PyTorch 数据集类 和 数据加载类 的一些尝试
最近在学习PyTorch, 但是对里面的数据类和数据加载类比较迷糊,可能是封装的太好大部分情况下是不需要有什么自己的操作的,不过偶然遇到一些自己导入的数据时就会遇到一些问题,因此自己对此做了一些小实验,小尝试。
下面给出一个常用的数据类使用方式:
def data_tf(x):
x = np.array(x, dtype='float32') / 255 # 将数据变到 0 ~ 1 之间
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据
train_set = MNIST('./data', train=True, transform=data_tf, download=True) # 载入数据集,申明定义的数据变换
test_set = MNIST('./data', train=False, transform=data_tf, download=True)
其中, data_tf 并不是必须要有的,比如:
from torchvision.datasets import MNIST # 导入 pytorch 内置的 mnist 数据
train_set = MNIST('./data', train=True, download=True) # 载入数据集,申明定义的数据变换
test_set = MNIST('./data', train=False, download=True)
这里面的MNIST类是框架自带的,可以自动下载MNIST数据库, ./data 是指将下载的数据集存放在当前目录下的哪个目录下, train 这个属性 True时 则在 ./data文件夹下面在建立一个 train的文件夹然后把下载的数据存放在其中, 当train属性是False的时候则把下载的数据放在 test文件夹下面。
划线部分是老版本的PyTorch的处理方式, 最近试了一下最新版本 PyTorch 1.0 , train为True的时候是把数据放在 ./data/processed 文件夹下面, 命名为training.pt , 为False 的时候则放在 ./data/processed 文件夹下面, 命名为test.pt 。
这时候就出现了一个问题, 如果你使用的数据集不是框架自带的那么如何使用数据类呢,这个时候就要使用 pytorch 中的 Dataset 类了。
from torch.utils.data import Dataset
我们需要重写 Dataset类, 需要实现的方法为 __len__ 和 __getitem__ 这两个内置方法, 这里可以看出其思想就是要重写的类需要支持按照索引查找的方法。
这里我们还是举个例子:
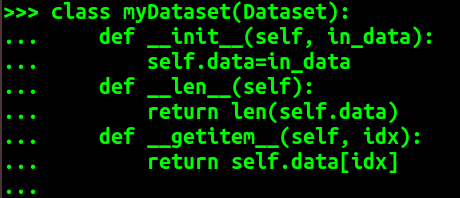


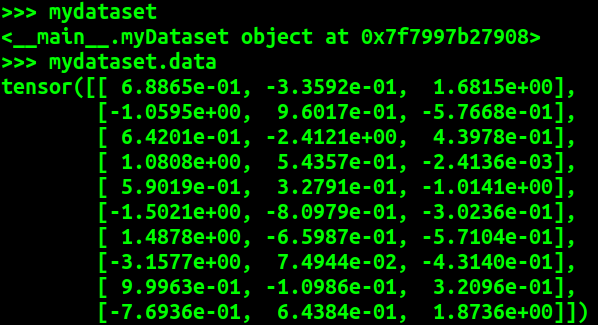
从这个例子可以看出 mydataset就是我们自定义的 myDataset 类生成的自定义数据类对象。我们可以在myDataset类中自定义一些方法来对需要的数据进行处理。
为说明该问题另附加一个例子:
from torch.utils.data import Dataset #需要在pytorch中使用的数据
data=[[1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3], [5.1, 5.2, 5.3]] class myDataset(Dataset):
def __init__(self, indata):
self.data=indata
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx] mydataset=myDataset(data)
那么又来了一个问题,我们不重写 Dataset类的话可不可以呢, 经过尝试发现还真可以,如下:

又如:



由这个例子可以看出数据类对象可以不重写Dataset类, 只要具备 __len__ __getitem__ 方法就可以。而且从这个例子我们可以看出 DataLoader 是一个迭代器, 如果shuffle 设置为 True 那么在每次迭代之前都会重新排序。
同时由上面两个例子可以看出 DataLoader类会把传入的数据集合中的数据转化为 torch.tensor 类型, 当然是采用默认的 DataLoader类中转化函数 transform的情况下。
这也就是说 DataLoader 默认的转化函数 transform操作为 传入的[ [x, x, x], [y, y, y] ] 输出的是 [ tensor([x, x, x]), tensor([y, y, y]) ] ,
传入的是 tensor([ [x, x, x], [y, y, y] ]) 输出的是 tensor([ tensor([x, x, x]), tensor([y, y, y]) ] ), (这个例子是在 batch_size=2 的情况)。
综上,可知 其实 Dataset类, 和 DataLoader类其实在pytorch 计算过程中都不是一定要有的, 其中Dataset类是起一个规范作用,意义在于要人们对不同的类型数据做一些初步的调整,使其支持按照索引读取,以使其可以在 DataLoader中使用。
DataLoader 是一个迭代器, 可以方便的通过设置 batch_size 来实现 batch过程,transform则是对数据的一些处理。
---------------------------------------------------------------------------------------------------
上述内容更正:
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader #需要在pytorch中使用的数据
data=[[1.1, 1.2, 1.3], [2.1, 2.2, 2.3], [3.1, 3.2, 3.3], [4.1, 4.2, 4.3], [5.1, 5.2, 5.3]] class myDataset(Dataset):
def __init__(self, indata):
self.data=indata
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx] mydataset=myDataset(data)
train_data=DataLoader(mydataset, batch_size=3, shuffle=True) print("上文的错误操作:") for i in train_data:
print(i)
print('-'*30)
print('again')
for i in train_data:
print(i)
print('-'*30) ######################################### data=np.array(data)
data=torch.from_numpy(data) mydataset=myDataset(data)
train_data=DataLoader(mydataset, batch_size=3, shuffle=True) print("修正后的正确操作:") for i in train_data:
print(i)
print('-'*30)
print('again')
for i in train_data:
print(i)
print('-'*30)
(base) devil@devilmaycry:/tmp$ python w.py
上文的错误操作:
[tensor([3.1000, 4.1000, 5.1000], dtype=torch.float64), tensor([3.2000, 4.2000, 5.2000], dtype=torch.float64), tensor([3.3000, 4.3000, 5.3000], dtype=torch.float64)]
------------------------------
[tensor([1.1000, 2.1000], dtype=torch.float64), tensor([1.2000, 2.2000], dtype=torch.float64), tensor([1.3000, 2.3000], dtype=torch.float64)]
------------------------------
again
[tensor([3.1000, 5.1000, 1.1000], dtype=torch.float64), tensor([3.2000, 5.2000, 1.2000], dtype=torch.float64), tensor([3.3000, 5.3000, 1.3000], dtype=torch.float64)]
------------------------------
[tensor([2.1000, 4.1000], dtype=torch.float64), tensor([2.2000, 4.2000], dtype=torch.float64), tensor([2.3000, 4.3000], dtype=torch.float64)] ------------------------------ 修正后的正确操作:
tensor([[2.1000, 2.2000, 2.3000],
[1.1000, 1.2000, 1.3000],
[3.1000, 3.2000, 3.3000]], dtype=torch.float64)
------------------------------
tensor([[4.1000, 4.2000, 4.3000],
[5.1000, 5.2000, 5.3000]], dtype=torch.float64)
------------------------------
again
tensor([[5.1000, 5.2000, 5.3000],
[4.1000, 4.2000, 4.3000],
[3.1000, 3.2000, 3.3000]], dtype=torch.float64)
------------------------------
tensor([[2.1000, 2.2000, 2.3000],
[1.1000, 1.2000, 1.3000]], dtype=torch.float64)
------------------------------
可以看出 传入到 Dataset 中的对象必须是 torch 类型的 tensor 类型, 如果传入的是list则会得出错误结果。
-----------------------------------------------------------------------------------------------------
补充:
之所以发现上面的这个错误,是因为发现了下面的代码:
import numpy as np
from torchvision.datasets import mnist # 导入 pytorch 内置的 mnist 数据
from torch.utils.data import DataLoader
#from torch.utils.data import Dataset def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 数据预处理,标准化
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x #Dataset
# 重新载入数据集,申明定义的数据变换
train_set = mnist.MNIST('./data', train=True, transform=data_tf, download=True)
test_set = mnist.MNIST('./data', train=False, transform=data_tf, download=True) train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=128, shuffle=False)
从上面的 data_tf 函数中我们发现, Dataset对象返回的是 torch 的 tensor 对象。
PyTorch 数据集类 和 数据加载类 的一些尝试的更多相关文章
- arcgis python 使用光标和内存中的要素类将数据加载到要素集 学习:http://zhihu.esrichina.com.cn/article/634
学习:http://zhihu.esrichina.com.cn/article/634使用光标和内存中的要素类将数据加载到要素集 import arcpy arcpy.env.overwriteOu ...
- java动态加载类和静态加载类笔记
JAVA中的静态加载类是编译时刻加载类 动态加载类指的是运行时刻加载类 二者有什么区别呢 举一个例子 现在我创建了一个类 实现的功能假设为通过传入的参数调用具体的类和方法 class offic ...
- Unity3d通用工具类之数据配置加载类
今天,我们来讲讲游戏中的数据配置加载. 什么是游戏数据加载呢?一般来说游戏中会有场景地图. 按照国际惯例,先贴一张游戏场景的地图: 在这张地图上,我们可以看到有很多正六边形,正六边形上有树木.岩石等. ...
- [javaSE] 反射-动态加载类
Class.forName(“类的全称”) ①不仅表示了类的类类型,还代表了动态加载类 ②请大家区分编译,运行 ③编译时刻加载类是静态加载类,运行时刻加载类是动态加载类 Ⅰ所有的new对象都是静态加载 ...
- Java 编程下使用 Class.forName() 加载类
在一些应用中,无法事先知道使用者将加载什么类,而必须让使用者指定类名称以加载类,可以使用 Class 的静态 forName() 方法实现动态加载类.下面的范例让你可以指定类名称来获得类的相关信息. ...
- Java 编程下使用 Class.forName() 加载类【转】
在一些应用中,无法事先知道使用者将加载什么类,而必须让使用者指定类名称以加载类,可以使用 Class 的静态 forName() 方法实现动态加载类.下面的范例让你可以指定类名称来获得类的相关信息. ...
- java中class.forName和classLoader加载类的区分
java中class.forName和classLoader都可用来对类进行加载.前者除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块.而classLoade ...
- 反射01 Class类的使用、动态加载类、类类型说明、获取类的信息
0 Java反射机制 反射(Reflection)是 Java 的高级特性之一,是框架实现的基础. 0.1 定义 Java 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法:对 ...
- java反射机制与动态加载类
什么是java反射机制? 1.当程序运行时,允许改变程序结构或变量类型,这种语言称为动态语言.我们认为java并不是动态语言,但是它却有一个非常突出的动态相关机制,俗称:反射. IT行业里这么说,没有 ...
随机推荐
- McAfee 与 360使用感受
运维给配的 win 10.4G内存 ,装的 McAfee,每次开机啥事不干内存去了55%, 开齐qq.微信.vscode.浏览器就要冲90%,再多开几个网页电脑就卡得很, 最近,卡死机了.. 然后看了 ...
- Java的八种基本类型:(按字节来分)
Java的八种基本类型:(按字节来分) boolean 布尔型 1个字节 8bit(8位) byte 字节类型 1个字节 char 字符类型 2个字节 short ...
- 【Robot Framework 项目实战 02】SeleniumLibrary Web UI 自动化
前言 SeleniumLibrary 是针对 Robot Framework 开发的 Selenium 库.它也 Robot Framework 下面最流程的库之一.主要用于编写 Web UI 自动化 ...
- jsp/servlet区别
简介: JSP全名为Java Server Pages,中文名叫java服务器页面,其根本是一个简化的Servlet设计,它是由Sun Microsystems公司倡导.许多公司参与一起建立的一种动态 ...
- 4-12 如何搜索API
遇到一个参数prompt,使用rails ,API没有找到,怎么办? site关键字 在全网搜索 或者google一下,或是在stack overflow 上找答案 prompt 是FormOptio ...
- codeforces 930b//Game with String// Codeforces Round #468 (Div. 1)
题意:一个串,右循环移位后,告诉你第一个字母,还能告诉你一个,问你能确定移位后的串的概率. 用map记录每个字母出现的位置.对于每个字母,用arr[j][k]记录它的所有出现位置的后j位是字母k的个数 ...
- Mr. Kitayuta vs. Bamboos CodeForces - 505E (堆,二分答案)
大意: 给定$n$棵竹子, 每棵竹子初始$h_i$, 每天结束时长$a_i$, 共$m$天, 每天可以任选$k$棵竹子砍掉$p$, 若不足$p$则变为0, 求$m$天中竹子最大值的最小值 先二分答案转 ...
- 2-16 MySQL字段约束-索引-外键
一:字段修饰符 1:null和not null修饰符 我们通过这个例子来看看 mysql> create table worker(id int not null,name varchar(8) ...
- OA项目(MVC项目)
1. 新建,项目,其他项目类型,空白解决方案 2. 选中解决方案,添加,新建项目,类库: (1)添加OA.Model,删除其中的Class1.cs (2)添加OA.DAL(数据访问层),删除Class ...
- 使用poi导出Excel,并设定单元格内容类型,抛出异常
本例子使用的是HSSF,为Excel2003提供处理方案. 设定为输入类型为数值 import org.apache.poi.hssf.usermodel.DVConstraint; import o ...