Hadoop之block研究
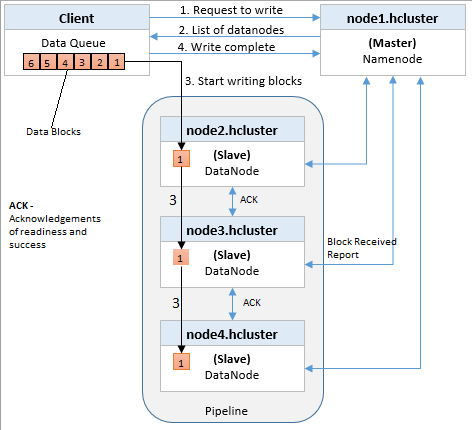
 注释:准备和成功的ACK(确认)
注释:准备和成功的ACK(确认)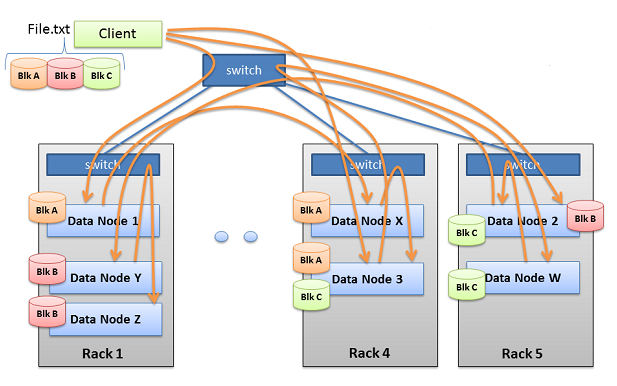

Hadoop之block研究的更多相关文章
- ios之Block研究
Block的好处,我总结了下主要有2点:1.用于回调特别方便,2.可以延长对象的作用区域.但是,Block的内存管理这个模块一直不是很清楚,这个周末好好的看了下Block的原理,有些许心得. 为了性能 ...
- hadoop中block副本的放置策略
下面的这种是针对于塔式服务器的副本的放置策略
- 【转载】Hadoop机架感知
转载自http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2843015.html 背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机 ...
- hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
- Hadoop分布式配置
本作品由Man_华创作,采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可.基于http://www.cnblogs.com/manhua/上的作品创作. 请先参照Linux安 ...
- Hadoop port to Jxta P2P Framework
https://www.java.net/forum/topic/jxta/jxta-community-forum/hadoop-port-jxta-p2p-framework —————————— ...
- HADOOP实战
一.软件版本Centos6.5.VMware 10CDH5.2.0(Hadoop 2.5.0)Hive-0.13 sqoop-1.4.5 二.学完课程之后,您可以:①.一个人搞定企业Hadoop平台搭 ...
- 基于Docker一键部署大规模Hadoop集群及设计思路
一.背景: 随着互联网的发展.互联网用户的增加,互联网中的数据也急剧膨胀.每天产生的数据量数以万计,本地文件系统和单机CPU已无法满足存储和计算要求.Hadoop分布式文件系统(HDFS)是海量数据存 ...
- 第十三章 hadoop机架感知
背景 分布式的集群通常包含非常多的机器,由于受到机架槽位和交换机网口的限制,通常大型的分布式集群都会跨好几个机架,由多个机架上的机器共同组成一个分布式集群.机架内的机器之间的网络速度通常都会高于跨机架 ...
随机推荐
- HTML5开篇定义(更新中)
以下介绍的两种属性是为后面的属性支持左铺垫,大概一看就OK了. 通用属性 id 用于为HTML元素指定唯一标识 style 用于为HTML元素指定CSS指定样式 class 用于匹配CSS样式的cla ...
- node.js使用Sequelize 操作mysql
Sequelize就是Node上的ORM框架 ,相当于java端的Hibernate 是一个基于 promise 的 Node.js ORM, 目前支持 Postgres, MySQL, SQLite ...
- laravel4.2 union联合,join关联分组查询最新记录时,查询条件不对,解决方案
需求: 分组联合查询,或者最新记录. 问题: mysql分组的时候默认会查询第一条记录,存在gourp by时 order by 无效. 一般解决办法就是 ,select * from ( sele ...
- Hive(5)-DDL数据定义
一. 创建数据库 CREATE DATABASE [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_pat ...
- jz2440_lcd
VDEN 使能信号 HSYNC 水平方向的同步信号 VSYNC 垂直方向的同步信号 LED-/LED+ 背光信号 VCLK 时钟信号 VD0~VD23 数字 ...
- 【AD】自己画板的备忘
快捷键: [Ctrl + M ]计算出两点之间的距离,画电路板时会用到 [Ctrl + Q ]在设定X.Y..等等的地方,快捷键可以公英制快速切换 [shift + 空格键 ]在布线的同时,此快捷键可 ...
- BugkuWeb本地包含
知识点:$_REQUEST不是一个函数,它是一个超全局变量,里面包括有$_GET $_POST $_COOKIE的值,$_REPUEST 是接收了 $_GET $_POST $_COOKIE 三个的集 ...
- React 源码中的依赖注入方法
一.前言 依赖注入(Dependency Injection)这个概念的兴起已经有很长时间了,把这个概念融入到框架中达到出神入化境地的,非Spring莫属.然而在前端领域,似乎很少会提到这个概念,难道 ...
- 在window10平台下安装TensorFlow(only cpu)
这是我在安装tensorflow遇到的问题记录 希望可以给大家一些帮助(2019年1月6日) 1. 需要安装的环境及软件 python3.6 Anaconda Tensorflow 2. 先安装ana ...
- 传说是小米家的一道面试题难倒了某Java程序员。扑克牌排序问题。
网上说的是有位网友在面试小米Java岗三次后,终于挺进了第三轮面试,结果还是败在了两道算法题上面. 1.写个读方法和写方法,实现读写锁 2.一副从1到n的牌,每次从牌堆顶取一张放桌子上,再取一张放牌堆 ...