FDR错误发现率-P值校正学习[转载]
转自:https://baike.baidu.com/item/FDR/16312044?fr=aladdin https://blog.csdn.net/taojiea1014/article/details/79681249
http://www.360doc.com/content/18/0914/21/19913717_786724085.shtml https://www.sohu.com/a/165109778_785442
https://www.jianshu.com/p/13f46bebebd4
1.定义
FDR(false discovery rate),是统计学中常见的一个名词,翻译为伪发现率,其意义为是 错误拒绝(拒绝真的(原)假设)的个数占所有被拒绝的原假设个数的比例的期望值。

//FDR是个期望值
2.利用Benjamini–Hochberg方法计算FDR的计算及R语言实现
FDR的计算相当简单,包括以下几步:
1.对p值进行从小到大的排序,标记上序号1~n;
2.其中,最大的FDR(不考虑重复则为第n位)等于最大的p值;
3.对于n-1位的FDR,取下面两者的较小值:
上一步(第n位)计算得出的FDR值;
p值*n/(n-1)
4.不断迭代第三步(n-2,n-3....),直至计算到最小p值对应的FDR。
例子:
temp <-c(0.01,0.11,0.21,0.31,0.41,0.51,0.61,0.71,0.81,0.91)
p.adjust(temp,method = "fdr") 结果:
[] 0.1000000 0.5500000 0.7000000 0.7750000 0.8200000 0.8500000 0.8714286
[] 0.8875000 0.9000000 0.9100000
另外,如果对temp的倒数第二个P值进行更改:
temp2 <-c(0.01,0.11,0.21,0.31,0.41,0.51,0.61,0.71,0.90,0.91)
p.adjust(temp2,method = "fdr") [] 0.1000000 0.5500000 0.7000000 0.7750000 0.8200000 0.8500000 0.8714286
[] 0.8875000 0.9100000 0.9100000
第一次:min(0.91,0.81*10/9)=0.90
第二次:min(0.91,0.90*10/9)=0.91
分别演示了两个取到不同值的过程。
这样可以保证从统计学上FDP不超过q。
3.确定FDR

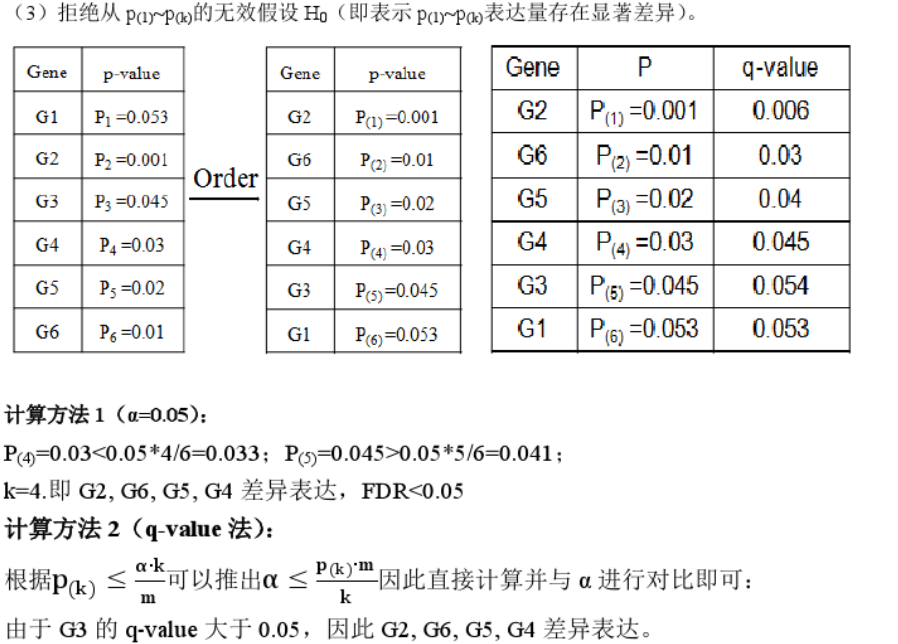
3.只使用P值的话
单次检验:针对单个基因(蛋白),采用统计检验,假设采用的p值为小于0.05,我们通常认为这个基因在两个(组)样本中的表达是有显著差异的,但是仍旧有5%的概率,这个基因并不是差异基因。
注:原假设是两个基因不存在显著性差异。
多次检验:当两个(组)样本中有10000个基因采用同样的检验方式进行统计检验时,这个时候就有一个问题,单次犯错的概率为0.05, 进行10000次检验的话,那么就有0.05*10000=500 个基因的差异被错误估计了。
有一种严格校正法:
Bonferroni 校正法
Bonferroni校正法:如果进行N次检验,那么p值的筛选的阈值设定为p/N。 比如,进行10000次检验的话,如果p值选择为0.05, 那么校正的p值筛选为0.000005。 p值低于此的基因才是显著性差异基因。
该方法虽然简单,但是过于严格,导致最后找的差异基因很少,甚至找不到差异的基因。
4.假设检验

我们在处理宏基因组差异基因的选择时,需要对两个样本的每个基因进行一次假设检验。如果我们有m个基因,那么我们就要做m次假设检验。每一次的假设检验的零假设H0为:两个样本的这个基因没有显著性差异。其中有m0个零假设是正确的,即这个基因在两个样本中确实没有显著性差异;但有m1=m-m0个零假设是错误的,即两个样本的这个基因是有显著性差异。m次检验之后,被拒绝的零假设的个数记为R。为了方便记忆,可用一张表格来表示假设检验的结果,如上。
我们可以得到FDR准则,即要求控制错误拒绝率。令Q=V / (V+S),它表示被错误拒绝的零假设数目占所有被拒绝的零假设数目的比例。Q也是一个不可观测的随机变量。
https://stackoverflow.com/questions/10323817/r-unexpected-results-from-p-adjust-fdr
这个里讲了如何计算及过程,明天来总结。
5.R中的cummin函数
> cummin(c(:, :, :))
[] > c(:, :, :)
[] #求从左到右累积的最小值。
#到第二个2出现时已经有了最小值是1,所以对应都是1.
#到第一个0出现时,是最小值,那么对应之后再出现的4 累计最小值都是0.
FDR错误发现率-P值校正学习[转载]的更多相关文章
- df值自由度学习[转载]
转自:https://www.applysquare.com/topic-cn/78TAnIzZ6/ https://zhidao.baidu.com/question/175605082855699 ...
- etcd:用于服务发现的键值存储系统
etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现.etcd是由CoreOS开发并维护的,灵感来自于 ZooKeeper 和 Doozer,它使用Go语言编写,并通过Raft一致性算法处理 ...
- 错误 1 Files 的值“ < < < < < < < .mine”无效。路径中具有非法字符。
错误 1 Files 的值“ < < < < < < < .mine”无效.路径中具有非法字符. 今天使用SVN进行更新的时候,出现了如上问题,想起卓 ...
- Marlin 擠出頭溫度控制PID值校正
Marlin 擠出頭溫度控制PID值校正 擠出頭加熱器.溫度感應器安裝好後,先別急著直接指定工作溫度並且加熱.因為控制板上的溫度控制PID參數尚未校正.如果加熱速度過快,有可能會加熱過度並且導致零件燒 ...
- Java多线程学习(转载)
Java多线程学习(转载) 时间:2015-03-14 13:53:14 阅读:137413 评论:4 收藏:3 [点我收藏+] 转载 :http://blog ...
- 为什么说Java中只有值传递(转载)
出处:https://www.hollischuang.com/archives/2275 关于这个问题,在StackOverflow上也引发过广泛的讨论,看来很多程序员对于这个问题的理解都不尽相同, ...
- 发现意外之美 - SwiftyJSON 源码学习 | 咖啡时间
SwiftyJSON 是一个很优秀 Swift 语言第三方库.我们在之前的文章中对它有过介绍.相信大家对它也有了一些了解.提升开发功力最好的方式就是学习优秀的源代码了,记得大神 TJ Holowayc ...
- 准确率,召回率,F值,ROC,AUC
度量表 1.准确率 (presion) p=TPTP+FP 理解为你预测对的正例数占你预测正例总量的比率,假设实际有90个正例,10个负例,你预测80(75+,5-)个正例,20(15+,5-)个负例 ...
- <input type="text"/>未输入时属性value的默认值--js学习之路
在百度ife刷题是自己的一个错误引发了我对<input type="text"/>的学习. 先贴代码: <!DOCTYPE html> <html&g ...
随机推荐
- python+机器学习 算法用到的知识点总结
1.浅述python中argsort()函数的用法 (1).先定义一个array数据 1 import numpy as np 2 x=np.array([1,4,3,-1,6,9]) (2).现在我 ...
- Python学习(26):Python函数式编程
转自 http://www.cnblogs.com/BeginMan/p/3509985.html 前言 <core python programming 2>说: Python不大可能 ...
- docker 快速搭建Nexus3
1.拉取镜像 docker pull sonatype/nexus3 2.启动容器 : -p : -p : -v /mnt/gv0/nexus-data:/nexus-data sonatype/ne ...
- Linux 下如何安装 .rpm 文件
执行以下命令安装: rpm -i your-file-name.rpm 详细的可参考: http://os.51cto.com/art/201001/177866.htm
- 原生js--元素尺寸、位置和溢出
判断元素尺寸和位置的方法: elem.getBoundingClientRect() // 已验证IE7+.firefox.chrome均支持此方法 该方法返回一个对象(坐标值为视口坐标,不是文档坐 ...
- filter对数组和对象的过滤
1,对数组的过滤 let arr = ['1', '2', '3'] let b = arr.filter(val => val === '2') console.log(b) // ['2] ...
- oracle索引优化
零.概述 在这之前,一直都是使用mysql来进行开发或者部署.最近及今后很长一段时间都要使用oracle,今天和同事也遇到一个oracle 慢查询问题.查了很多资料,这里记录备忘.持续更新ing... ...
- 基于Python的跨平台端口转发工具
背景 使用lcx也好,nc也好,总是会被安全防护软件查杀,所以想着自己写一个.顺面学习一下,端口转发的原理. 端口转发的逻辑 端口转发的逻辑很简单开启两个scoket,一个绑定IP端口进行listen ...
- [算法]Bobmer
package com.company; import com.sun.org.apache.bcel.internal.generic.AASTORE; import java.awt.*; imp ...
- [工具] Sublime Text 使用指南
http://bbs.it-home.org/thread-46291-1-1.html 摘要(Abstract) 更新记录 更正打开控制台的快捷键为Ctrl + ` 更正全局替换的快捷键为Ctrl ...