04_Flume多节点load_balance实践
1、负载均衡场景
1)初始:上游Agent通过round_robin selector, 将event轮流发送给下游Collecotor1, Collector2
2)故障: 关闭Collector1进程来模拟故障,Agent1由于配置了backoff, 会将Collecotor1暂时从发送列表中移除,event全部发送给Collector2
3) 恢复: 重启Collector1进程, Collector1在经历最大timeout后,重新进入发送列表;之后的event再次分发给Collector1/2
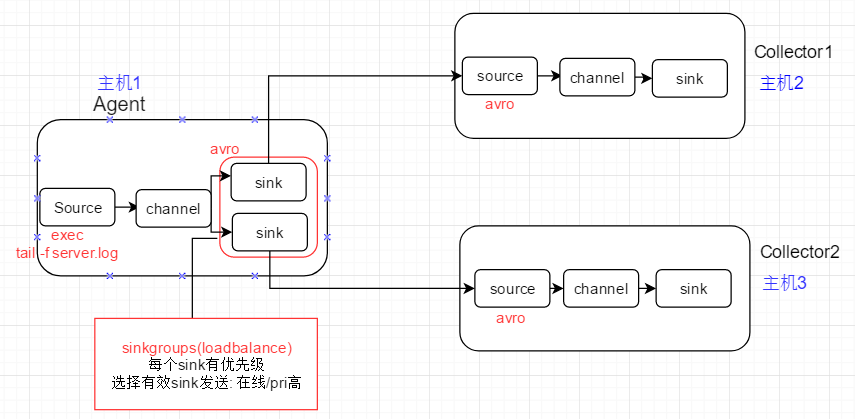
2、节点配置
2.1 上游Agent的flume配置
# -flume-loadbalance-client
# agent name: a1
# source: exec
# channel: memory
# sink: k1 k2, each set to avro type to link to next-level collector # define source,channel,sink name
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2 # define source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /root/flume_test/server.log # 03 define sink,each connect to next-level collector via hostname and port
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = slave1 # 上游avro sink绑定到下游主机,RPC
a1.sinks.k1.port = 4444 a1.sinks.k2.type = avro
a1.sinks.k2.hostname = slave2 # 上游avro sink绑定到下游主机, PRC
a1.sinks.k2.port = 4444 # 04 define sinkgroups, sink will be seleced for event distribution based on selecotr
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.selector = round_robin # 节点失效,则将节点从sinkgroup中移除一段时间
a1.sinkgroups.g1.processor.backoff = true
# 将节点从sinkgroups中移除的时间,millisecond
# 节点被暂时移除,selector就不会尝试向节点发送数据,能一定程度提高event分发速度,但event可能会分发的不均衡
a1.sinkgroups.g1.processor.selector.maxTimeOut = 10000 # define channel
a1.channels.c1.type = memory
# number of events in memory queue
a1.channels.c1.capacity =
# number of events for commit(commit events to memory queue)
a1.channels.c1.transactioncapacity = # bind source,sink to channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
2.2 下游Collector1的flume配置
# specify agent,source,sink,channel
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 02 avro source,connect to local port 4444
a1.sources.r1.type = avro # 下游avro source绑定到本机端口,端口要和上游Agent中的配置值保持一致
a1.sources.r1.bind = slave1
a1.sources.r1.port = 4444 # logger sink
a1.sinks.k1.type = logger # channel,memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # bind source,sink to channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2.3 下游Collecotor2的flume配置
# specify agent,source,sink,channel
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # 02 avro source,connect to local port 4444
a1.sources.r1.type = avro # 下游avro source绑定到本机端口,端口要和上游Agent中的配置值保持一致
a1.sources.r1.bind = slave2
a1.sources.r1.port = 4444 # logger sink
a1.sinks.k1.type = logger # channel,memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # bind source,sink to channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3、启动各个节点上的flume agent
启动Collector1
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
启动Collector2
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-failover-server.properties --name a1 -Dflume.root.logger=INFO,console
启动上游的Agent
# ./bin/flume-ng agent --conf conf --conf-file ./conf/flume-loadbalance-client.properties --name a1 -Dflume.root.logger=INFO,console
注意:需要先将下游的Collector节点启动,再启动Agent;否则Agent启动,但下游Collector没有启动,Agent会发现没有可用的下游节点,从而产生报错
4、故障模拟
1) 故障前,向Agent所在机器的log文件,通过管道的形式追加数据,看看event是否轮询的发往了Collector1, Collecotor2
Agent上追加如下数据
Collector1接收并打印到Console的Event (2,4,7)

Collector2接收并打印到Console的Event (1,4,5,6,8)

总结: Flume的round_robin分发,如果是小测试集,分发结果并不是严格的round_robin. 会出现某些节点被分发的次数多,某些节点被分发的次数少的情况
2)模拟故障,将Collector1的进程kill
3)再次在Agent上进行数据追加,查看此时event是否全部分发给Collector2

Collector2此时接收全部event, 并打印到Console

注意1个细节
当Collector1故障的时候,Agent发送event时会提示1个Sink不可用,并尝试下一个Sink进行Event发送

4) 恢复Collector1, 查看Event此时的分发结果
Agent上追加数据

Collector1分发得到的数据

Collector2分发得到的数据

5、负载均衡场景下的官方配置参考

04_Flume多节点load_balance实践的更多相关文章
- 03_Flume多节点Failover实践
1.实践场景 模拟上游Flume Agent在发送event时的故障切换 (failover) 1)初始:上游Agent向active的下游节点Collector1传递event 2)Collecto ...
- 02_Flume1.6.0安装及单节点Agent实践
Flume1.6.0的安装1.上传Flume-1.6.0-tar.gz到待部署的所有机器 以我的为例: /usr/local/src/ 2.解压得到flume文件夹 # tar -x ...
- DG_Oracle DataGuard Primary/Standby物理主备节点安装实践(案例)
2014-09-09 Created By BaoXinjian
- 02_Kafka单节点实践
1.实践场景 开始前的准备条件: 1) 确认各个节点的jdk版本,将jdk升级到和kafka配套的版本(解压既完成安装,修改/etc/profile下的JAVA_HOME,source /etc/pr ...
- 用Nginx做静态文件的CDN
这是上个月一次搭建多个静态文件节点的实践,转载自我的博客,欢迎交流. 鉴于监管环境和网站速度之间的矛盾,目前的网络架构方式如下:1.web动态页面(含数据库)架设在位于美国西海岸的数据中心:2.静态文 ...
- Instagram 架构分析笔记(转)
原文:http://dbanotes.net/?s=Instagram+%E6%9E%B6%E6%9E%84%E5%88%86%E6%9E%90%E7%AC%94%E8%AE%B0 作者:冯大辉 In ...
- 【转载】Instagram架构分析笔记
原文地址:http://chengxu.org/p/401.html Instagram 架构分析笔记 全部 技术博客 Instagram团队上个月才迎来第 7 名员工,是的,7个人的团队.作为 iP ...
- Python菜鸟之路:DOM基础
前言 DOM 是 Document Object Model(文档对象模型)的缩写,定义了访问和操作 HTML 文档的标准方法.DOM把网页和脚本以及其他的编程语言联系了起来.DOM属于浏览器,而不是 ...
- instagram架构分析_转
转自:http://www.eit.name/blog/read.php?504 Instagram 团队上个月才迎来第 7 名员工,是的,7个人的团队.作为 iPhone 上最火爆的图片类工具,in ...
随机推荐
- 002-nginx-在 nginx 反向代理中使用域名,配置动态域名解析
一.概述 代理(proxy),即中间人,它代替客户端发送请求给服务器,收到响应后再转给客户端.通常意义上的代理是从用户的角度讲的,用户通过某个代理可以访问多个网站,这个代理是靠近用户的,比如某些公司可 ...
- orm之路由层
一.简单配置 1.参数 第一个参数是正则表达式(如果要精准匹配:‘^publish/$’),或者加斜杠('^publish/') 第二个参数是视图函数(不要加括号) urlpatterns = [ u ...
- soapUI-JDBC Request
1.1.1 JDBC Requet 1.1.1.1 概述 – JDBC Request Option Description JDBC Request TestStep Toolbar 对JDB ...
- Hive错误:Unable to load native-hadoop library for your platform
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin- ...
- 处理hash冲突
“处理冲突” 的实际含义是: 为产生冲突的地址寻找下一个哈希地址. 1. 开放定址法 2. 链地址法 ------------------------------------------------- ...
- iOS下拉刷新和上拉刷新
在iOS开发中,我们经常要用到下拉刷新和上拉刷新来加载新的数据,当前这也适合分页.iOS原生就带有该方法,下面就iOS自带的下拉刷新方法来简单操作. 上拉刷新 1.在TableView里,一打开软件, ...
- Atcoder Tenka1 Programmer Contest 2019 E - Polynomial Divisors
题意: 给出一个多项式,问有多少个质数\(p\)使得\(p\;|\;f(x)\),不管\(x\)取何值 思路: 首先所有系数的\(gcd\)的质因子都是可以的. 再考虑一个结论,如果在\(\bmod ...
- Java基础语法(基本语句)
Java基础语法 标识符在程序中自定义的一些名称.由26个英文字母大小写,数字:0-9符号:_&组成定义合法标识符规则:1. 数字不可以开头2. 不可以使用关键字Java中 ...
- python 正则表达式匹配ip
>>> re.match(r'^(([1-9]|[1-9]\d|1\d\d|2[0-4]\d|25[0-5])\.){3}([1-9]|[1-9]\d|1\d\d|2[0-4]\d| ...
- nodepad++ 标签栏无法拖放标签
nodepad++ 标签栏无法拖放标签设置--首选项--常用--标签栏--锁定(不允许拖放) 去掉这个勾 ps:最近版本的不知道为什么这个设置不生效了,没找到原因,可能是bug,只能等待升级解决了(升 ...