser.ts. 入口函数 要解析一份源码,输入当然是源码内容(字符串),同时还提供路径( ...
- 死磕java(3)
流程控制 if else // do while// switch case// while do// break// continue// 相关查询百度
- Android Webview实现有道电子词典
毕业设计android电子词典,先实现的一个小小的demo. 所谓的毕业设计就是用最短的时间学习一门语言,做出一个小的project. activity_main.xml <LinearLayo ...
- 带大家用40行python代码实现一个疫情地图
最近两个月,因为新冠病毒无情的肆虐,相信会给每个中国人的记忆中画上重重的一笔.到今天为止,疫情形势依然十分严峻,虽然除湖北外的其他省份已经连续十一天确诊人数下降,但是接下来还有将近至少1.6亿的人口迁 ...
- POJ_1182_并查集
http://poj.org/problem?id=1182 pre构建有关系的号码的树,rel保存当前号码与根的关系,0表示相同,1表示根吃当前,2表示当前吃根. 代码中的更新公式可以先把各种情况枚 ...
- ARTS Week 3
Nov 11,2019 ~ Nov 17,2019 Algorithm 本周来介绍快速求一个数字n次方的余数. 理论基础 我们先定义运算$ x \bmod p = r \(与\) x \equiv r ...