基于octree的空间划分及搜索操作
(1) octree是一种用于管理稀疏3D数据的树形数据结构,每个内部节点都正好有八个子节点,介绍如何用octree在点云数据中进行空间划分及近邻搜索,实现“体素内近邻搜索(Neighbors within VOxel Search)”,"K近邻搜索(K Nearest Neighbor Search)","半径内近邻搜索"(Neighbors within Radius Search)
K近邻搜索(K Nearest Neighbor Search)
所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
我们常说,物以类聚,人以群分,判别一个人是一个什么样品质特征的人,常常可以从他/她身边的朋友入手,所谓观其友,而识其人。我们不是要判别上图中那个绿色的圆是属于哪一类数据么,好说,从它的邻居下手。但一次性看多少个邻居呢?从上图中,你还能看到:

- 如果K=3,绿色圆点的最近的3个邻居是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
- 如果K=5,绿色圆点的最近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
- K 值的选择会对算法的结果产生重大影响。K值较小意味着只有与输入实例较近的训练实例才会对预测结果起作用,但容易发生过拟合;如果 K 值较大,优点是可以减少学习的估计误差,但缺点是学习的近似误差增大,这时与输入实例较远的训练实例也会对预测起作用,使预测发生错误。在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最优的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。
- 该算法中的分类决策规则往往是多数表决,即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别
- 距离度量一般采用 Lp 距离,当p=2时,即为欧氏距离,在度量之前,应该将每个属性的值规范化,这样有助于防止具有较大初始值域的属性比具有较小初始值域的属性的权重过大。
半径内近邻搜索"(Neighbors within Radius Search)
代码解析,新建工程文件ch3_3,及文件octree_search.cpp
octree_search.cpp 内容
#include <pcl/point_cloud.h> //点云头文件
#include <pcl/octree/octree.h> //八叉树头文件 #include <iostream>
#include <vector>
#include <ctime> int
main (int argc, char** argv)
{
srand ((unsigned int) time (NULL)); //用系统时间初始化随机种子与 srand (time (NULL))的区别 pcl::PointCloud<pcl::PointXYZ>::Ptr cloud (new pcl::PointCloud<pcl::PointXYZ>); // 创建点云数据
cloud->width = ;
cloud->height = ; //无序
cloud->points.resize (cloud->width * cloud->height); for (size_t i = ; i < cloud->points.size (); ++i) //随机循环产生点云的坐标值
{
cloud->points[i].x = 1024.0f * rand () / (RAND_MAX + 1.0f);
cloud->points[i].y = 1024.0f * rand () / (RAND_MAX + 1.0f);
cloud->points[i].z = 1024.0f * rand () / (RAND_MAX + 1.0f);
}
/****************************************************************************
创建一个octree实例,用设置分辨率进行初始化,该octree用它的页节点存放点索引向量,
分辨率参数描述最低一级octree的最小体素的尺寸,因此octree的深度是分辨率和点云空间维度
的函数,如果知道点云的边界框,应该用defineBoundingbox方法把它分配给octree然后通过
点云指针把所有点增加到ctree中。
*****************************************************************************/
float resolution = 128.0f; pcl::octree::OctreePointCloudSearch<pcl::PointXYZ> octree (resolution); //初始化Octree octree.setInputCloud (cloud); //设置输入点云 这两句是最关键的建立PointCloud和octree之间的联系
octree.addPointsFromInputCloud (); //构建octree pcl::PointXYZ searchPoint; //设置searchPoint searchPoint.x = 1024.0f * rand () / (RAND_MAX + 1.0f);
searchPoint.y = 1024.0f * rand () / (RAND_MAX + 1.0f);
searchPoint.z = 1024.0f * rand () / (RAND_MAX + 1.0f); /*************************************************************************************
一旦PointCloud和octree联系一起,就能进行搜索操作,这里使用的是“体素近邻搜索”,把查询点所在体素中
其他点的索引作为查询结果返回,结果以点索引向量的形式保存,因此搜索点和搜索结果之间的距离取决于octree的分辨率参数
*****************************************************************************************/ std::vector<int> pointIdxVec; //存储体素近邻搜索结果向量 if (octree.voxelSearch (searchPoint, pointIdxVec)) //执行搜索,返回结果到pointIdxVec
{
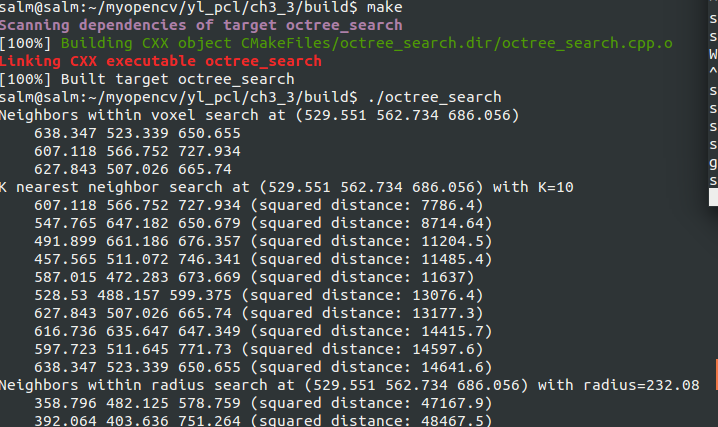
std::cout << "Neighbors within voxel search at (" << searchPoint.x
<< " " << searchPoint.y
<< " " << searchPoint.z << ")"
<< std::endl; for (size_t i = ; i < pointIdxVec.size (); ++i) //打印结果点坐标
std::cout << " " << cloud->points[pointIdxVec[i]].x
<< " " << cloud->points[pointIdxVec[i]].y
<< " " << cloud->points[pointIdxVec[i]].z << std::endl;
} /**********************************************************************************
K 被设置为10 ,K近邻搜索 方法把搜索结果写到两个分开的向量,第一个pointIdxNKNSearch包含搜索结果
(结果点的索引的向量) 第二个向量pointNKNSquaredDistance存储搜索点与近邻之间的距离的平方。
*************************************************************************************/ //K 近邻搜索
int K = ; std::vector<int> pointIdxNKNSearch; //结果点的索引的向量
std::vector<float> pointNKNSquaredDistance; //搜索点与近邻之间的距离的平方 std::cout << "K nearest neighbor search at (" << searchPoint.x
<< " " << searchPoint.y
<< " " << searchPoint.z
<< ") with K=" << K << std::endl; if (octree.nearestKSearch (searchPoint, K, pointIdxNKNSearch, pointNKNSquaredDistance) > )
{
for (size_t i = ; i < pointIdxNKNSearch.size (); ++i)
std::cout << " " << cloud->points[ pointIdxNKNSearch[i] ].x
<< " " << cloud->points[ pointIdxNKNSearch[i] ].y
<< " " << cloud->points[ pointIdxNKNSearch[i] ].z
<< " (squared distance: " << pointNKNSquaredDistance[i] << ")" << std::endl;
} // 半径内近邻搜索 std::vector<int> pointIdxRadiusSearch;
std::vector<float> pointRadiusSquaredDistance; float radius = 256.0f * rand () / (RAND_MAX + 1.0f); std::cout << "Neighbors within radius search at (" << searchPoint.x
<< " " << searchPoint.y
<< " " << searchPoint.z
<< ") with radius=" << radius << std::endl; if (octree.radiusSearch (searchPoint, radius, pointIdxRadiusSearch, pointRadiusSquaredDistance) > )
{
for (size_t i = ; i < pointIdxRadiusSearch.size (); ++i)
std::cout << " " << cloud->points[ pointIdxRadiusSearch[i] ].x
<< " " << cloud->points[ pointIdxRadiusSearch[i] ].y
<< " " << cloud->points[ pointIdxRadiusSearch[i] ].z
<< " (squared distance: " << pointRadiusSquaredDistance[i] << ")" << std::endl;
} }
建立八叉树,根据不同的搜索形式搜索体素周围的点云。
结果如下:
Octree类关键点的说明
PCL octree组件提供了几个octree类型,它们各自的叶节点特征基本上是不同的,
OctreePointCloudVector(等于OctreePointCloud):该octree能够保存每一个节点上的点索引列。
OctreePointCloudSinglePoint: 该octree类仅仅保存每一个节点上的单个点的索引,仅仅保存最后分配给叶节点的点索引
OctreePointCloudOccupancy: 该octree类不存储它的叶节点上的任何信息,它能用于空间填充情况检查
OctreePointCloudDensity:存储每一个叶节点体素中点的数目,它可以进行空间点集密集程度的查询
(2) 无序点云数据集的空间变化检测
octree是一种管理稀疏3D数据的树状结构,利用octree实现多个无序点云之间的空间变化检测,这些点云可能在尺寸。分辨率 密度,和点顺序等方面有所差异,通过递归的比较octree的树结构,可以鉴定出由octree产生的体素组成的区别所代表的空间变化,还要学习关于octree的“双缓冲”技术,以便实时的探测多个点云之间的空间组成的差异。
代码分析
octree_change_detection.cpp :
#include <pcl/point_cloud.h>
#include <pcl/octree/octree.h> #include <iostream>
#include <vector>
#include <ctime> int
main (int argc, char** argv)
{
srand ((unsigned int) time (NULL)); //用系统时间初始化随机种子 // 八叉树的分辨率,即体素的大小
float resolution = 32.0f; // 初始化空间变化检测对象
pcl::octree::OctreePointCloudChangeDetector<pcl::PointXYZ> octree (resolution); pcl::PointCloud<pcl::PointXYZ>::Ptr cloudA (new pcl::PointCloud<pcl::PointXYZ> ); //创建点云实例cloudA生成的点云数据用于建立八叉树octree对象 // 为cloudA点云填充点数据
cloudA->width = ; //设置点云cloudA的点数
cloudA->height = ; //无序点
cloudA->points.resize (cloudA->width * cloudA->height); //总数 for (size_t i = ; i < cloudA->points.size (); ++i) //循环填充
{
cloudA->points[i].x = 64.0f * rand () / (RAND_MAX + 1.0f);
cloudA->points[i].y = 64.0f * rand () / (RAND_MAX + 1.0f);
cloudA->points[i].z = 64.0f * rand () / (RAND_MAX + 1.0f);
} // 添加点云到八叉树中,构建八叉树
octree.setInputCloud (cloudA); //设置输入点云
octree.addPointsFromInputCloud (); //从输入点云构建八叉树
/***********************************************************************************
点云cloudA是参考点云用其建立的八叉树对象描述它的空间分布,octreePointCloudChangeDetector
类继承自Octree2BufBae类,Octree2BufBae类允许同时在内存中保存和管理两个octree,另外它应用了内存池
该机制能够重新利用已经分配了的节点对象,因此减少了在生成点云八叉树对象时昂贵的内存分配和释放操作
通过访问 octree.switchBuffers ()重置八叉树 octree对象的缓冲区,但把之前的octree数据仍然保留在内存中
************************************************************************************/
// 交换八叉树的缓冲,但是CloudA对应的八叉树结构仍然在内存中
octree.switchBuffers ();
//cloudB点云用于建立新的八叉树结构,与前一个cloudA对应的八叉树共享octree对象,同时在内存中驻留
pcl::PointCloud<pcl::PointXYZ>::Ptr cloudB (new pcl::PointCloud<pcl::PointXYZ> ); //实例化点云对象cloudB // 为cloudB创建点云
cloudB->width = ;
cloudB->height = ;
cloudB->points.resize (cloudB->width * cloudB->height); for (size_t i = ; i < cloudB->points.size (); ++i)
{
cloudB->points[i].x = 64.0f * rand () / (RAND_MAX + 1.0f);
cloudB->points[i].y = 64.0f * rand () / (RAND_MAX + 1.0f);
cloudB->points[i].z = 64.0f * rand () / (RAND_MAX + 1.0f);
} // 添加cloudB到八叉树中
octree.setInputCloud (cloudB);
octree.addPointsFromInputCloud (); /**************************************************************************************************************
为了检索获取存在于couodB的点集R,此R并没有cloudA中的元素,可以调用getPointIndicesFromNewVoxels方法,通过探测两个八叉树之间
体素的不同,它返回cloudB 中新加点的索引的向量,通过索引向量可以获取R点集 很明显这样就探测了cloudB相对于cloudA变化的点集,但是只能探测
到在cloudA上增加的点集,二不能探测减少的
****************************************************************************************************************/ std::vector<int> newPointIdxVector; //存储新添加的索引的向量 // 获取前一cloudA对应八叉树在cloudB对应在八叉树中没有的点集
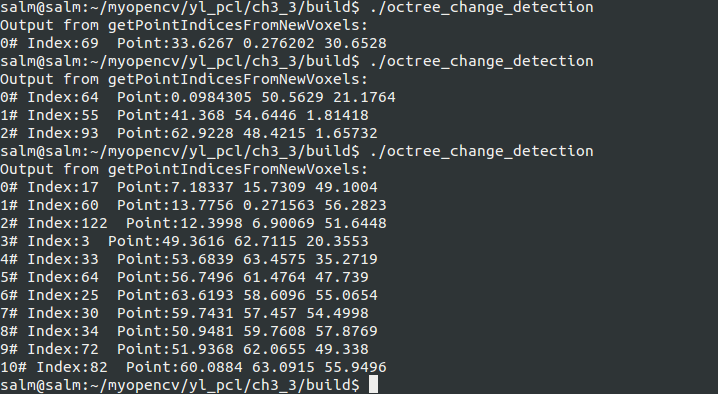
octree.getPointIndicesFromNewVoxels (newPointIdxVector); // 打印点集
std::cout << "Output from getPointIndicesFromNewVoxels:" << std::endl;
for (size_t i = ; i < newPointIdxVector.size (); ++i)
std::cout << i << "# Index:" << newPointIdxVector[i]
<< " Point:" << cloudB->points[newPointIdxVector[i]].x << " "
<< cloudB->points[newPointIdxVector[i]].y << " "
<< cloudB->points[newPointIdxVector[i]].z << std::endl; }
本实验是为了检索获取存在于couodB的点集R,此R并没有cloudA中的元素,可以调用getPointIndicesFromNewVoxels方法,通过探测两个八叉树之间
体素的不同,它返回cloudB 中新加点的索引的向量,通过索引向量可以获取R点集 很明显这样就探测了cloudB相对于cloudA变化的点集,但是只能探测
到在cloudA上增加的点集,二不能探测减少的
编译运行的结果如下(因为生成的随机点云,所以运行的结果每次都会不一样的):
微信公众号号可扫描二维码一起共同学习交流

未完待续*******************************************8888
基于octree的空间划分及搜索操作的更多相关文章
- 基于Solr的空间搜索
如果需要对带经纬度的数据进行检索,比如查找当前所在位置附近1000米的酒店,一种简单的方法就是:获取数据库中的所有酒店数据,按经纬度计算距离,返回距离小于1000米的数据. 这种方式在数据量小的时候比 ...
- 空间划分的数据结构(网格/四叉树/八叉树/BSP树/k-d树/BVH/自定义划分)
目录 网格 (Grid) 网格的应用 四叉树/八叉树 (Quadtree/Octree) 四叉树/八叉树的应用 BSP树 (Binary Space Partitioning Tree) 判断点在平面 ...
- (数据科学学习手札78)基于geopandas的空间数据分析——基础可视化
本文对应代码和数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 通过前面的文章,我们已经对geopanda ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札79)基于geopandas的空间数据分析——深入浅出分层设色
本文对应代码和数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 通过前面的文章,我们已经对geopanda ...
- 基于Solr和Zookeeper的分布式搜索方案的配置
1.1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候 ...
- 聚类-DBSCAN基于密度的空间聚类
1.DBSCAN介绍 DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度 ...
- (数据科学学习手札74)基于geopandas的空间数据分析——数据结构篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 geopandas是建立在GEOS.GDAL.P ...
- (数据科学学习手札77)基于geopandas的空间数据分析——文件IO
本文对应代码和数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的 ...
随机推荐
- C++中关于指针运算符->的重载问题
#include<iostream>using namespace std;struct date{ int year; int month; int day;};struct Perso ...
- 对于在Android Studio 的 build.gradle 中的默认applicationId 要不要写呢?
起因 刚完成一个版本的开发.刚上Google play 就有用户反映无法更新应用.错误代码为:Can't install app "****" can' be installed. ...
- Atitit 项目源码的架构,框架,配置与环境说明模板 规范 标准化
Atitit 项目源码的架构,框架,配置与环境说明模板 规范 标准化 版本1.0 作者 艾龙 attilax 1. 概述:核心业务: 1 1.1. 功能文档路径 /palmWin/src/docum ...
- 外部程序启动App
第一种:直接通过包名: Intent LaunchIntent = getPackageManager().getLaunchIntentForPackage("com.joyodream. ...
- webp技术探索
不管是 PC 还是移动端,图片一直是流量大头,以苹果公司 Retina 产品为代表的高 PPI 屏对图片的质量提出了更高的要求,如何保证在图片的精细度不降低的前提下缩小图片体积,成为了一个有价值且值得 ...
- POJ 1200 Crazy Search(字符串简单的hash)
题目:http://poj.org/problem?id=1200 最近看了一个关于hash的问题,不是很明白,于是乎就找了些关于这方面的题目,这道题是一道简单的hash 字符串题目,就先从他入手吧. ...
- nginx 404 403等错误信息页面重定向到网站首页或其它事先指定的页面
server { listen 80; server_name www.espressos.cn; location / { root html/www; index index.html index ...
- zabbix 通过自定义key完成网卡监控
创建执行脚本: # cat /etc/zabbix/monitor_scripts/network.sh #!/bin/bash #set -x usage() { echo "Useage ...
- vim学习笔记(11):vim 去掉<200b>
vim查看文件,发现多了<200b>字符,使用/200b搜索匹配不上:grep 200b 也匹配不上 查询后才知道:200b是:Unicode Character 'ZERO WIDTH ...
- DIOCP开源项目-利用队列+0MQ+多进程逻辑处理,搭建稳定,高效,分布式的服务端
最近头脑里面一直在想怎么样让能让大家基于DIOCP上写出稳定的服务端程序.很多朋友问我,你DIOCP稳定吗,我可以用他来做三层服务器吗? 当时我是这样回答的,我只能保证DIOCP底层通信的稳定. 说实 ...